- The paper presents Florence, a foundation model that integrates multimodal data—from static images to dynamic videos—to achieve high performance in zero-shot and few-shot tasks.
- Its innovative design employs a CoSwin Transformer and unified image-text contrastive learning to balance visual granularity with computational efficiency.
- Florence demonstrates superior performance, achieving 83.74% top-1 accuracy on ImageNet-1K and setting new benchmarks in object detection across multiple datasets.
Florence: A New Foundation Model for Computer Vision
Florence introduces a foundation model tailored for computer vision challenges by bridging various modalities, expanding existing representation capabilities, and achieving impressive performance in numerous benchmarks.
Space-Time-Modality Spectrum
Florence's overarching framework seeks to address the expansive space-time-modality spectrum in computer vision. This entails transitioning representations from static images to dynamic videos and incorporating multiple modalities beyond merely RGB, encompassing textual descriptions, depth maps, and more, aiming to tackle tasks from scene-level classification to fine-grained object detection.
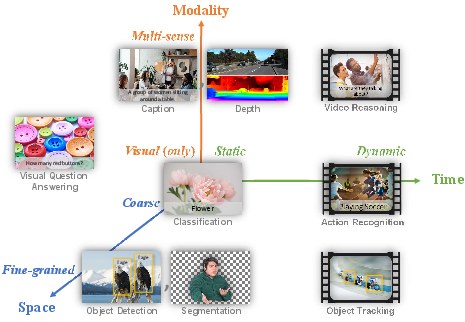
Figure 1: Common computer vision tasks are mapped to a Space-Time-Modality space. A computer vision foundation model should serve as a general-purpose vision system for all of these tasks.
Building Florence
Florence employs a comprehensive workflow that integrates data curation, unified learning objectives, innovative Transformer architectures, and flexible adaptation to downstream tasks. This enables a seamless integration into complex vision systems, capable of handling multimedia applications ranging from object detection to action recognition.
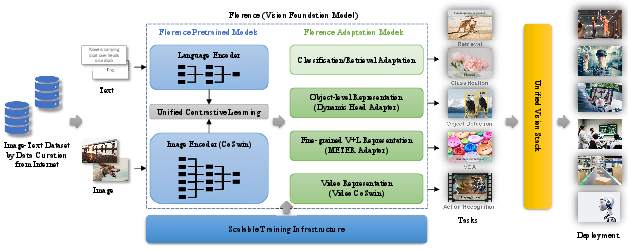
Figure 2: Overview of building Florence. Our workflow consists of data curation, unified learning, Transformer architectures and adaption. It shows the foundation model can be adapted to various downstream tasks and finally integrated into modern computer vision system to power real-world vision and multimedia applications.
Unified Image-Text Contrastive Learning
Florence leverages a two-tower architecture with distinct encoders for images and text, promoting effective multimodal representation learning. Utilizing the UniCL framework, Florence enhances learning by equating the image-text pairings with positive associations within a shared embedding space, thereby accommodating the rich, diverse data from web sources.
The core of Florence's architectural prowess is its hierarchical Vision Transformer, CoSwin, which optimizes for scale-invariant image properties and computational efficiency. By integrating convolutional mechanisms into its structure, CoSwin achieves an intuitive balance between visual granularity and attention-based learning, critical for tasks requiring dense spatial understanding.
Florence demonstrates robust performance across a series of vision benchmarks, including zero-shot and few-shot learning paradigms, showcasing superior accuracy and adaptability in image and video recognition tasks.
- Zero-shot classification: Florence achieves 83.74% top-1 accuracy in ImageNet-1K, outperforming leading models by a significant margin.
- Object detection: Utilizing Dynamic Head adaption, it not only sets new state-of-the-art benchmarks in datasets like COCO and Object365 but also exhibits strong zero-shot object detection capabilities, highlighting its potential in understanding novel and diverse scenarios.

Figure 3: Our fine-tuned detection results on COCO (sparse object boxes), Object365 (dense object boxes), Visual Genome (w/ object attributes), and zero-shot transfer results on 11 downstream detection tasks. Boxes with different colors denote different object categories.
Scalable Training Infrastructure
To facilitate learning at such scales, Florence employs multiple techniques: ZeRO optimization, activation checkpointing, and gradient caching. This reduces computational overhead on GPUs, allowing for larger batch-size training and hence more performant model updates.

Figure 4: GPU memory reduction for various batch sizes. We compared the profiling between Torch (w/o optimization) and Florence (w/ optimization) on various numbers of GPUs.
Conclusion
Florence represents a significant advancement in creating a multi-purpose foundation model for computer vision, enabling efficient, scalable, and versatile application across a spectrum of challenges. Its design principles lay the groundwork for future models in integrative AI systems that aim to be foundational to human-like visual understanding and interaction. Future directions involve further expanding its modality support and improving zero-shot task applications.