- The paper demonstrates that adapter-based tuning outperforms full fine-tuning in low-resource settings by reducing trainable parameters while maintaining robust performance.
- It introduces lightweight adapter modules within transformer layers to mitigate overfitting and preserve pretrained model knowledge through controlled parameter updates.
- Empirical results reveal improved metrics like micro-F1 and macro-F1, along with enhanced training stability and better regularization compared to conventional fine-tuning.
A Detailed Analysis on "On the Effectiveness of Adapter-based Tuning for Pretrained LLM Adaptation"
This essay examines the methodologies and findings from the paper titled "On the Effectiveness of Adapter-based Tuning for Pretrained LLM Adaptation" (2106.03164), with a focus on practical and theoretical implications of the research.
Introduction
Adapter-based tuning is introduced as a parameter-efficient alternative to traditional fine-tuning of large-scale pretrained LLMs (PrLMs), such as BERT and RoBERTa. This approach integrates minimalistic adapter modules within existing transformer layer architectures and only updates these new parameters rather than the entire model, offering significant parameter savings. While prior research into adapters concentrated on their efficiency in parameter sharing, this study investigates the comparative effectiveness of adapter-based tuning versus fine-tuning for various NLP tasks, with a focus on regularization and adaptational performance.
In their work, the authors present empirical evidence of two significant advantages of adapter-based tuning over fine-tuning:
- Superior performance in both low-resource and cross-lingual NLP tasks.
- Enhanced robustness against overfitting and variability in learning rates.
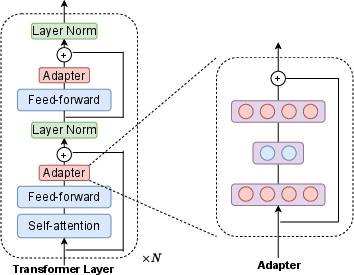
Figure 1: The structure of the adapter adopted from Houlsby et al. (2019).
Adapter Architecture and Methodology
Adapter-based tuning involves inserting lightweight neural network modules, specifically designed as transformations in between transformer layers of a pre-trained model, while these adapters alone are updated when training is performed on downstream tasks. The research builds on work that initially aimed at improving parameter efficiency but now demonstrates the advantage of adapters in reducing catastrophic forgetting, as evidenced by the Representational Similarity Analysis (RSA).
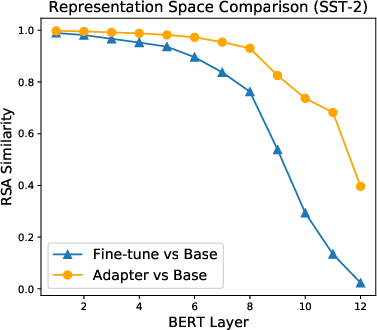
Figure 2: Comparison of the representations obtained at each layer before (Base) and after adapter-based tuning or fine-tuning on BERT-base using Representational Similarity Analysis (RSA). 5000 tokens are randomly sampled from the dev set for computing RSA. A higher score indicates that the representation spaces before and after tuning are more similar.
Monolingual Adaptation
In investigations using the TAE and GLUE datasets, the paper established that adapter-based tuning exhibited distinct advantages, particularly in low-resource settings. It consistently surpassed fine-tuning in low-resource tasks, improving performance metrics such as micro-F1 and macro-F1 scores by an average of 1.9% across select datasets (Table 1). This advantage was pronounced in domain-specific tasks with limited training examples.
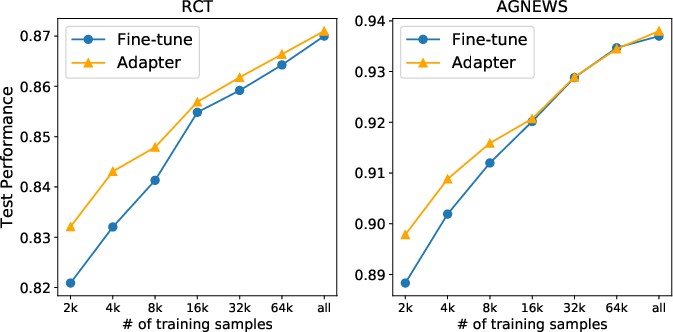
Figure 3: Test performance w.r.t. the number of training examples. Reported results are averages across five runs with different random seeds.
When increasing the amount of training data in high-resource tasks, fine-tuning gradually matched adapter-based tuning, suggesting that adapter-based tuning is especially effective in avoiding overfitting when data is sparse.
Figure 3: Test performance with respect to the number of training examples. Reported results are averages across five runs with different random seeds.
Cross-lingual and Low-Resource Adaptation
The paper extends its assessment to the cross-lingual setting, using tasks from the XTREME benchmark to compare conventional and adapter-based tuning methods. The experiments demonstrated that adapter-based tuning generally outperforms fine-tuning across diverse languages and tasks, with particular efficacy noted under zero-shot cross-lingual scenarios.
In constraints of training data, such as on 5% and 10% subsets of the XNLI training data, adapter-based tuning exemplified consistent superior performance over fine-tuning. This suggests that adapter-based tuning has the potential to better capture and generalize learned representations across languages distinct from those included in the initial PrLM while maintaining robustness under varying training conditions.
Representation Regularization through Adapters
The research reveals that adapter-based tuning enhances training regularization by reducing representation drift from the initial PrLM. Using RSA, the authors showed that adapter-based tuning results in representation changes typically confined to the top layers of BERT, which indicates improved retention of base model knowledge as compared to fine-tuning. This is an important distinction, as retention is critical for various NLP tasks where existing pretrained knowledge should not be entirely overwritten.
Figure 2: Comparison of representation similarity at each layer before and after adapter-based tuning or fine-tuning on BERT-base using Representational Similarity Analysis (RSA).
Monolingual Adaptation
Low-Resource Tasks
Investigations in low-resource monolingual contexts revealed that adapter-based tuning achieves a performance advantage of 1.9% on average over fine-tuning in TAE tasks. This finding was consistent even without task-adaptive pretraining, highlighting its capability to work effectively under both supervised and unsupervised learning schemes.
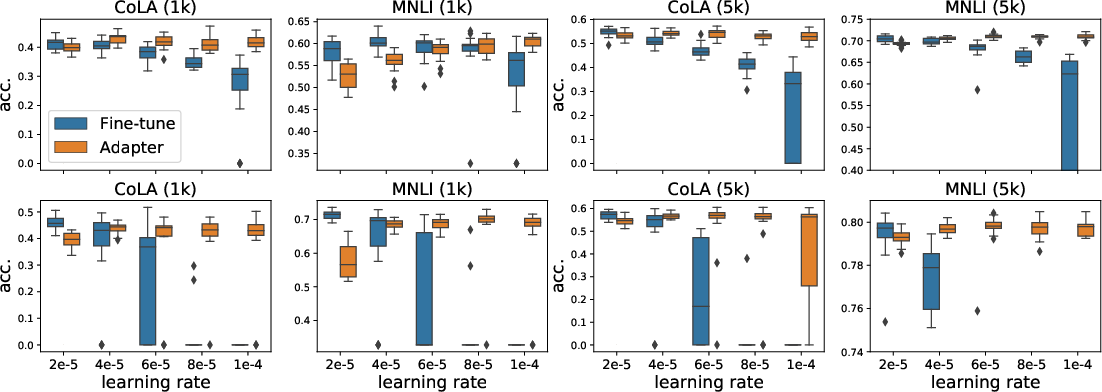
Figure 4: Box plots of test performance distribution over 20 runs across different learning rates, emphasizing the stability of adapter-based tuning over BERT-base and RoBERTa-base models under different learning rates.
When evaluating on the GLUE low-resource benchmark tasks with varying training sample sizes, the study noted robust performance of adapter-based tuning. This approach outshined fine-tuning, especially prevalent in scarce data and domain-specific tasks.
Cross-Lingual Adaptation
In cross-lingual adaptation experiments using XLM-R-large, adapter-based tuning demonstrated statistically significant performance improvements over fine-tuning across various tasks, including UD-POS, Wikiann NER, and XNLI, showing enhancements by as much as 3.71% on certain distantly related languages.
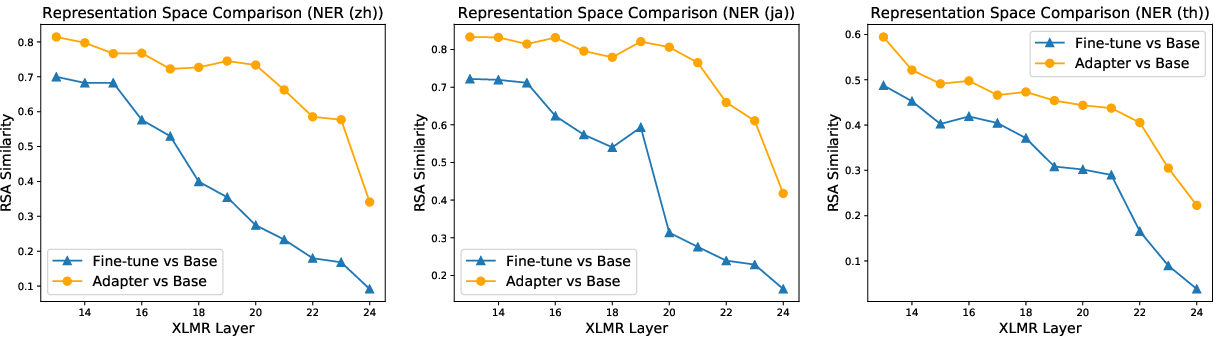
Figure 5: Comparison of representational similarity scores for layers before and after adapter-based tuning on XLMR-large.
This signifies that adapter-based tuning effectively utilizes pre-trained language knowledge in zero-shot cross-lingual scenarios by alleviating catastrophic forgetting, thereby maintaining robustness in performance despite limited task data.
Analysis of Training Stability and Generalization
The paper emphasizes that adapter-based tuning provides higher model training stability and improved generalization, displaying reduced sensitivity to varying learning rates and training size variations.
Figure 4: Box plots of test performance distribution over 20 runs across different learning rates. The upper/bottom results are based on Bert-base/RoBERETa-base.
Through loss landscape visualization, it is evidenced that adapter-based tuned models settle into more stable and generalized minimas compared to the sharp convergence of fully fine-tuned models. These findings indicate that adapter-based tuning offers better resilience against overfitting, especially in low-resource training conditions.
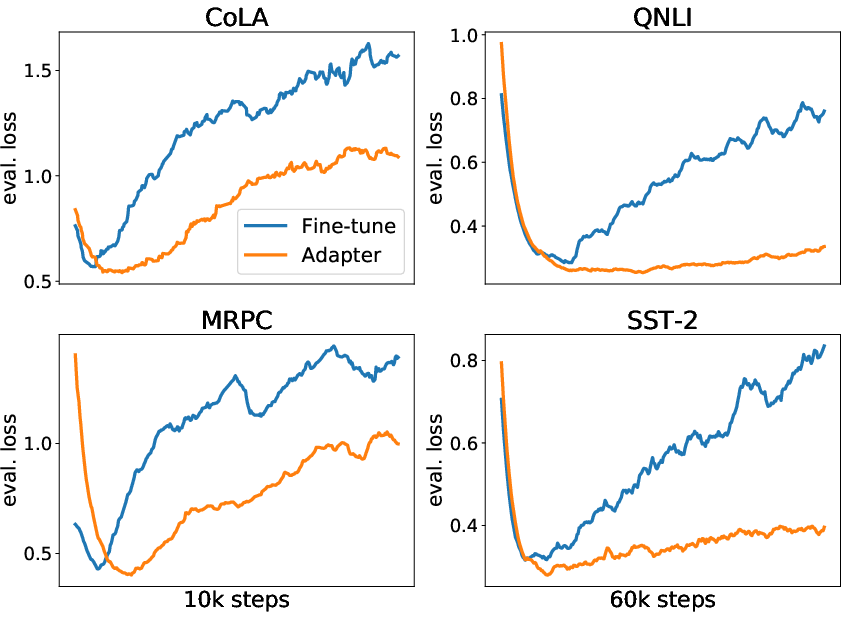
Figure 6: Loss on the dev set w.r.t. training steps. Results are based on BERT-base. The original training and dev sets from GLUE are used for this analysis.
We observe that adapter-based tuning shows a consistent ability to maintain task-invariant knowledge by producing similar representation spaces (Base vs Adapter versus Base) as shown (Figure 7).
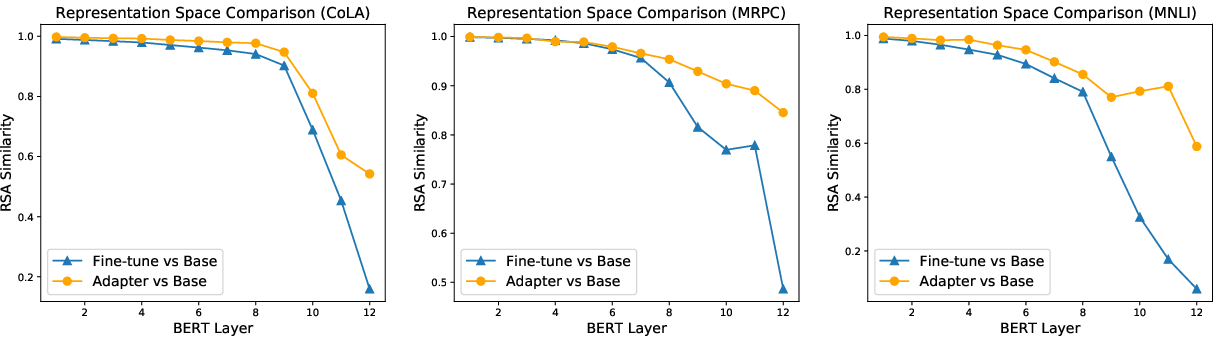
Figure 7: Comparison of the representations obtained at each layer before (Base) and after adapter-based tuning or fine-tuning on BERT-base using Representational Similarity Analysis (RSA).
Conclusion
This paper contributes an empirical evaluation of adapter-based tuning for PrLM adaptation in NLP tasks, contrasting its efficacy with traditional fine-tuning methods. The results affirm that adapter-based tuning is highly parameter efficient and excels in domains with sparse data and low-resource settings, providing observed performance gains over fine-tuning. Additionally, its potential to mitigate catastrophic forgetting presents significant benefits, particularly in maintaining stable training and improved generalization. Future research may explore further refining adapter architectures and their application to more generalized NLP tasks, leveraging their unique capabilities for partial model updates esclusively. Such investigations could extend the utility of adapter-based methods in even more diverse and complex domains.

