- The paper finds that network capacity is underutilized in distributed training, with scaling factors of 60-76% observed when using 64 GPUs.
- It employs detailed profiling on AWS with PyTorch and Horovod, revealing low network and CPU utilization even at 100 Gbps bandwidth.
- The study advocates shifting focus to network transport protocol optimizations, which could potentially achieve near-linear scaling up to 99%.
Summary of "Is Network the Bottleneck of Distributed Training?"
The study in "Is Network the Bottleneck of Distributed Training?" investigates the role of network capacity in distributed deep learning systems by analyzing whether network limitations obstruct linear scalability. It postulates that, despite widespread assumptions, the network is not the primary bottleneck for scaling distributed training. The research advocates for focusing on enhancing network transport efficiency over application-layer optimization strategies like gradient compression.
Key Findings
The paper establishes that current distributed training frameworks, specifically Horovod, reach a maximum scaling factor of approximately 60-76% when employed with 64 GPUs under optimal network configurations. However, the study reveals that this network underutilization is not synonymous with performance limitations due to bandwidth shortages.
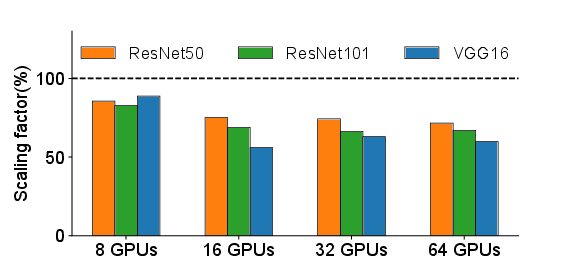
Figure 1: Scaling factor vs. number of servers involved.
Profiling and Analysis
Through a detailed profiling of distributed training on AWS infrastructure using PyTorch and Horovod, the research indicates that merely enhancing network speed does not proportionally improve performance. Although communication phases in distributed training tend to bog down scaling, the network itself operates at a low utilization rate even at available 100 Gbps bandwidth.
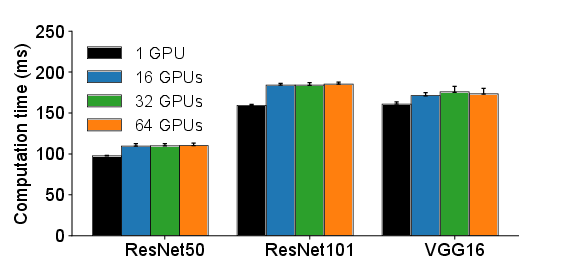
Figure 2: Computation time vs. number of servers.
Alternative Bottlenecks
Contrary to common beliefs, the paper postulates that neither network bandwidth nor CPU utilization acts as prevailing bottlenecks in the experimental settings. The findings are derived from measuring network and CPU utilization, revealing active bandwidth usage well below capacity and nominal CPU usage during high-intensity operations.
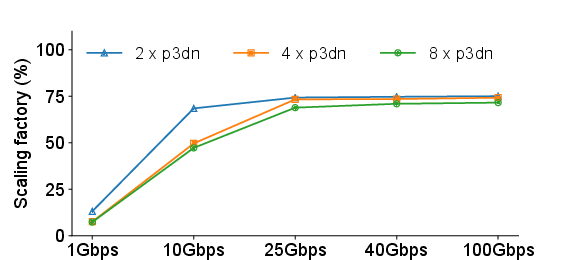
Figure 3: Scaling factor change with bandwidth (ResNet50).
What-If Analysis
The exploration further performs a "what-if” analysis to simulate conditions of perfect network utilization. It reveals that if the network were adequately optimized, distributed training could achieve scaling factors nearing 99%, diminishing the perceived need for application-level gradient compression strategies.
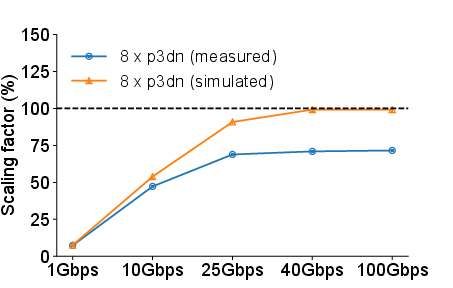
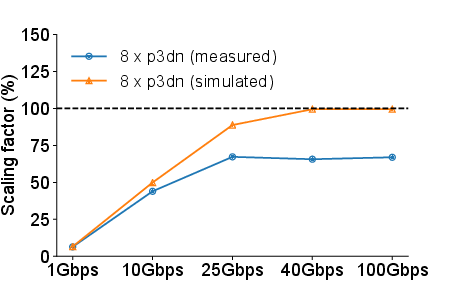
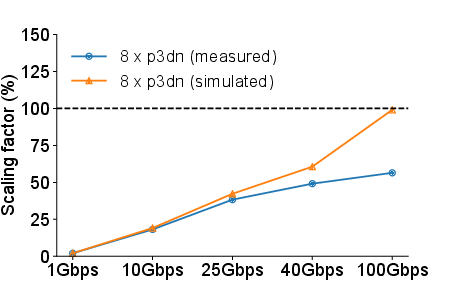
Figure 4: Simulated scaling factor vs measured scaling factor in different bandwidth.
Implications and Future Directions
Shift in Optimization Focus
The study underscores the potential of network-layer optimizations to facilitate significant improvements in distributed training throughput without a loss of model performance or added complexity. It advocates shifting focus away from application-layer optimizations like gradient compression—unless dealing with low-bandwidth environments—and instead calls for the design of proficient network transport protocols.
Broader Impact
This research emphasizes the crucial role of streamlined network interaction in distributed AI systems, inviting advancements towards kernel-bypass technologies and high-performance network transport systems that can fully exploit the bandwidth of modern high-speed networks.
Conclusion
"Is Network the Bottleneck of Distributed Training?" establishes a clear narrative that the inefficiencies in distributed training are primarily due to suboptimal network transport implementations rather than inherent bandwidth limitations. It stresses the potential gains from harnessing high-performance network technologies that better utilize existing network infrastructure, pushing towards nearly linear scalability in distributed deep learning frameworks.