- The paper identifies high performance instability in NLP models caused by inter-example correlations, challenging current evaluation practices.
- It employs theoretical analysis and empirical evaluations, including correlation heatmaps, to decompose variance into individual and covariance components.
- The study recommends short-term comprehensive variance reporting and long-term improvements such as dataset diversification and robust model design.
This essay provides a detailed exploration of performance instability in contemporary NLP models, focusing on Natural Language Inference (NLI) and Reading Comprehension (RC) tasks. The primary goal is to understand the implications of instabilities in auxiliary datasets and provide potential strategies to handle such issues.
This investigation reveals that modern NLP models, notably BERT, RoBERTa, and XLNet, exhibit significant performance variance across analysis datasets, unlike their stable performance on standard datasets like MNLI-m and SNLI. The authors argue that this instability raises questions about the reliability and generalizability of conclusions derived from these datasets.
Figure 1 is presented to illustrate the variance in performance trajectory for BERT across different datasets, highlighting the notable instability in analysis sets such as HANS and various Stress Test subsets.
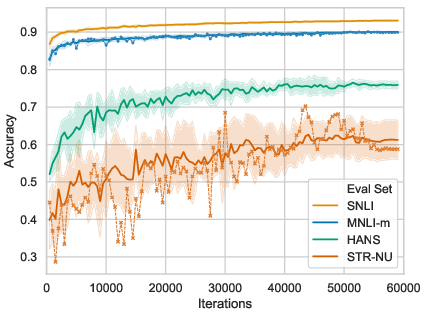
Figure 1: The trajectories of BERT performance on SNLI, MNLI-m, HANS highlighting different levels of performance stability.
Source of Instability
The paper postulates that high inter-example correlations within analysis datasets induce instability. This conclusion is supported by both theoretical analysis and empirical data. The authors decompose performance variance into two components: the variance due to individual example prediction and the variance attributed to inter-example correlations.
Figure 2 shows heatmaps of correlation matrices for MNLI and HANS, clearly indicating stronger correlations among examples in HANS.
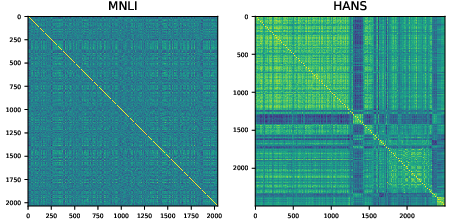
Figure 2: The heatmaps of inter-example correlations for MNLI and HANS datasets.
Mitigating Instability
The authors suggest strategies for managing performance instability. Short-term measures include comprehensive variance reporting, emphasizing the independent and inter-example covariance components. The authors argue that such reporting can improve model evaluation and interpretation.
In the long-term, efforts should target enhancing both models and datasets. Researchers are encouraged to construct more diverse datasets and design models with robust inductive biases. Model architectures should aim to capture linguistic phenomena more stably while reducing reliance on patterns that inadvertently cause high variance.
Implications for Model and Dataset Design
The paper emphasizes that while synthetic datasets are valuable for probing specific phenomena, their construction might lead to lower syntactic and lexical diversity, exacerbating instability. Yet, these datasets remain vital tools in debuggings models, provided their limitations are acknowledged in the analysis.
Figure 3 illustrates the variance of model performance across various datasets under different seeds, underscoring the inconsistency in synthetic datasets as opposed to standard benchmark sets.
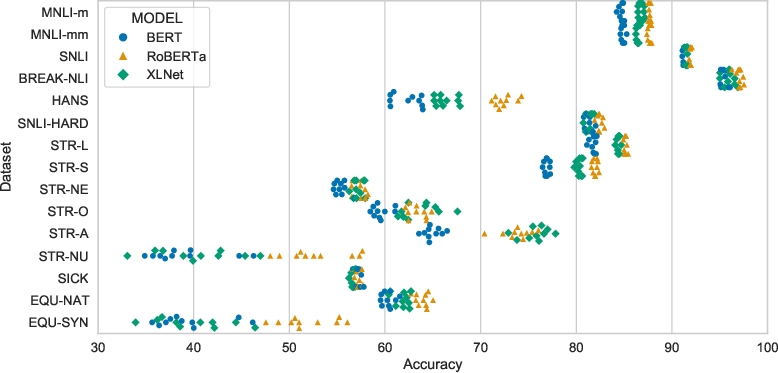
Figure 3: The results of BERT, RoBERTa, and XLNet on all datasets emphasizing variance in specific analysis datasets.
Conclusion
The examination underscores a prevalent issue of performance instability in auxiliary datasets, mainly driven by high inter-example prediction correlations. This instability challenges the reliability of conclusions drawn from current analysis practices. The paper provides a balanced view of short-term and long-term approaches for grappling with performance instability, advocating for improved reporting and dataset diversity enhancement. Moving forward, greater emphasis on variance decomposition in performance reporting and dataset design will be crucial in refining model evaluation processes for NLP tasks.