- The paper introduces a novel hybrid MPC method by interleaving cross-entropy sampling with gradient descent to achieve faster convergence in high-dimensional action spaces.
- The methodology refines Gaussian-sampled action sequences with gradient updates, effectively balancing exploration and exploitation to avoid local optima.
- Experimental results in both toy and real-world simulations demonstrate that the hybrid approach outperforms standalone CEM in terms of reward acquisition and convergence speed.
Model-Predictive Control via Cross-Entropy and Gradient-Based Optimization
Introduction
The paper "Model-Predictive Control via Cross-Entropy and Gradient-Based Optimization" (2004.08763) addresses the challenge of planning action sequences in high-dimensional model-predictive control (MPC) and model-based reinforcement learning (MBRL). Traditional approaches often rely on the Cross-Entropy Method (CEM), a population-based heuristic that iteratively refines a Gaussian distribution to optimize action sequences. However, CEM's inefficiency becomes pronounced in high-dimensional action spaces, where gradient descent offers faster convergence by leveraging inexpensive model gradients. This research interleaves CEM with gradient descent to improve convergence and avoid local optima, demonstrating superior performance compared to CEM alone.
Methodology
The proposed hybrid approach combines the broad search capabilities of CEM with the rapid convergence of gradient-based methods. CEM samples action sequences from a Gaussian distribution and refines the distribution based on the top-performing sequences. Gradient descent further optimizes these sequences based on cumulative reward gradients.
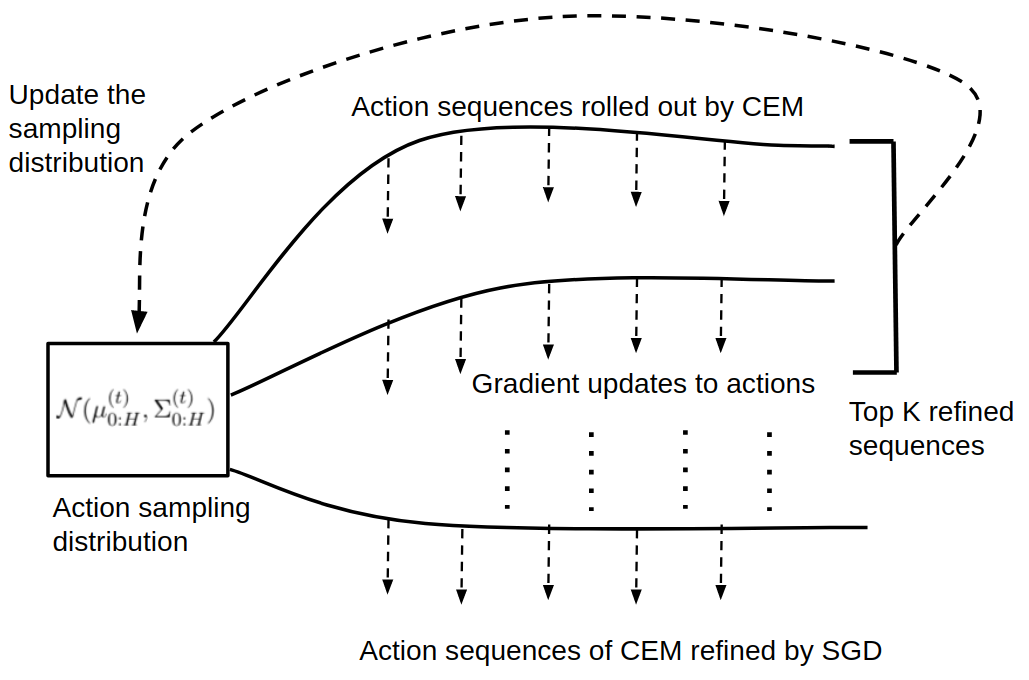
Figure 1: Schematic of the proposed approach. Initial sequences of actions sampled from the CEM sampling distribution are refined by a few gradient descent updates, denoted by downward arrows.
The methodology involves initializing a Gaussian distribution, sampling multiple action sequences, and evaluating their cumulative rewards using learned dynamics and reward models. After gradient descent refinement, the distribution is updated to favor high-reward sequences. This process is iteratively repeated, balancing exploration (via random samples) and exploitation (via gradient descent).
Experiments and Results
The experiments conducted evaluated the efficacy of the hybrid approach compared to standalone CEM and gradient-based planners. A toy environment was used to isolate the planning problem, demonstrating superior performance in higher-dimensional action spaces.
- High Configurations: The experiments showed a substantial performance drop in CEM's efficacy as action dimensionality increased, while the hybrid approach consistently outperformed, exploiting rich gradient signals for optimization. The hybrid planner maintained high efficiency across dimensions due to gradient incorporation.
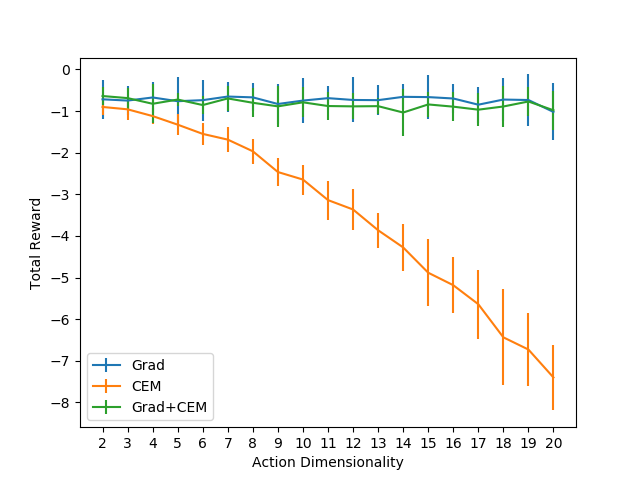
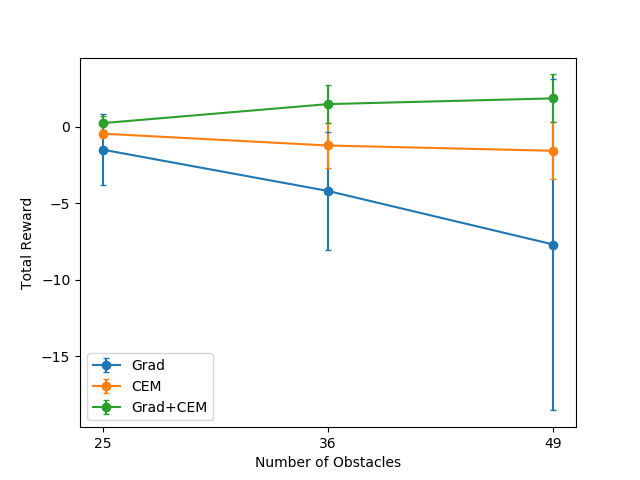
Figure 2: Total reward obtained by CEM vs Grad vs Grad+CEM planners on the toy environment, averaged over 50 runs.
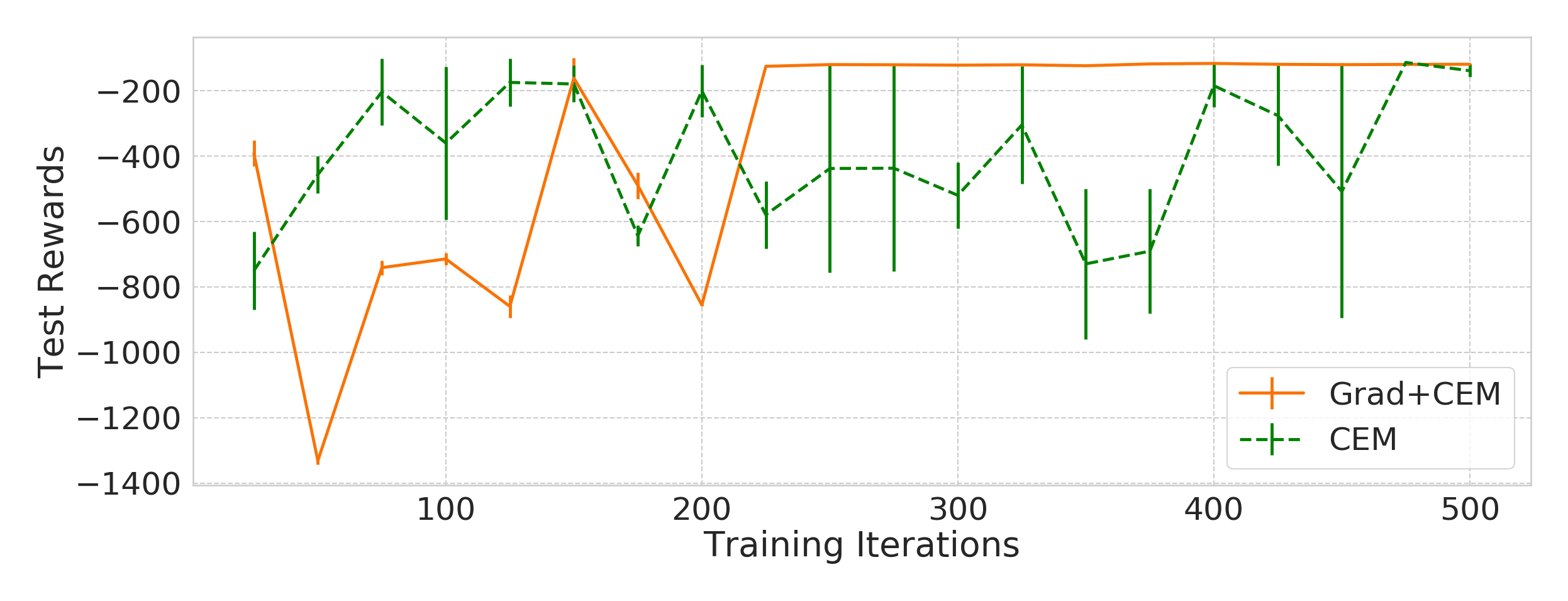
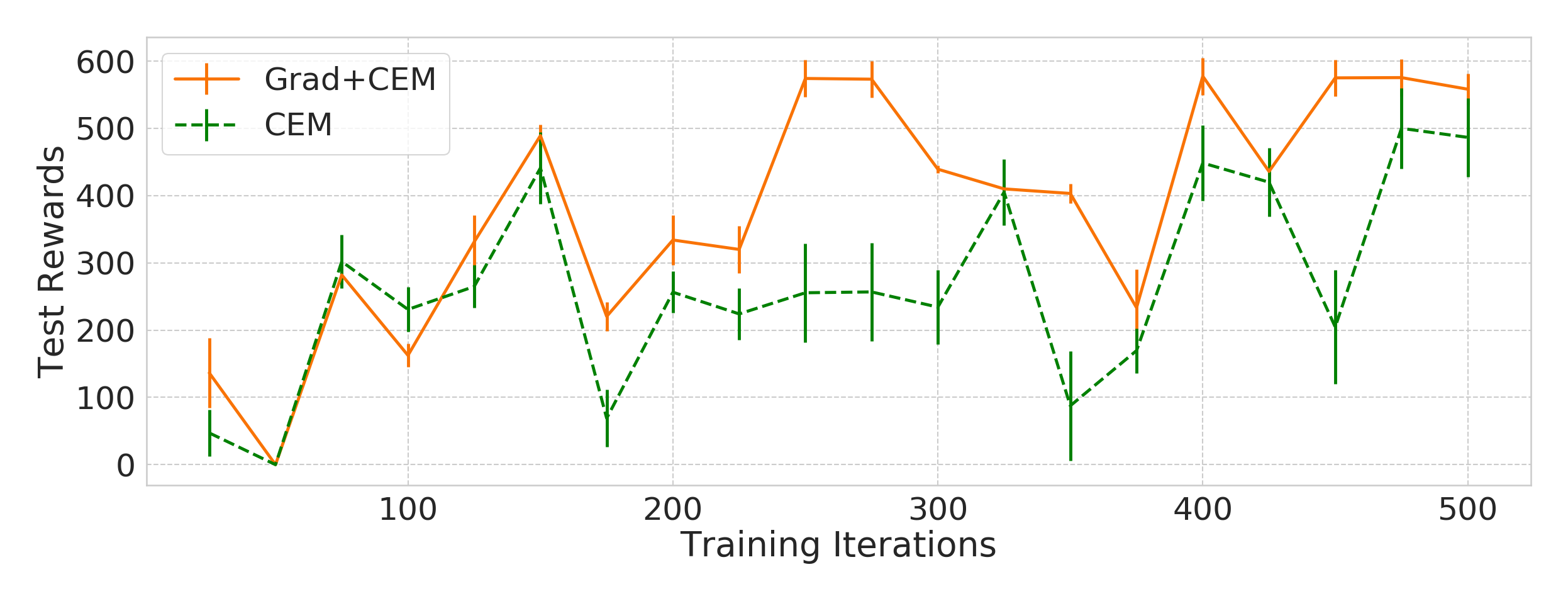
Figure 4: Variation of rewards at test time during the course of training. OpenAI Gym Pendulum and Half-Cheetah environments.
Implications and Future Directions
The interleaving of CEM with gradient descent represents an effective planning paradigm, showcasing its utility in high-dimensional continuous control problems. This hybrid method alleviates the exploratory limitations of traditional CEM by utilizing gradient signals to accelerate convergence and enhance performance in complex environments.
Future research may explore improving model accuracy to mitigate model-bias issues, refining latent variable models for planning, and scaling ensemble-based approaches to further enhance the planning under uncertainty. The exploration of latent skill-conditioned dynamics models presents promising avenues for future development by leveraging latent abstractions for planning.
Conclusion
This research introduces a novel hybrid optimization scheme for model-predictive control, effectively interleaving gradient-based refinement with CEM's broad search approach. Demonstrating superior scalability and convergence speed in high-dimensional settings, this method promises enhanced performance in real-world control problems, effectively merging the strengths of gradient-based and stochastic planning paradigms.