- The paper introduces a novel verification approach using IBP to certify NLP model robustness against adversarial symbol substitutions.
- It employs interval arithmetic to propagate activation bounds efficiently, achieving over 100x speed improvements compared to exhaustive methods.
- Experimental results on the SST and AG News datasets demonstrate enhanced adversarial accuracy and robust performance over traditional training.
Achieving Verified Robustness to Symbol Substitutions via Interval Bound Propagation
Introduction
"Achieving Verified Robustness to Symbol Substitutions via Interval Bound Propagation" addresses the challenge of providing formal guarantees of robustness for NLP models against adversarial attacks such as synonym replacements or character perturbations. Neural networks, particularly in NLP systems, are prone to adversarial attacks that induce significant changes in output predictions through seemingly minor input modifications. Conventional mitigations such as adversarial training and data augmentation lack effective assurances against the worst adversaries due to the complexity of the discrete search space.
This paper proposes a verification approach using Interval Bound Propagation (IBP) to compute robustness guarantees efficiently. Unlike typical training that might inadvertently lead to significant model vulnerabilities, this method offers provable certification against input perturbations by structuring these perturbations as simplices.
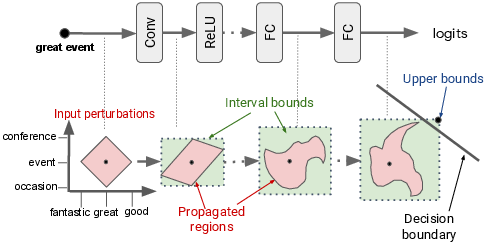
Figure 1: Illustration of verification with the input simplex and Interval Bound Propagation.
Verification Methodology
The proposed technique models input perturbations as simplices within the embedding space. By employing IBP, the authors compute bounds on model layers' activations, facilitating the efficient verification of adversarial robustness. This approach ensures that models uphold prediction consistency despite perturbations within specified constraints. Specifically, the approach leverages interval arithmetic to propagate bounds through layers, enabling the calculation of an upper bound for worst-case scenarios without exhaustive input enumeration.
The formulated verification challenges involve optimization to ensure that alternate character or synonym substitutions do not alter model predictions. An auxiliary objective derived from these bounds during training further enhances the models' verifiability without debilitating their predictive accuracy.
Interval Bound Propagation in Action
IBP is utilized to enhance model training, extending the robustness of NLP models while preserving efficiencies. The mechanism constructs a convex hull for input perturbations, broadening initial input bounds, thus computing a viable yet conservative over-approximation of potential adversarial spaces. Through interval propagation, such robustness outcomes are over one hundred times more time-efficient than traditional exhaustive verification methods.
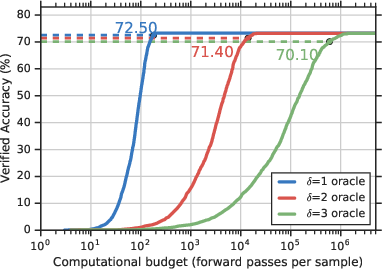
Figure 2: Verified accuracy vs. computation budget confirming IBP efficiency over exhaustive search on SST data.
Experimental Evaluation
Results gathered from SST and AG News datasets elucidate the viability of IBP in rendering models that resist adversarial perturbations. The models trained under IBP constraints display improved adversarial accuracy and robust performance metrics against vanilla and augmented training counterparts. Notably, when embedded with counter-fitted vectors, as exhibited in experimental word-level analyses, models demonstrate substantial robustness increases.
Implications and Future Research
The insights drawn depict IBP as a potent verifiable strategy within NLP contexts, notably overcoming the intrinsic limitations associated with neural network depth and type by tightening verification bounds and expanding model architectures. Future research could explore optimizing these bounds for deeper networks, incorporating them into recurrent and attention-based models, and broadening specification scopes for encompassing other adversarial paradigms.
Conclusion
This paper propounds the practical merits of implementing verifiable models within NLP using IBP, underscoring its efficacy in fortifying models against character and synonym perturbations. Through comprehensive experiments and evaluations, the research confirms the practicality and efficiency of IBP in verifying robustness, offering a significant leap towards deploying reliable and secure NLP systems against adversarial exploits.