- The paper reveals that only a small subset of attention heads is crucial for translation, enabling up to 80% head pruning with minimal BLEU score degradation.
- It employs layer-wise relevance propagation and a differentiable L0 penalty to quantify and eliminate redundant heads without sacrificing performance.
- The findings highlight specialized roles—positional, syntactic, and rare word-focused—that guide efficient model design and resource optimization.
Introduction
This essay examines the pivotal roles of specialized attention heads within the Transformer architecture, emphasizing that only a few heads are critical for maintaining translation quality, with others being redundant and suitable for pruning. The study investigates the contribution of individual attention heads, identifying the roles through techniques such as layer-wise relevance propagation (LRP) and proposing a novel pruning method to reduce model complexity without significantly affecting performance.
The Transformer model [Vaswani et al., 2017] employs an encoder-decoder structure utilizing multi-head self-attention and feed-forward layers. Each attention head processes different representations of query, key, and value vectors, enabling the model to focus on different parts of the input sequence. This multi-head mechanism augments model capacity and improves performance over single-head variants. The study at hand primarily focuses on the encoder self-attention heads, exploring their individual contributions and specialized roles within the transformation process.
Identifying Important Heads
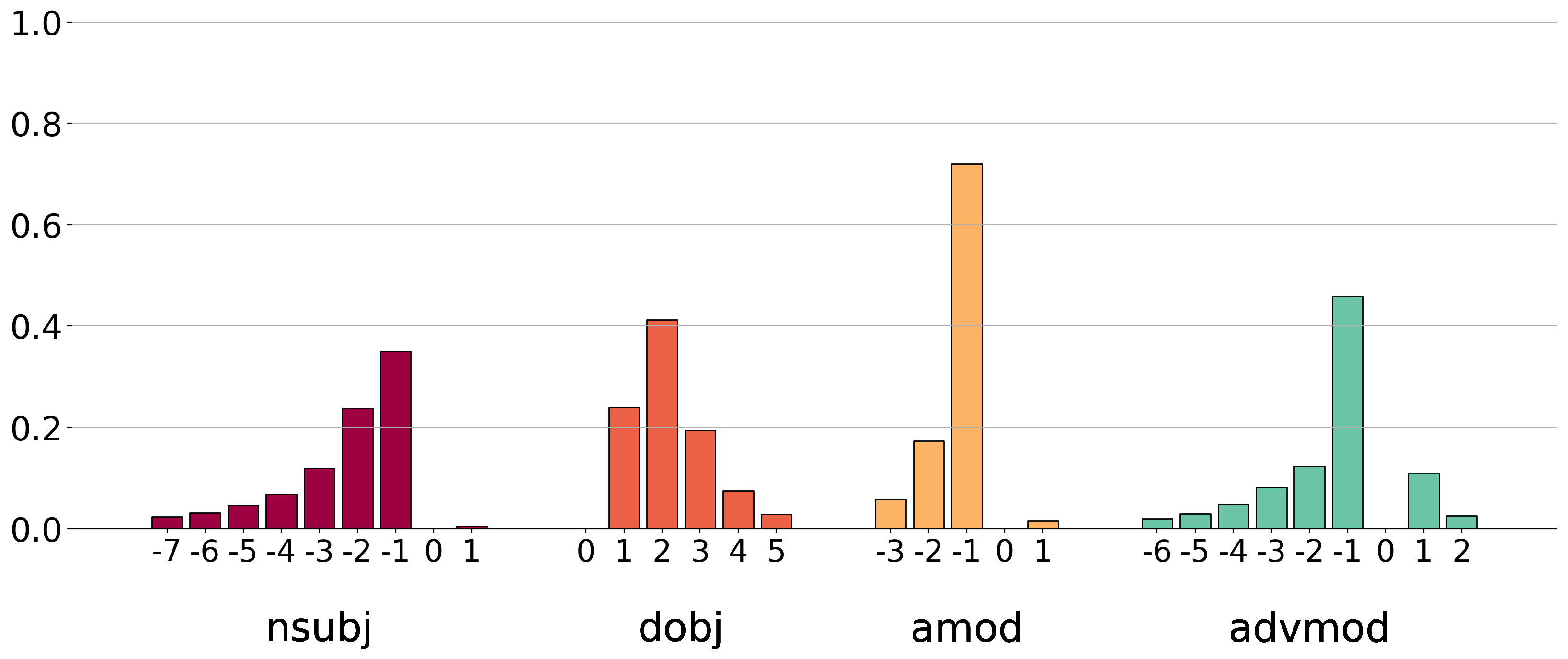
Attention heads' importance is evaluated using LRP, which computes relevances indicating how much each head contributes to the prediction output. Figures such as (Figure 1: LRP) demonstrate that only a few heads exhibit significant contribution, while the majority are minimally impactful. These findings are consistent with the hypothesis that certain heads specialize in roles such as positional and syntactic attention, thereby dominating the translation task's efficacy.
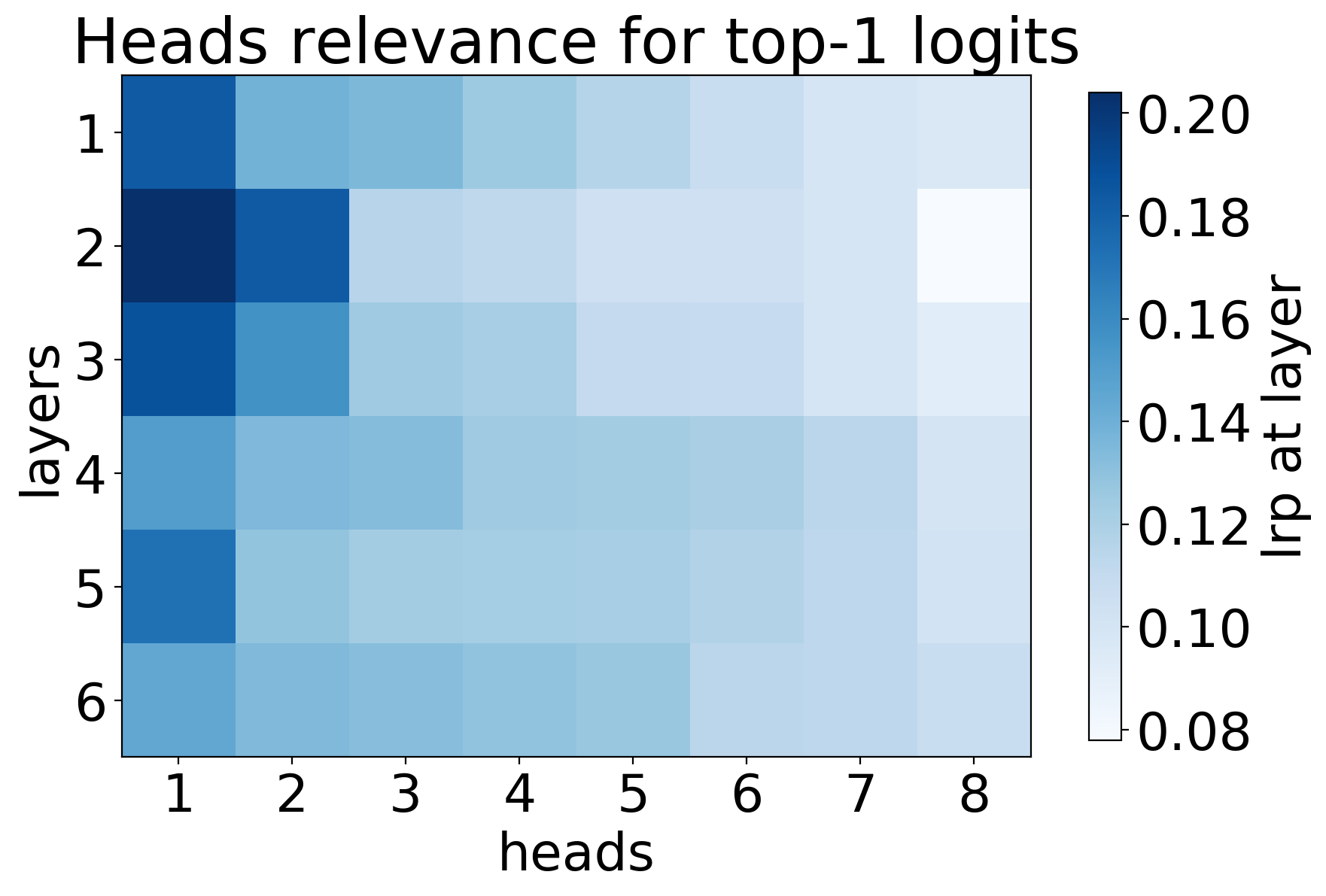
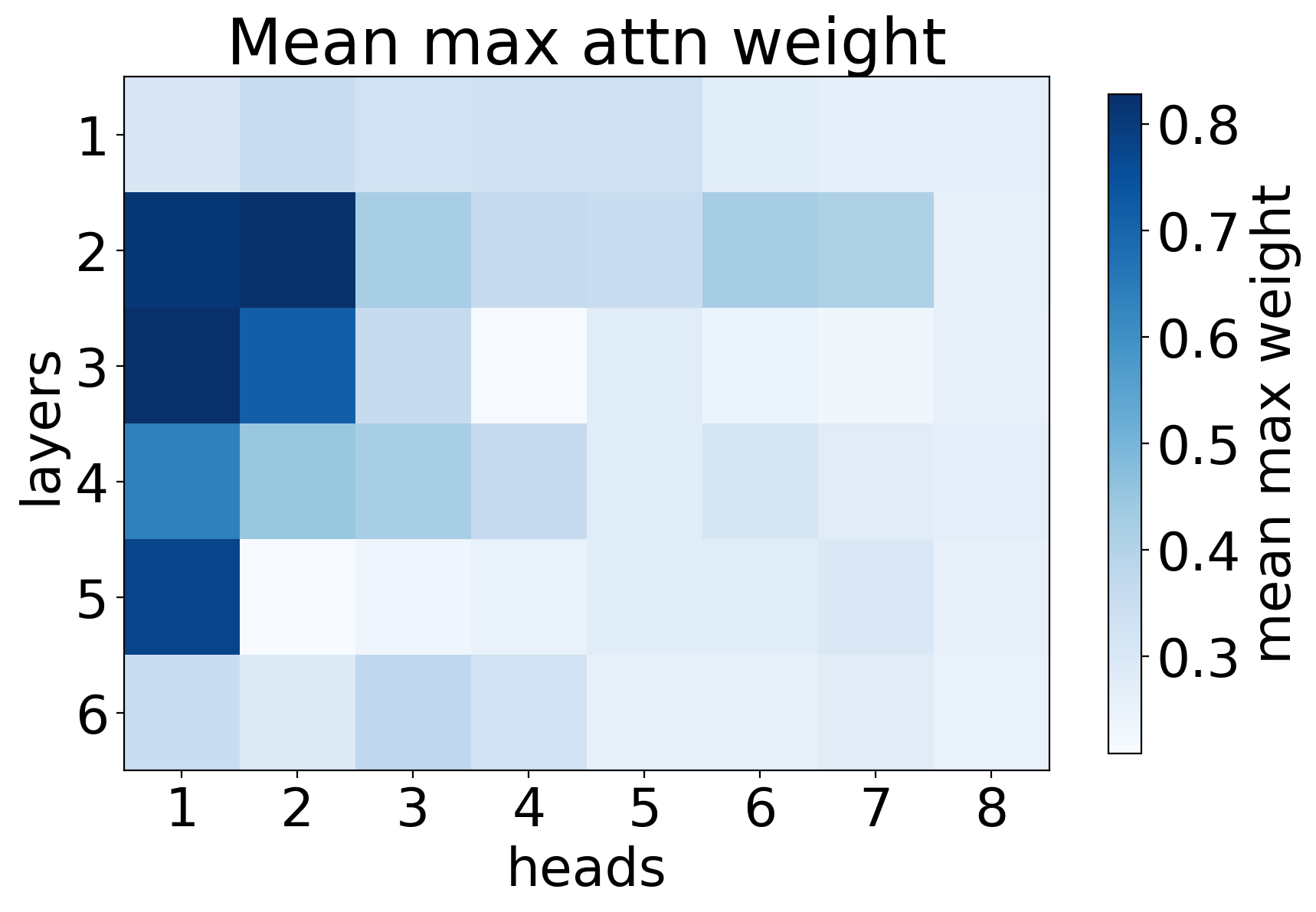
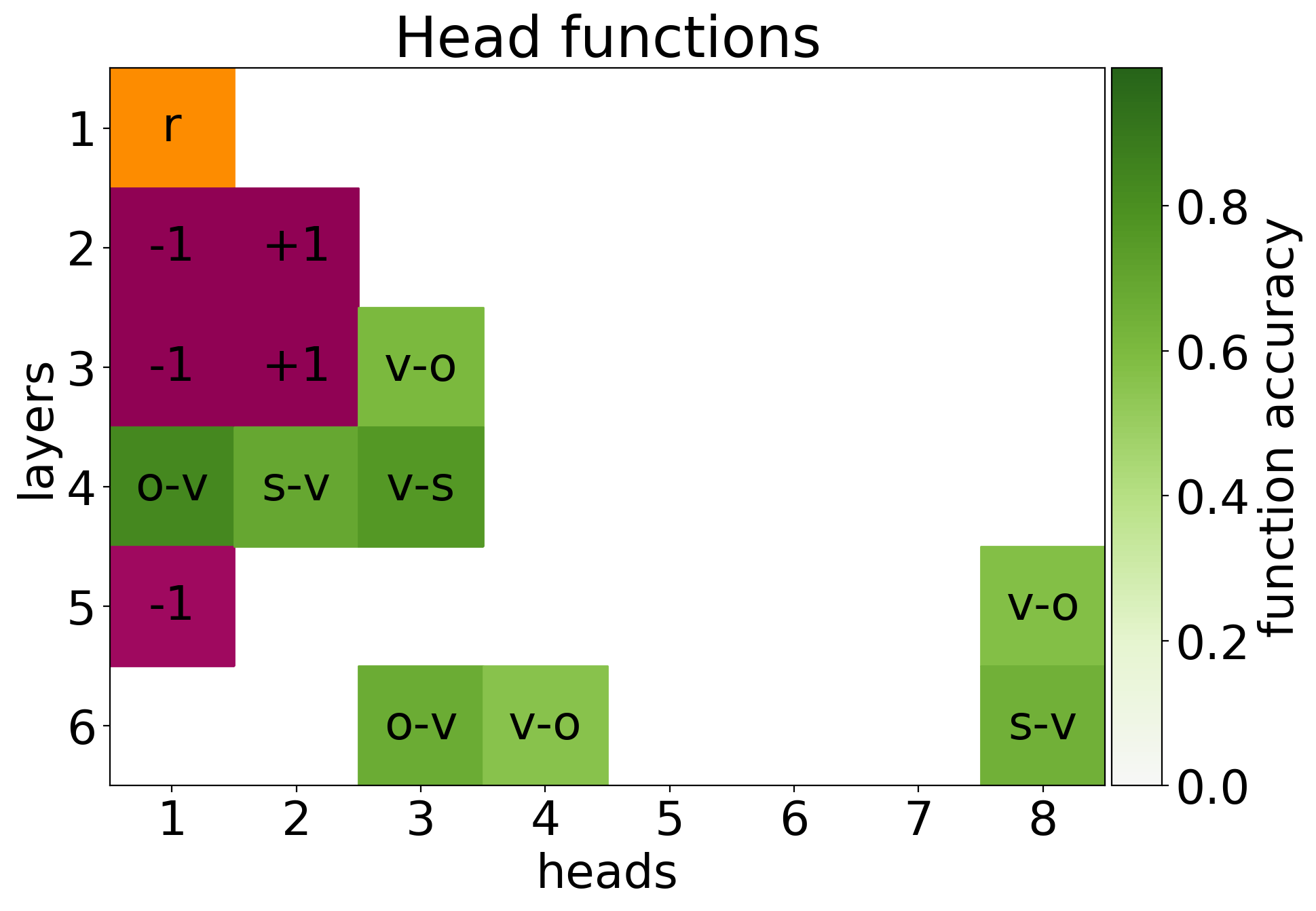
Figure 1: LRP shows the significant importance of selected attention heads over others.
Characterizing Specialized Roles of Attention Heads
The study identifies specialization within attention heads into three main roles:
The authors propose a pruning strategy using stochastic gates and a differentiable approximation of the L0 penalty to reduce model size while maintaining performance. Experimental results indicate that pruning encoder heads can remove up to 80% of heads with negligible BLEU score degradation, as highlighted in (Figure 3).
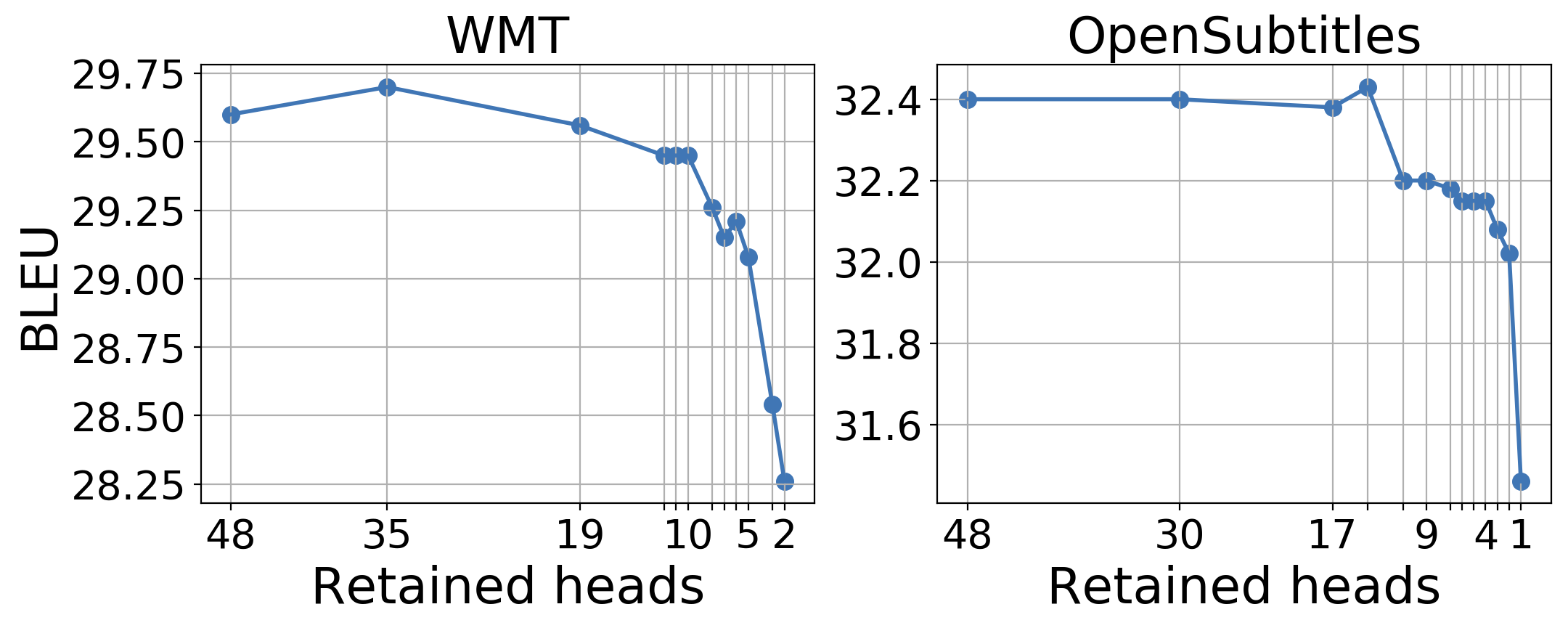
Figure 3: BLEU score as a function of number of retained encoder heads (EN-RU) shows robustness to head pruning.
Quantitative Assessment of Pruning
In the analysis, models pruned to a minimal set of heads retain performance, particularly for core language tasks like translation, as demonstrated in BLEU score evaluations across various configurations. Notably, models with heavily pruned encoder layers achieve translation quality within 0.15 BLEU points of the full model on English-Russian datasets.
Implications and Future Work
This research underscores the transformative potential of identifying and leveraging specialized attention heads in Transformer models. By reducing computational overhead without sacrificing accuracy, these insights have implications for deploying more efficient NMT systems. Future investigations could compare this pruning approach to other model compression techniques, exploring broader applications across different domains and languages.
Conclusion
The study reinforces the notion that in Transformer models, a minority of heads achieve significant functional impact, possessing specialized roles that can be accurately identified and selectively retained. The findings facilitate the development of streamlined models with reduced attention head counts, achieving competitive performance while optimizing computational resources.