- The paper introduces Winogender schemas to systematically evaluate gender bias in coreference resolution within occupational contexts.
- It analyzes rule-based, statistical, and neural models, revealing significant discrepancies in resolving male versus female pronouns.
- Results show strong correlations with real-world occupational data, highlighting the need for bias-aware debiasing techniques in NLP systems.
An Examination of Gender Bias in Coreference Resolution Systems
The paper "Gender Bias in Coreference Resolution" investigates gender bias in data-driven coreference resolution systems through the lens of occupational context. The authors expose systemic biases within coreference algorithms by leveraging novel evaluation methods. This essay analyzes the paper's methodologies, findings, and implications, considering the potential future directions in mitigating biases in NLP systems.
Methodology and Core Concepts
The researchers introduce "Winogender schemas," modeled after Winograd schemas, which provide a sentence-level challenge for coreference resolution systems. The primary innovation lies in the creation of paired sentences that differ only by the pronoun gender used, allowing the examination of gender bias when the system determines the referent of pronouns in occupational contexts. The test comprises 120 templates, resulting in 720 sentences, offering a comprehensive evaluation of how these systems manage gender-related biases.



Figure 1: Stanford CoreNLP rule-based coreference system resolves a male and neutral pronoun as coreferent with ``The surgeon,'' but does not for the corresponding female pronoun.
Evaluation of Coreference Systems
The study examines three coreference resolution systems: rule-based (Stanford multi-pass sieve), statistical, and neural network-based models. Each represents a distinct machine learning paradigm, providing a diverse evaluation landscape for understanding how gender biases emerge across different system architectures.
Rule-based systems such as the Stanford sieve leverage high-precision rule application, where gender information is considered as early-stage data influencing decisions. Conversely, statistical systems are feature-driven, potentially learning both intended resolutions and unintended biases from corpus data while utilizing numerous linguistic features. Neural models, though the most advanced in terms of architecture, integrate extensive learned features, including word embeddings which themselves might carry biases, thus challenging unbiased decision making.
Results and Discussion
The evaluation reveals that none of the systems operate in a gender-neutral manner. Significant discrepancies exist in the systems' pronoun resolution tasks, affected notably by pronoun gender in a way that amplifies existing real-world occupational gender roles.
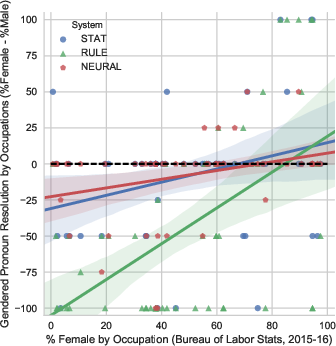
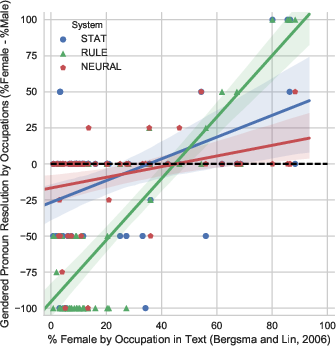
Figure 2: These two plots show how gender bias in coreference systems corresponds with occupational gender statistics from the U.S Bureau of Labor Statistics (left) and from text as computed by Bergsma and Lin (2006).
Statistically significant correlations were found between the systems' gender preferences and both Bureau of Labor Statistics data and textual occurrences. Particularly, systems exhibited a notable tendency to associate male pronouns more frequently with occupations compared to female or gender-neutral pronouns. This demonstrates simply how biases proliferate from training data into system predictions, further reinforcing existing gender stereotypes.
Implications and Future Prospects
The implication of this work is substantial for the future design of NLP systems. It accentuates the need for bias-aware system development, particularly as AI technologies increasingly pervade sensitive applications where impartiality is crucial. Furthermore, it showcases the importance of targeted evaluations like the Winogender schemas in uncovering specific bias manifestations that may influence practical system behavior negatively.
Future research may build on this foundation by expanding the scope of evaluation to include other forms of gender expression and diverse cultural contexts. Additionally, developing and validating systemic debiasing techniques through data augmentation, counterfactual analysis, or adversarial debiasing is imperative for enhancing the fairness of NLP systems.
Conclusion
The exploration of gender bias in coreference resolution systems highlighted by this paper underscores an urgent need to address biases inherent in automated systems. The methodological introduction of Winogender schemas provides researchers with a rigorous tool for evaluating and diagnosing gender biases in NLP systems. The study not only raises awareness of systematic biases but also directs ongoing and future efforts towards constructing more gender-fair language technologies. Such advancements hold significant promise for reducing the risks of amplifying societal biases through automated NLP systems.