- The paper presents a novel RNN-based architecture achieving 4.3%-8.8% AUC improvements over JPEG in MS-SSIM and PSNR-HVS metrics.
- It introduces an encoder-decoder framework with a binarizer and entropy coding, enabling variable compression rates without retraining.
- Empirical evaluations on the Kodak dataset demonstrate superior compression efficiency and potential for scalable real-world deployment.
Full Resolution Image Compression with Recurrent Neural Networks
This paper explores innovative methods for full-resolution lossy image compression leveraging recurrent neural networks (RNNs). It highlights advancements in using neural networks for competitive compression across diverse rates and resolutions.
Image Compression Methodology
The proposed architecture integrates an RNN-based encoder-decoder framework, a binarizer, and an entropy coding network. One notable feature is the ability to achieve variable compression rates without retraining, due to the flexible RNN architecture. The encoder-decoder setup encodes input images, transforms them into binary codes, and attempts reconstruction using residual errors across iterative steps. This procedure encompasses both rate-distortion optimization and entropy coding, crucial for enhancing compression efficiency.
RNN Variants and Innovations
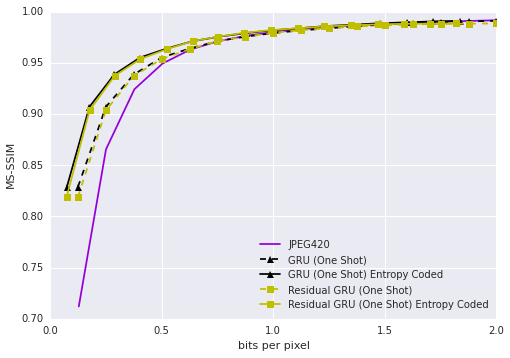
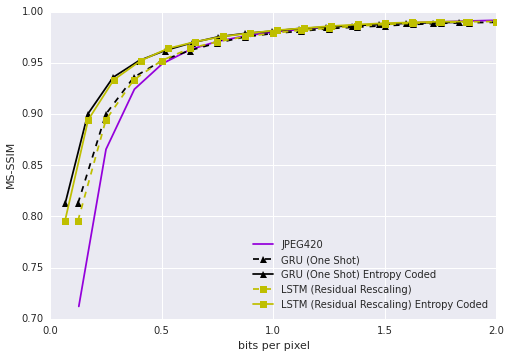
Figure 1: Rate distortion curve on the Kodak dataset given as MS-SSIM vs. bit per pixel (bpp).
Compression Results
The empirical results demonstrate the RNN's ability to surpass JPEG in compression efficiency, particularly on the Kodak dataset in terms of both MS-SSIM and PSNR-HVS metrics. This performance persists across various bitrates, supported by the flexibility and robustness of the RNN architectures.
Key Findings
- The study reports improvements between 4.3% and 8.8% in AUC over traditional methods.
- Variants of the proposed models consistently outperform JPEG, especially evident in the distortion reduction at similar compression rates.

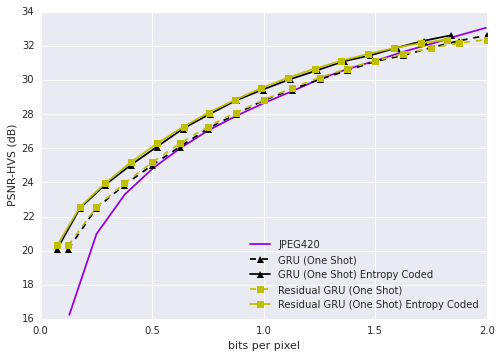
Figure 2: Rate distortion curve on the Kodak dataset given as PSNR-HVS vs. bit per pixel (bpp).
Implementation Considerations
The deployment of this framework involves considerations such as computational resources for training and inference, as well as scalability to diverse datasets and resolutions. The emphasis on using entropy coding for further performance gains highlights the significance of optimizing compressive efficiency via redundancy minimization.
Future Prospects
Future developments could target the integration of these neural architectures with video compression codecs like WebP, which leverage spatial redundancy. Additionally, refining perceptual metrics to better correlate with human visual perception remains a critical area for enhancing the perceptual quality of compressed outputs.
Conclusion
This exploration into RNN-based image compression underscores its potential in outperforming traditional methods like JPEG by leveraging neural network adaptability across compression rates. The findings illustrate promising directions for future enhancements in neural compression technologies, particularly through refined entropy coding and potential fusion with video codec technologies.

Figure 3: Comparison of compression results on Kodak Image 5 at various bitrates, showcasing the superior performance of the Residual GRU (One Shot) method.