Published 10 Jun 2016 in cs.NE and cs.LG | (1606.03401v1)
Abstract: We propose a novel approach to reduce memory consumption of the backpropagation through time (BPTT) algorithm when training recurrent neural networks (RNNs). Our approach uses dynamic programming to balance a trade-off between caching of intermediate results and recomputation. The algorithm is capable of tightly fitting within almost any user-set memory budget while finding an optimal execution policy minimizing the computational cost. Computational devices have limited memory capacity and maximizing a computational performance given a fixed memory budget is a practical use-case. We provide asymptotic computational upper bounds for various regimes. The algorithm is particularly effective for long sequences. For sequences of length 1000, our algorithm saves 95\% of memory usage while using only one third more time per iteration than the standard BPTT.
The paper introduces a dynamic programming method to optimally trade off memory storage and recomputation in BPTT.
It demonstrates up to 95% reduction in memory usage for training RNNs on long sequences with a mild 33% increase in computation time.
The strategy adapts to user-defined memory constraints by reusing memory slots, enabling efficient RNN training on memory-limited devices.
Memory-Efficient Backpropagation Through Time
The paper "Memory-Efficient Backpropagation Through Time" discusses a novel approach to reducing memory usage in the Backpropagation Through Time (BPTT) algorithm, which is critical for training Recurrent Neural Networks (RNNs). This solution employs dynamic programming to balance memory caching and recomputation, allowing for optimal execution within a user-defined memory constraint while minimizing computational cost. This enhancement is particularly advantageous for long sequence processing on devices with limited memory capacity, such as GPUs.
Introduction and Background
Recurrent Neural Networks (RNNs), including Long Short-Term Memory (LSTM) networks, are pivotal in applications such as sequence generation and speech recognition due to their ability to process sequences by maintaining hidden states across time steps. The BPTT is the predominant algorithm for training RNNs, where it functions by unrolling the network in time and applying standard backpropagation. However, this process is memory-intensive since it requires storing internal states for each time-step, posing challenges for deployment on memory-limited hardware.
The authors focus on optimizing BPTT by strategically deciding which intermediate states to store and which to recompute on-demand, trading off between memory storage and computational repetition. This strategy utilizes dynamic programming to formulate an optimal policy for memory usage, given the imposed memory constraints.
Dynamic Programming for Memory Optimization
The paper details a method where the dynamic programming approach computes an optimal trade-off between storing and recomputing intermediate results. Key elements of this approach include:
State Memorization Strategy: The approach involves selectively memorizing certain states during forward passes and recalculating others during backward passes, reducing overall memory usage without excessively increasing computation time.
Memory Slot Reuse: The algorithm reuses memory slots for storing different hidden or internal states across different time steps, further economizing memory usage.
Adaptability: The strategy adapts dynamically to the available memory, ensuring that computational resources are utilized most efficiently.
Figure 1: Illustration of the optimal strategy for two scenarios, exemplifying how the proposed method adapts to different memory constraints and sequence lengths.
Implementation and Computational Costs
The BPTT-Hidden State Memorization (BPTT-HSM) approach and its variations, such as the BPTT-Internal State Memorization (BPTT-ISM) and BPTT-Mixed State Memorization (BPTT-MSM), are proposed. The core difference hinges on what types of states (hidden or internal) are stored and the corresponding trade-offs in computation and memory.
BPTT-HSM focuses on storing hidden states which occupy less memory compared to internal states.
BPTT-ISM emphasizes storing internal states to potentially save on recomputation costs.
BPTT-MSM combines strategies to optimize both memory and computation based on availability and necessity.
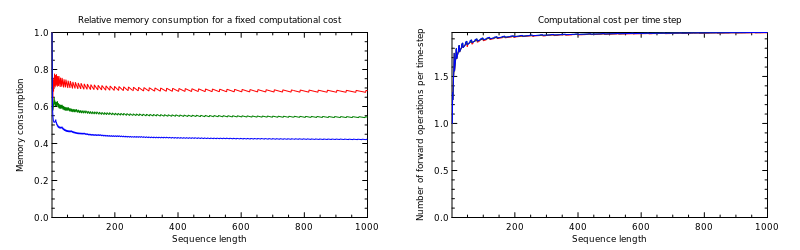
Figure 2: Memory consumption performance illustrated, demonstrating the proposed algorithm's efficiency in reducing memory usage divided by t, compared to previous methods.
Evaluation and Results
The proposed approach significantly reduces memory usage—up to 95% for sequences as long as 1000, with a marginal increase in computational time (approximately 33% more per iteration compared to standard BPTT).
Comparisons with previous methods, such as Chen's t and recursive algorithms, show that the proposed method can fit tighter memory budgets while maintaining or even exceeding computational efficiency. Notably, the dynamic approach allows for a more granulated control over memory utilization, essential for practical applications with strict memory limits.
Conclusion
This research presents a highly efficient method for implementing BPTT on RNNs under constrained memory conditions. By leveraging dynamic programming to optimize the memory-computation trade-off, the method not only allows RNNs to be trained with longer sequences and on memory-limited hardware, but also aligns closely with theoretical efficiency limits.
Future work might explore further optimizations specific to different RNN architectures and extend the approach to other types of neural networks where memory constraints present significant challenges.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.