- The paper introduces a runtime memory manager that offloads intermediate feature maps to CPU, enabling deeper network training.
- It implements both static and dynamic memory policies, achieving up to 89% memory reduction on architectures like AlexNet while balancing performance trade-offs.
- The study demonstrates scalability across complex networks and sets the stage for future integration with advanced interconnects such as NVLink.
Virtualized Deep Neural Networks for Scalable, Memory-Efficient Neural Network Design
The paper "vDNN: Virtualized Deep Neural Networks for Scalable, Memory-Efficient Neural Network Design" (arXiv ID: (1602.08124)) introduces a novel runtime memory manager to tackle the limitations imposed by GPU memory capacity during the training of deep neural networks (DNNs). The proposed solution, vDNN, seeks to efficiently virtualize memory usage across both GPU and CPU memory, enabling the training of larger network architectures that exceed the constraints of physical GPU memory.
Introduction to vDNN
Deep Neural Networks have achieved remarkable success across various domains, including computer vision, speech recognition, and NLP, driven largely by the computational power of GPUs. However, the DRAM capacity of GPUs often limits the size and depth of DNNs that can be trained effectively, requiring either cumbersome architecture choices or parallelization across multiple GPUs. vDNN aims to overcome these challenges by implementing a memory management strategy that reduces GPU memory usage through intelligent data transfer between GPU and CPU storage.

Figure 1: GPU memory usage when using the baseline, network-wide allocation policy and its maximum utilization.
Technical Implementation
vDNN Design Principle
vDNN operates on a layer-wise memory management strategy. During training, DNNs require significant memory overhead for storing intermediate feature maps due to their layer-wise architecture and stochastic gradient descent (SGD)-based training. By offloading and prefetching these intermediate data structures to and from host memory, vDNN effectively reduces the GPU memory burden:
- Memory Offload: Intermediate feature maps, primarily the input feature maps (X), are offloaded to CPU memory when they are not immediately needed during forward propagation.
- Memory Prefetch: Offloaded data is prefetched back to GPU memory to ensure their availability during backward propagation, overlapping the data transfer with computations to mitigate latency penalties.
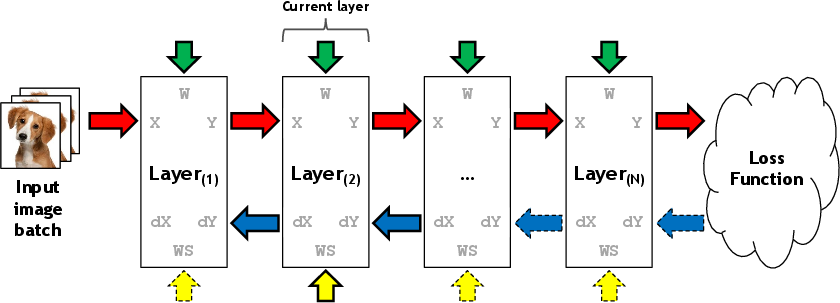
Figure 2: Memory allocations required for linear networks using the baseline memory manager.
Dynamic and Static Memory Policies
The paper presents both static and dynamic memory transfer policies:
Experimental Results
Experiments show significant reductions in memory usage with vDNN. For instance, AlexNet's GPU memory usage is reduced by up to 89%, with similar reductions for OverFeat and GoogLeNet.
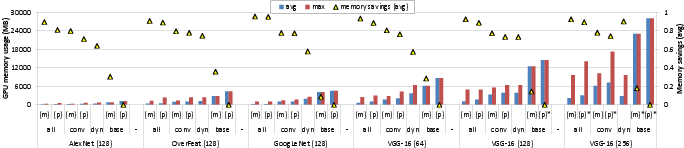
Figure 4: Average and maximum memory usage and corresponding savings with vDNN.
Despite these memory efficiency gains, vDNN incurs varying performance penalties. Static policies lead to up to 63% decline in performance in some configurations due to offloading overhead, while dynamic vDNN maintains competitive performance with minimal loss by optimizing the workload balance.
Scalability to Deep Networks
The scalability of vDNN is illustrated with exceedingly deep networks, demonstrating reduced GPU memory usage while maintaining performance levels. vDNN effectively manages networks with hundreds of layers without notable degradation.
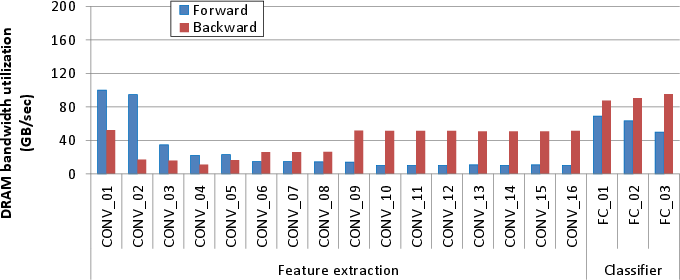
Figure 5: Maximum DRAM bandwidth utilization for each CONV layer's forward and backward propagation.
Implications and Future Work
vDNN allows researchers to train deeper and larger networks using existing hardware, facilitating advancements in model design without memory constraints. The implications extend to fields that require extensive compute power and memory, such as healthcare and autonomous systems.
Future developments may explore integration of vDNN with new generation interconnects like NVLink, offering enhanced bandwidth and further reducing overheads associated with offloading processes.
Conclusion
vDNN provides a robust solution to memory inefficiencies in DNN training on GPUs, significantly reducing memory demands and enabling scalable network design. With promising results across a range of established and deep network configurations, vDNN sets a precedent for memory management in machine learning practices, paving the way for more flexible and scalable AI applications.


