Generative Adversarial Networks
Abstract: We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
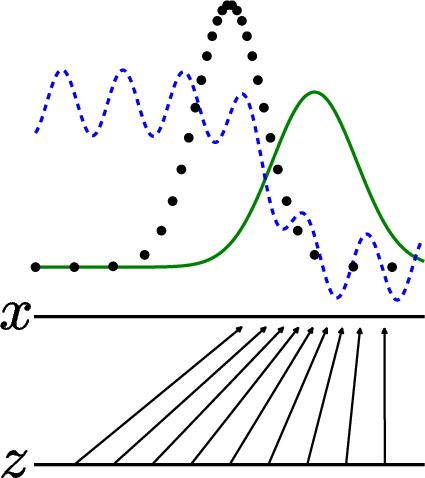
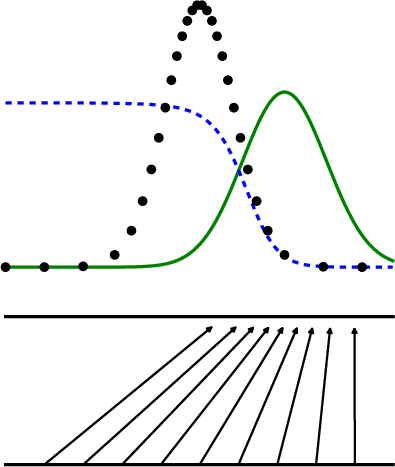
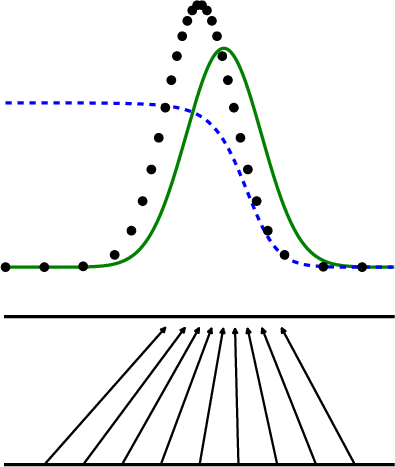
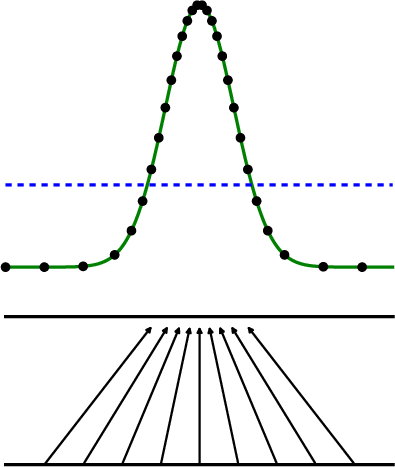




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Immediate Applications
The following applications can be deployed now, using the paper’s adversarial training framework (generator and discriminator MLPs, alternating updates, non-saturating generator loss) and the straightforward extensions mentioned in the paper.
- Synthetic image data augmentation for classifiers (software, robotics, healthcare imaging)
- Use a trained GAN to generate additional samples to balance classes or increase dataset size (e.g., digits, faces, simple objects).
- Workflow: train GAN on existing image dataset → sample synthetic images → curate (optionally using the discriminator’s score) → mix into supervised training pipeline.
- Tools/products: “GAN Augmentor” module for training and sampling; discriminator-based quality filter.
- Assumptions/dependencies: requires sufficient training data and compute; image labeling is best with conditional GANs (paper describes the extension); monitor overfitting/memorization and mode collapse.
- Discriminator-based anomaly and quality scoring (finance, manufacturing, cybersecurity, data ops)
- Treat the discriminator’s output D(x) as a “in-distribution” score to identify outliers or low-quality samples in incoming streams (e.g., transactions, images).
- Workflow: train GAN on historical “normal” data → use D(x) to score new samples → flag low-probability items for review.
- Tools/products: “GAN-QC” scoring service; thresholding and calibration utility.
- Assumptions/dependencies: needs representative training distribution; score calibration (e.g., Platt scaling) improves usability; discriminator can be misled if generator collapses or data drifts.
- Privacy-preserving synthetic dataset sharing (policy, healthcare, public sector, software)
- Generate synthetic data that mimics real distributions for sharing and collaboration without exposing raw sensitive records (e.g., faces, simple tabular-like image proxies).
- Workflow: train GAN on sensitive data → produce synthetic dataset → validate privacy risk (e.g., nearest-neighbor checks as in the paper’s visualization) → release synthetic set for modeling/education.
- Tools/products: “Synthetic Data Generator” with built-in privacy diagnostics; nearest-neighbor and memorization checks.
- Assumptions/dependencies: privacy is not guaranteed; assess memorization risk and privacy leakage; images are more immediate than complex structured/tabular data.
- Semi-supervised feature learning via discriminator (academia, education, software)
- Use intermediate features from the discriminator to improve classifiers when labeled data is limited (explicitly suggested in the paper).
- Workflow: train GAN on mostly unlabeled data → extract D’s features → train a lightweight classifier with few labels.
- Tools/products: “GAN Feature Extractor” library; plug-in for standard ML pipelines.
- Assumptions/dependencies: feature utility depends on discriminator architecture/regularization (e.g., dropout); performance varies across domains.
- Fast sampling for simulation and prototyping without Markov chains (academia, software)
- Replace MCMC-based sampling with generator forward passes to accelerate prototyping of generative tasks, demonstrations, and classroom labs.
- Workflow: train GAN → sample via forward propagation → integrate samples into simulation/evaluation tasks.
- Tools/products: “GAN Sampler” API for rapid drawing; reproducible latent seeds.
- Assumptions/dependencies: quality hinges on training stability; no explicit likelihood—evaluation requires task-specific metrics.
- Learned approximate inference for latent codes (software, academia)
- Train an auxiliary network to predict z from x (proposed in the paper) to enable latent-space manipulation, clustering, and retrieval.
- Workflow: after GAN training, fit x→z inference net → use z for visualization, interpolation, or content retrieval.
- Tools/products: “GAN Latent Mapper”; z-space inspector.
- Assumptions/dependencies: mapping quality depends on generator’s latent geometry; auxiliary training is separate and may need regularization.
- Rapid content prototyping for creative teams (media, design)
- Generate diverse style/appearance variants (faces, digits, basic objects) for ideation, mockups, and UI testing.
- Workflow: train GAN on domain assets → sample variations → select and iterate.
- Tools/products: “GAN Ideation Studio” with sampling controls and latent-space interpolation (as demonstrated in the paper).
- Assumptions/dependencies: domain coverage requires representative training data; conditional generation improves control.
- Data pipeline monitoring and drift detection (software, MLOps)
- Use D(x) over time to detect distribution shifts in incoming data streams feeding ML systems.
- Workflow: train GAN on baseline → monitor D(x) on new data → alert when scores deviate from baseline ranges.
- Tools/products: “GAN Drift Monitor” dashboard; score trend analytics.
- Assumptions/dependencies: baseline must remain relevant; retrain periodically as data evolves.
- Teaching and benchmarking generative modeling (education, academia)
- Use GANs in coursework/labs to teach adversarial training, minimax optimization, and generative sampling without MCMC.
- Workflow: course materials → assignments reproducing MNIST/TFD experiments → evaluations via Parzen or task metrics.
- Tools/products: “GAN Classroom Kit” with ready-to-run scripts and datasets.
- Assumptions/dependencies: evaluation metrics (e.g., Parzen) have high variance; pair with qualitative assessments.
Long-Term Applications
These applications require further research, engineering, scaling, or domain-specific adaptation beyond the paper’s baseline image results and suggested extensions.
- Conditional GANs for controllable generation (healthcare, robotics, media)
- Produce class- or attribute-conditioned outputs (e.g., disease-specific medical image augmentation, object-conditioned simulation assets).
- Potential workflow: add conditioning inputs c to both G and D (explicitly suggested) → train with labeled datasets → deploy in augmentation or synthesis pipelines.
- Tools/products: “Conditional GAN Studio” with label/attribute controls.
- Assumptions/dependencies: labeled data availability; conditioning stability; robust evaluation and clinical validation for sensitive domains.
- Inpainting and conditional completion via shared-parameter conditionals (software, media, healthcare)
- Model p(x_S | x_¬S) to fill missing regions (suggested in the paper’s extensions), enabling image inpainting, masking, and completion.
- Potential workflow: train family of conditional models with shared parameters → apply masks at inference to reconstruct missing parts.
- Tools/products: “GAN Inpainter” with mask-aware conditioning.
- Assumptions/dependencies: training stability with partial observations; careful architecture design; robust evaluation (PSNR/SSIM/perceptual metrics).
- Synthetic training data for safety-critical systems (autonomous driving, medical diagnosis)
- Generate rare or extreme scenarios to improve robustness of perception and decision models.
- Potential workflow: domain-specific curation → conditional GANs to target rare conditions → integrate into systematic validation suites.
- Tools/products: “GAN Scenario Generator” for rare events; validation harness.
- Assumptions/dependencies: strong domain supervision; safety/regulatory validation; bias and realism audits.
- Privacy-by-design frameworks using synthetic data (policy, compliance, enterprise software)
- Formalize processes for replacing or augmenting sensitive datasets with GAN-generated surrogates under privacy risk bounds.
- Potential workflow: privacy risk measurement (membership inference, memorization tests) → synthetic data generation → governance policies and audit trails.
- Tools/products: “Synthetic Data Governance Toolkit.”
- Assumptions/dependencies: privacy metrics maturity; regulatory acceptance; domain-specific leakage assessments.
- GAN-based domain adaptation and data balancing (healthcare, finance, manufacturing)
- Use GANs to reduce dataset bias across domains (e.g., hospitals, geographies) and balance classes for rare outcomes.
- Potential workflow: multi-domain conditional setup → generate samples to equalize distributions → retrain classifiers with balanced datasets.
- Tools/products: “GAN Domain Balancer.”
- Assumptions/dependencies: careful conditioning and validation; fairness audits; risk of introducing new biases.
- Generative modeling for sequential/audio data (speech synthesis, sensor data, energy)
- Extend adversarial training to time series and audio waveforms (cited as target domain in the paper’s intro) with architectures adapted to sequence structure.
- Potential workflow: sequential/discrete prior modeling → generator/discriminator with temporal convolutions/recurrent units → deploy for synthetic speech or anomaly detection.
- Tools/products: “Seq-GAN Lab.”
- Assumptions/dependencies: architecture and training stability for sequential data; evaluation metrics beyond images.
- Robust GAN training orchestration and stability tooling (software tooling, MLOps)
- Develop systems to coordinate G and D updates, detect/mitigate mode collapse (“Helvetica scenario”) and automate hyperparameter tuning.
- Potential workflow: training monitor with divergence, D/G loss dynamics, sample diversity metrics; automated interventions.
- Tools/products: “GAN Orchestrator” with stability diagnostics and non-saturating loss presets (as the paper recommends).
- Assumptions/dependencies: reliability of metrics; domain-specific stability criteria; scalable infrastructure.
- Standardized evaluation suites for generative models (academia, industry benchmarking)
- Replace high-variance Parzen estimates with robust, task-relevant benchmarks (image, audio, tabular), fostering reproducibility and fair comparison.
- Potential workflow: open datasets + standardized metrics + submission pipelines; qualitative panels plus quantitative scores.
- Tools/products: “GAN Benchmark Suite.”
- Assumptions/dependencies: community consensus on metrics; coverage across domains; resource support for shared infrastructure.
- Adversarially trained anonymization and de-identification (policy, healthcare)
- Use discriminator feedback to minimize identifiable features while preserving utility.
- Potential workflow: multi-objective training (utility vs. identifiability) → deploy for image de-ID or stylization that retains analytical features.
- Tools/products: “GAN De-ID Framework.”
- Assumptions/dependencies: trade-off tuning; legal acceptance; adversarial privacy attacks must be considered.
- Synthetic data services and marketplaces (software, enterprise)
- Offer managed platforms that generate, validate, and serve synthetic datasets tailored to clients’ use cases.
- Potential workflow: ingestion of client data → GAN training → privacy/quality validation → delivery via APIs.
- Tools/products: “GAN-as-a-Service.”
- Assumptions/dependencies: contractual privacy assurances; domain adaptation; sustained model maintenance and drift handling.
- Cross-domain simulation-to-real transfer support (robotics, AR/VR)
- Improve realism of simulated assets or bridge domain gaps with adversarial generation.
- Potential workflow: train GANs on real-world data to refine simulated outputs or re-style synthetic data to match target domains.
- Tools/products: “GAN Domain Bridge.”
- Assumptions/dependencies: comprehensive real-world datasets; careful validation to avoid negative transfer.
- Fairness auditing via generative probes (policy, academia, responsible AI)
- Use GANs to probe model behavior across synthetic populations or conditions, assessing bias and sensitivity.
- Potential workflow: generate controlled variations (via conditional GANs) → evaluate downstream model responses → report bias metrics.
- Tools/products: “GAN Fairness Auditor.”
- Assumptions/dependencies: interpretable conditioning; aligned fairness definitions; domain-specific ethics frameworks.
Notes across applications:
- Training stability depends on coordinating G and D (update frequency k, learning rates) and using non-saturating generator loss (as advised in the paper).
- Mode collapse is a key risk (“Helvetica scenario”)—monitor diversity and consider architectural/regularization remedies.
- There is no explicit likelihood under p_g; evaluation must rely on task-specific metrics, qualitative inspection, or alternative quantitative proxies.
- Compute and data availability are practical constraints; models are sensitive to data quality and representativeness.
Collections
Sign up for free to add this paper to one or more collections.

