- The paper presents a novel framework that quantifies prompt-response semantic drift to assess hallucination fidelity in large language models using divergence metrics.
- It utilizes joint clustering of sentence embeddings and multiple information-theoretic metrics, including Jensen-Shannon divergence and Wasserstein distance, for detailed response evaluation.
- Experimental analysis demonstrates the framework’s capability to detect varying semantic shifts from factual to creative prompts, emphasizing its diagnostic utility.
Semantic Divergence Metrics for Faithfulness Hallucination Detection in LLMs
Introduction
The paper "Prompt-Response Semantic Divergence Metrics for Faithfulness Hallucination and Misalignment Detection in LLMs" introduces a novel framework for detecting intrinsic faithfulness hallucinations in LLMs. These hallucinations occur when model responses deviate significantly from the given input context. The proposed Semantic Divergence Metrics (SDM) framework seeks to quantify the semantic alignment between prompts and responses, offering a prompt-aware approach that improves upon the limitations of existing methods.
Methodology
Overview
The SDM framework utilizes joint clustering on sentence embeddings to establish a shared topic space for both prompts and responses, allowing for a detailed semantic comparison. The framework is designed to operate in a black-box setting, focusing on real-time detection of faithfulness hallucinations.
Key Components
- Prompt-aware Testing: The framework generates multiple responses to semantically equivalent paraphrased prompts, deepening the analysis of response consistency.
- Joint Embedding Clustering: Sentence embeddings from prompts and responses are clustered together to create a shared semantic topic space.
- Semantic Divergence Metrics: A suite of information-theoretic metrics, including Jensen-Shannon divergence and Wasserstein distance, are computed to measure semantic drift.
- Semantic Box Framework: This diagnostic tool integrates various metrics to classify different LLM response types, such as confident confabulations.
Algorithmic Framework
The paper presents a detailed, multi-step algorithm for implementing the SDM framework:
- Data Generation and Embedding: Generate paraphrases and corresponding responses, and embed the sentences using a sentence-transformer.
- Joint Clustering: Cluster the combined prompt-response embeddings to identify the shared topic space.
- Metric Calculation: Compute diverse metrics, such as Jensen-Shannon divergence and Wasserstein distance, to assess semantic alignment.
- Hallucination Score: The final hallucination score SH is calculated as a weighted sum of the divergence metrics, normalized by prompt complexity.
Experimental Analysis
Experiment Set A: Stability Gradient
- Prompts: Designed to test varying degrees of stability, from factual (Hubble) to interpretive (Hamlet), to creative (AGI Dilemma).
- Findings: The framework effectively tracked the stability gradient, with higher SH scores for more creative prompts.
- Diagnostic Power: Visual heatmaps and co-occurrence distributions illustrated distinct response patterns across different stability scenarios.
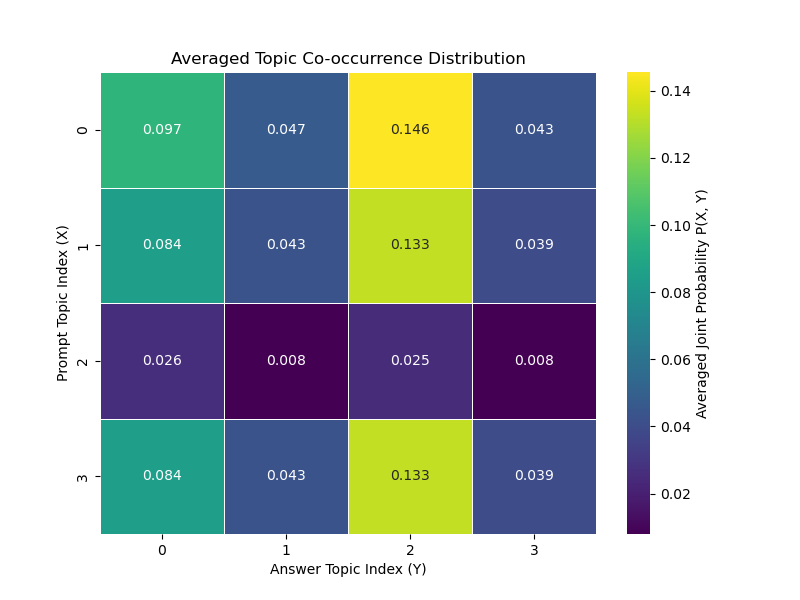
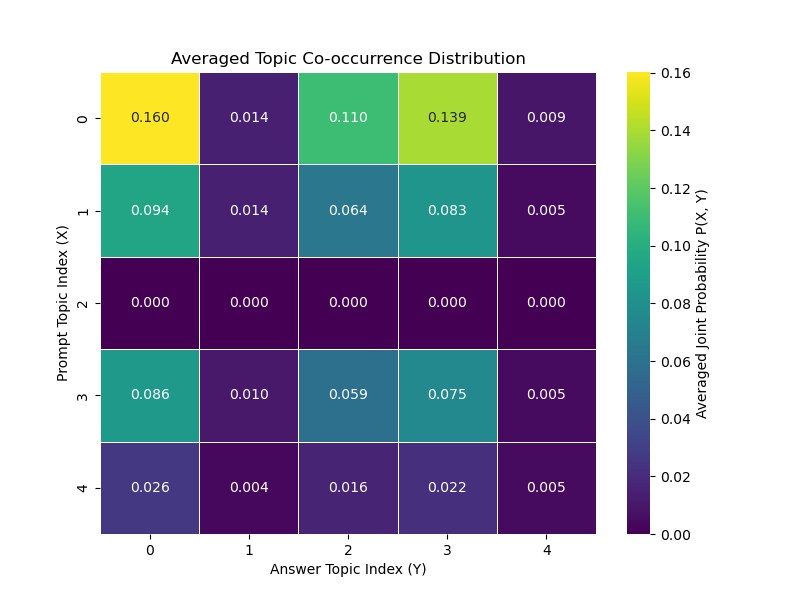
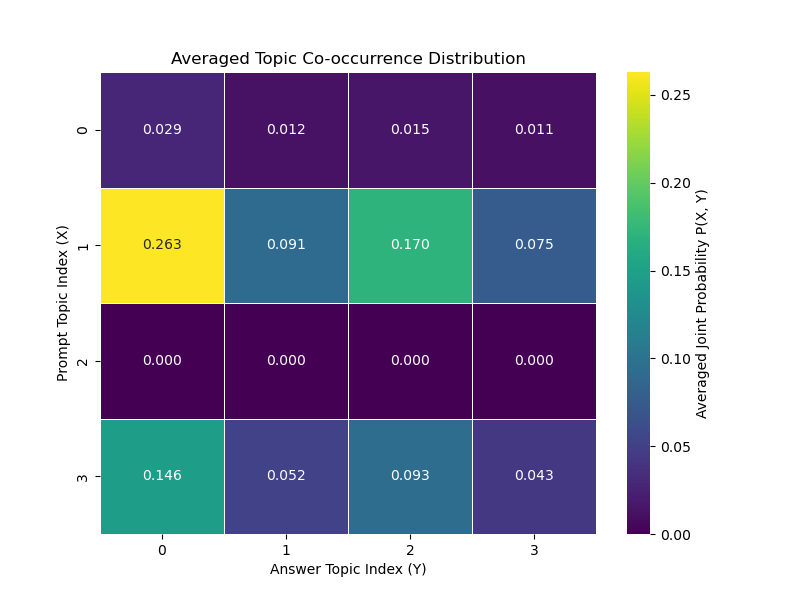
Figure 1: Averaged Topic Co-occurrence Distributions for Experiment Set A. The heatmaps show the averaged joint probability $P_{\text{avg}(X,Y)$.
Experiment Set B: Diverse Prompt Types
- Prompts: Spanned a range from factual to nonsensical, including a forced hallucination scenario.
- Insights: Low SH scores were observed for grounded responses, while the forced hallucination prompt revealed the model's confident evasion strategy.
- Semantic Exploration: KL Divergence served as a critical indicator of the model's generative exploration under different constraints.
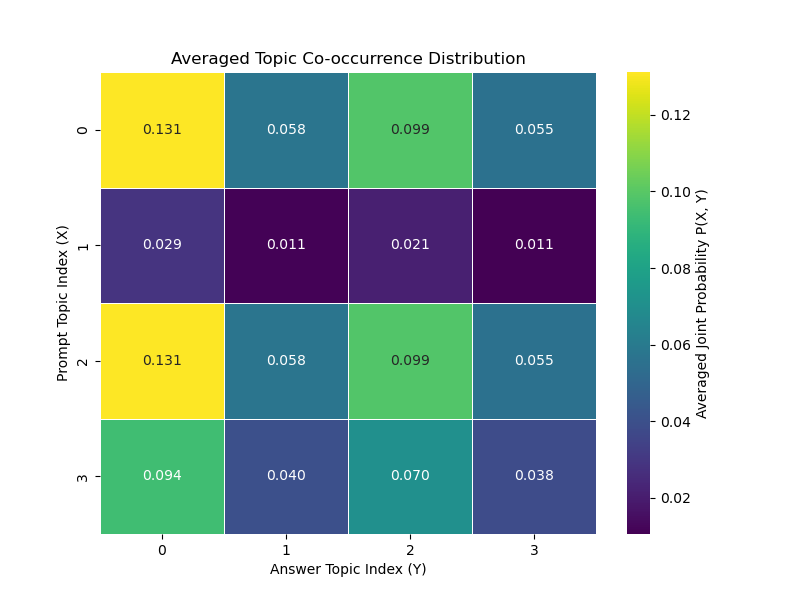
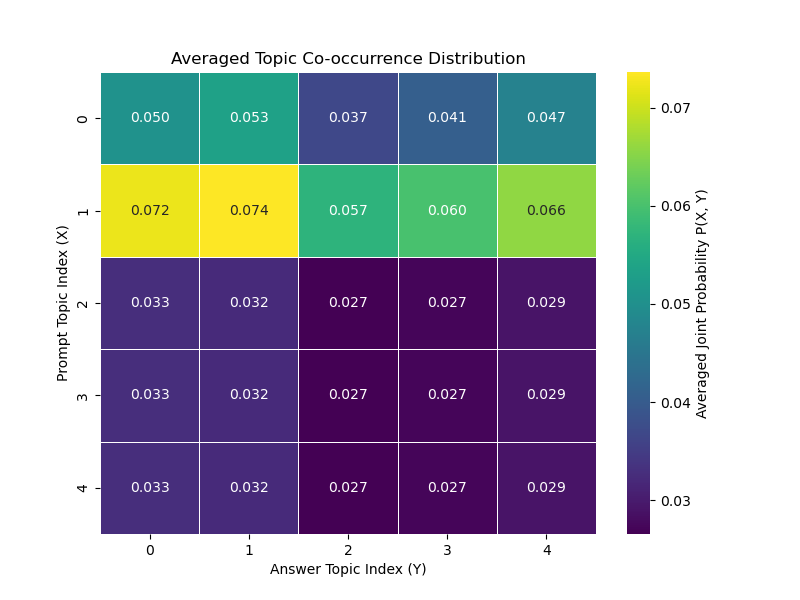
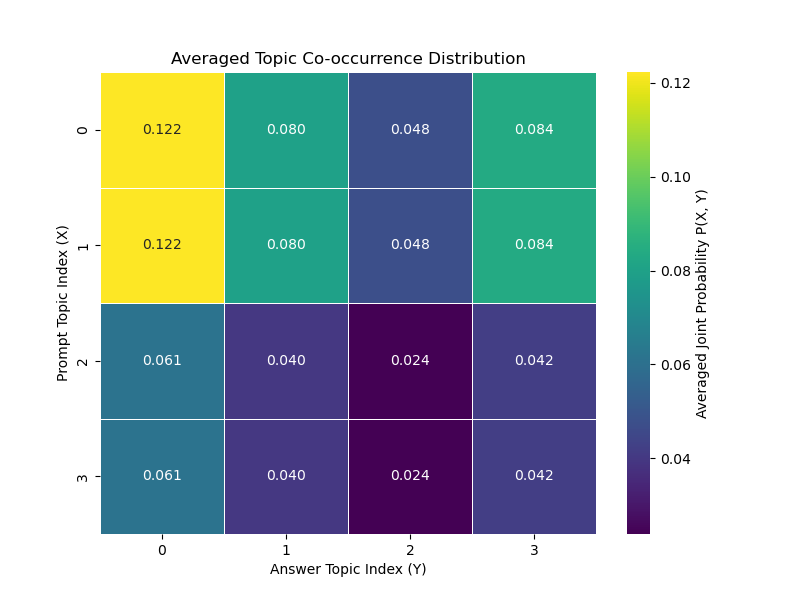
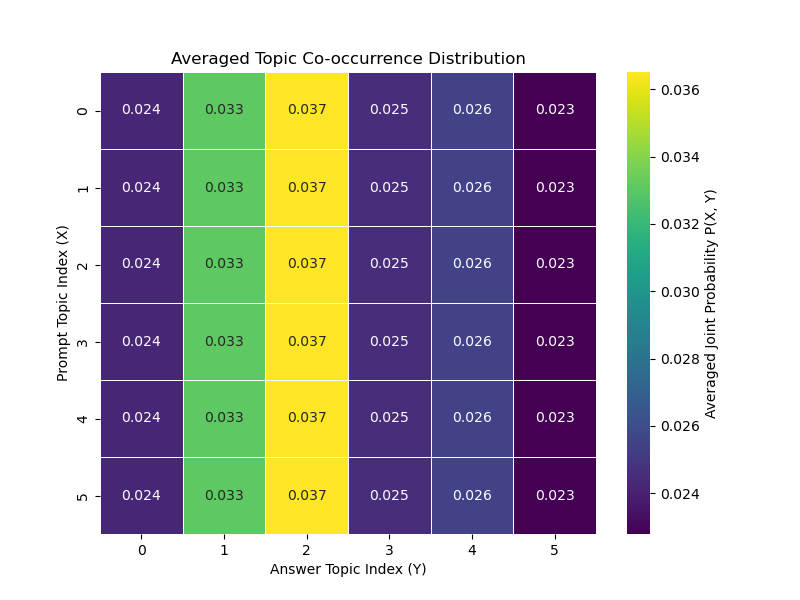
Figure 2: Averaged Topic Co-occurrence Distributions for Experiment Set B. The heatmaps show the averaged joint probability $P_{\text{avg}(X,Y)$.
Conclusion
The SDM framework advances the detection of hallucinations in LLMs by providing a prompt-aware, diagnostic approach grounded in information theory. It captures both thematic and content-level semantic shifts, offering insights into semantic exploration and response stability. While effective, the framework's context-dependent nature suggests future work on self-calibrating methods to enhance its applicability across diverse tasks. This paper presents a step towards more reliable and interpretable hallucination assessment for modern LLM deployments.

