- The paper introduces a novel multi-agent framework that generates interpretable, modular Blender code for 3D asset creation across diverse shape categories.
- It leverages BlenderRAG for retrieval-augmented generation, achieving a 5× increase in complex operations and a 26% reduction in error rates.
- The system enables iterative, user-guided asset refinement with automatic visual critique and verification to maintain high fidelity to user prompts.
LL3M: Large Language 3D Modelers — A Multi-Agent LLM System for Interpretable 3D Asset Generation
Introduction and Motivation
LL3M introduces a paradigm shift in 3D asset generation by leveraging a multi-agent system of pretrained LLMs to write interpretable Python code for Blender, rather than relying on traditional representation-centric generative models or direct mesh token prediction. The system reformulates shape generation as a code-writing task, enabling modularity, editability, and seamless integration with artist workflows. This approach circumvents the need for large 3D datasets or finetuning, instead utilizing the abstraction and reusability inherent in code to generalize across diverse shape categories and styles.
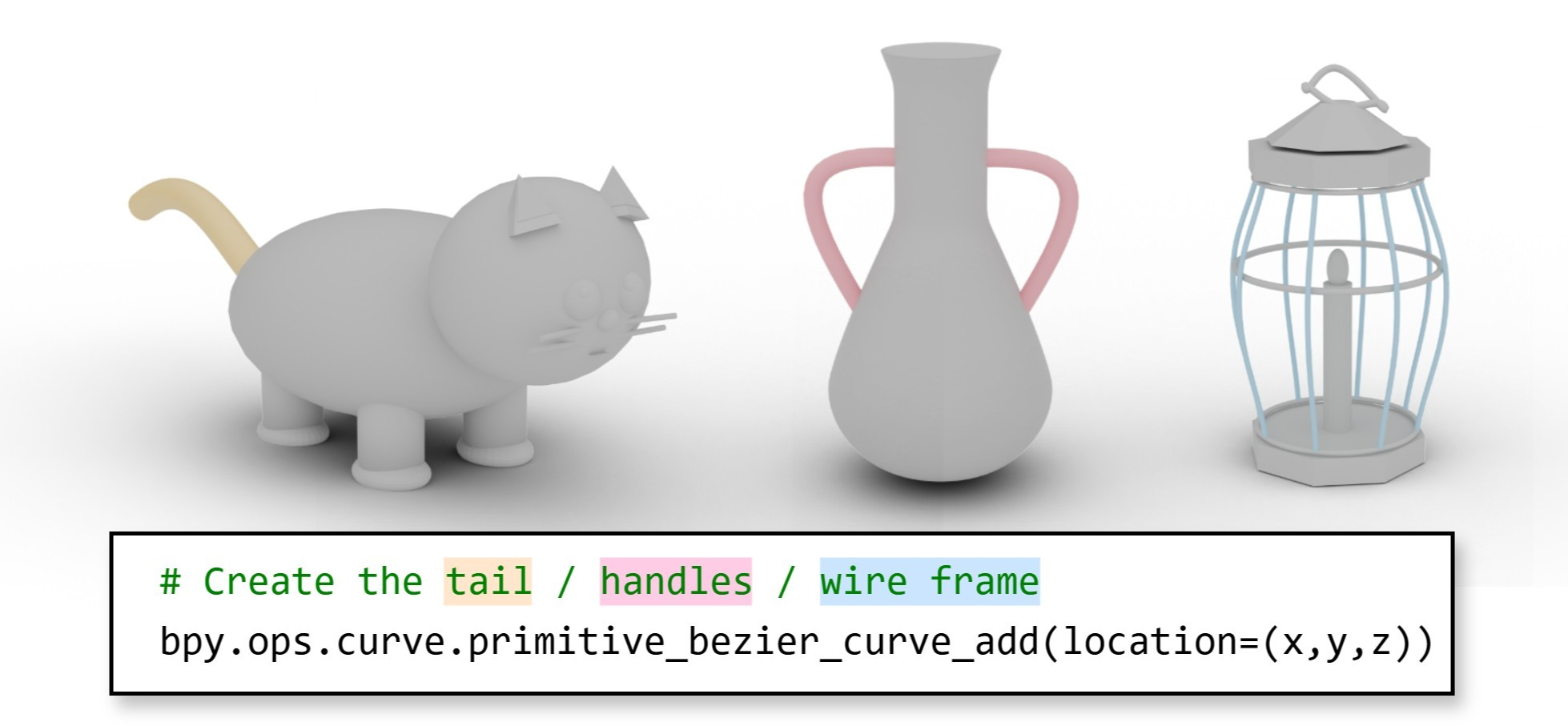
Figure 1: Reusable code structure enables generalization across visually distinct shapes via shared high-level code patterns.
System Architecture and Workflow
LL3M is architected as a multi-agent framework, orchestrated by an external controller, with six specialized agents: planner, retrieval, coding, critic, verification, and user feedback. The workflow is divided into three phases:
- Initial Creation: The planner agent decomposes the user prompt into subtasks, the retrieval agent accesses BlenderRAG (a RAG database of Blender API documentation), and the coding agent writes and executes modular Blender code for each subtask.
- Auto-Refinement: The critic agent, powered by a VLM, analyzes multi-view renders of the asset, identifies discrepancies, and proposes targeted improvements. The coding agent applies these fixes, and the verification agent ensures their correct implementation.
- User-Guided Refinement: Users can iteratively provide high-level or fine-grained instructions, which are processed by the coding and verification agents to update the asset without full regeneration.
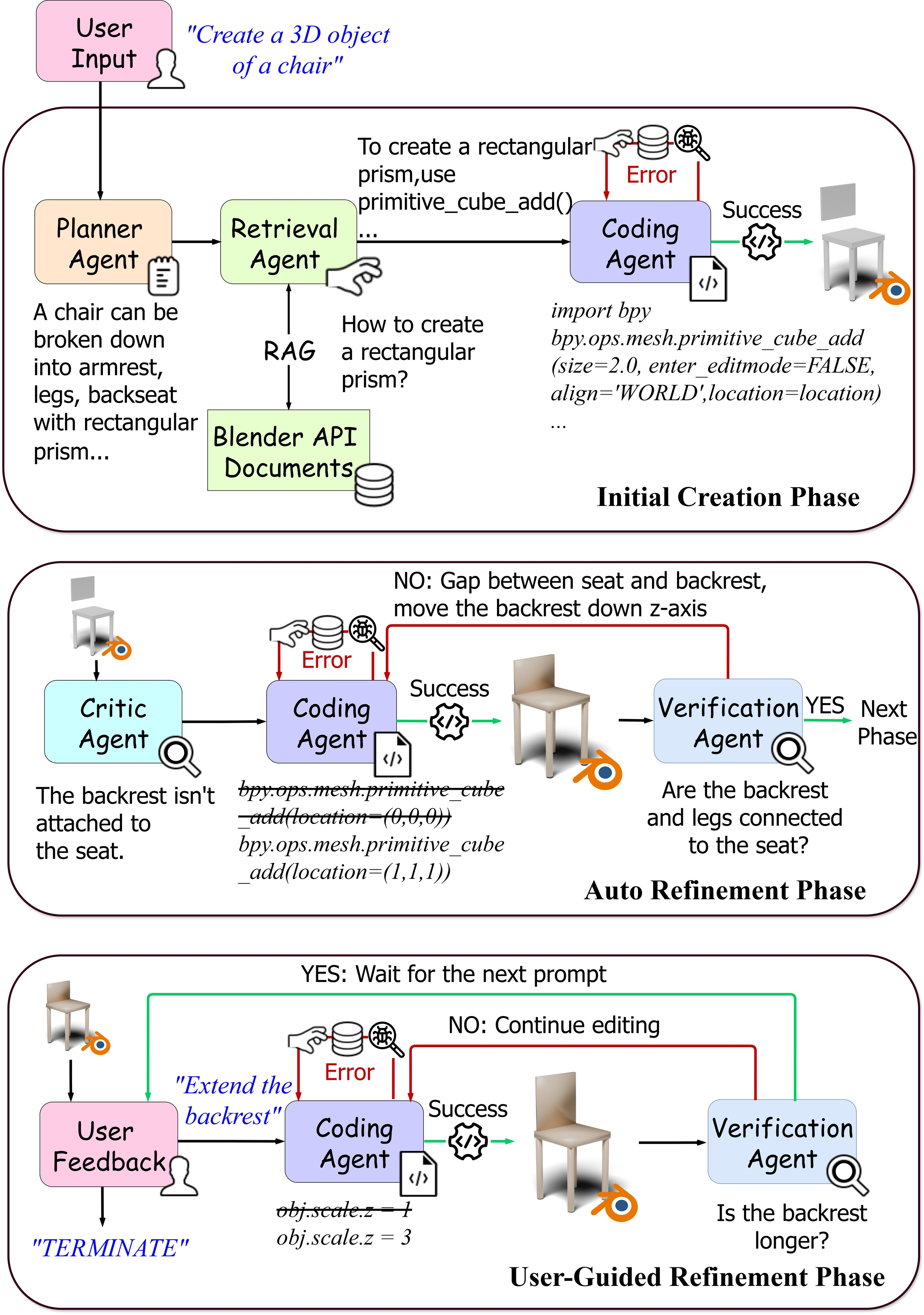
Figure 2: Method overview showing the multi-agent pipeline for initial creation, automatic refinement, and user-guided refinement.
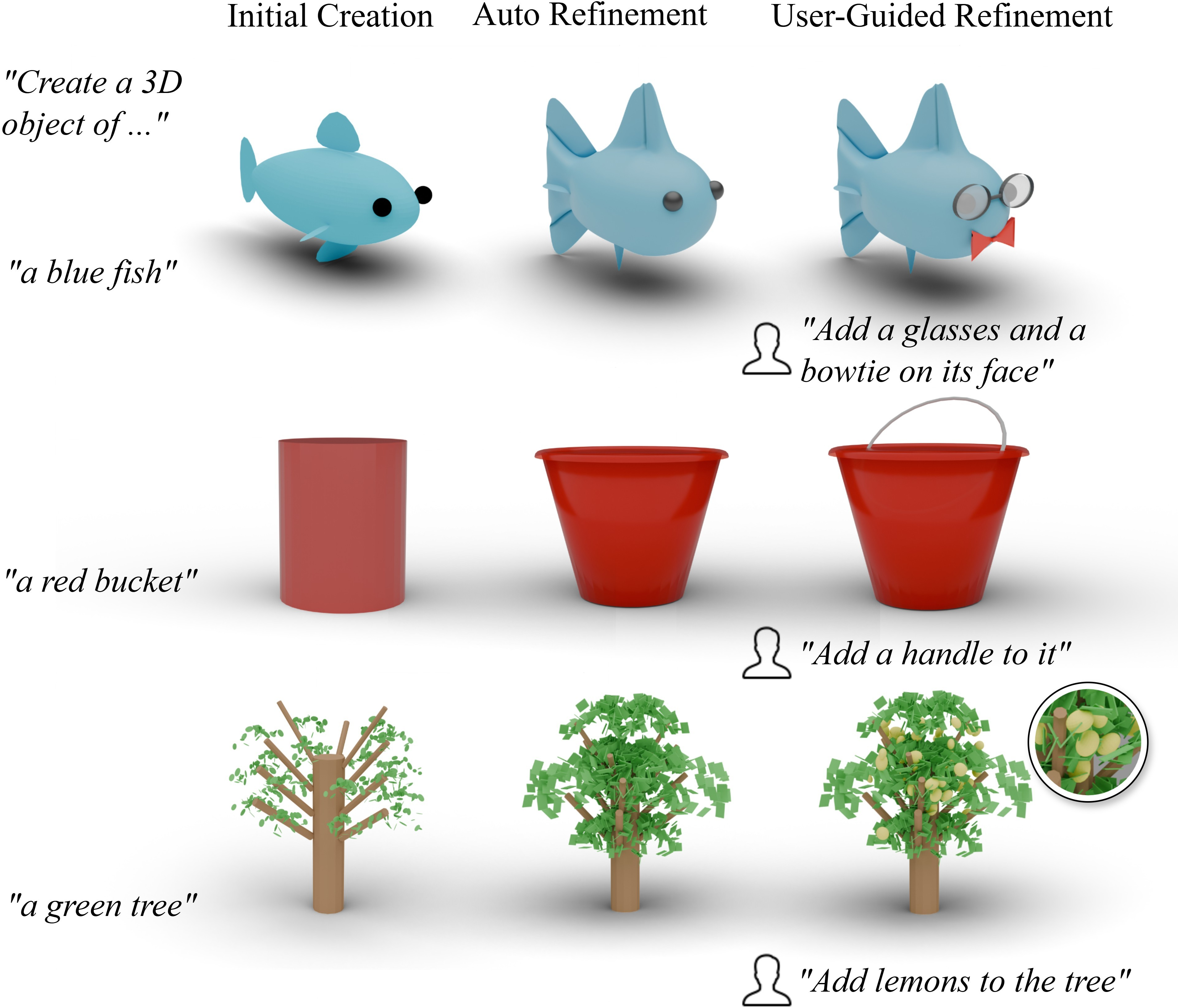
Figure 3: Intermediate results for each phase, demonstrating iterative mesh refinement and targeted edits.
Key Technical Innovations
Code as a Generative Medium
LL3M's central innovation is representing 3D assets as modular, human-readable Blender code. This enables:
Retrieval-Augmented Generation (BlenderRAG)
BlenderRAG injects version-specific Blender API documentation into the agent workflow, enabling the coding agent to utilize advanced Blender constructs (B-meshes, geometry nodes, shader nodes) and reducing execution errors. Quantitative analysis shows a 5× increase in complex operations and a 26% reduction in error rate with BlenderRAG.
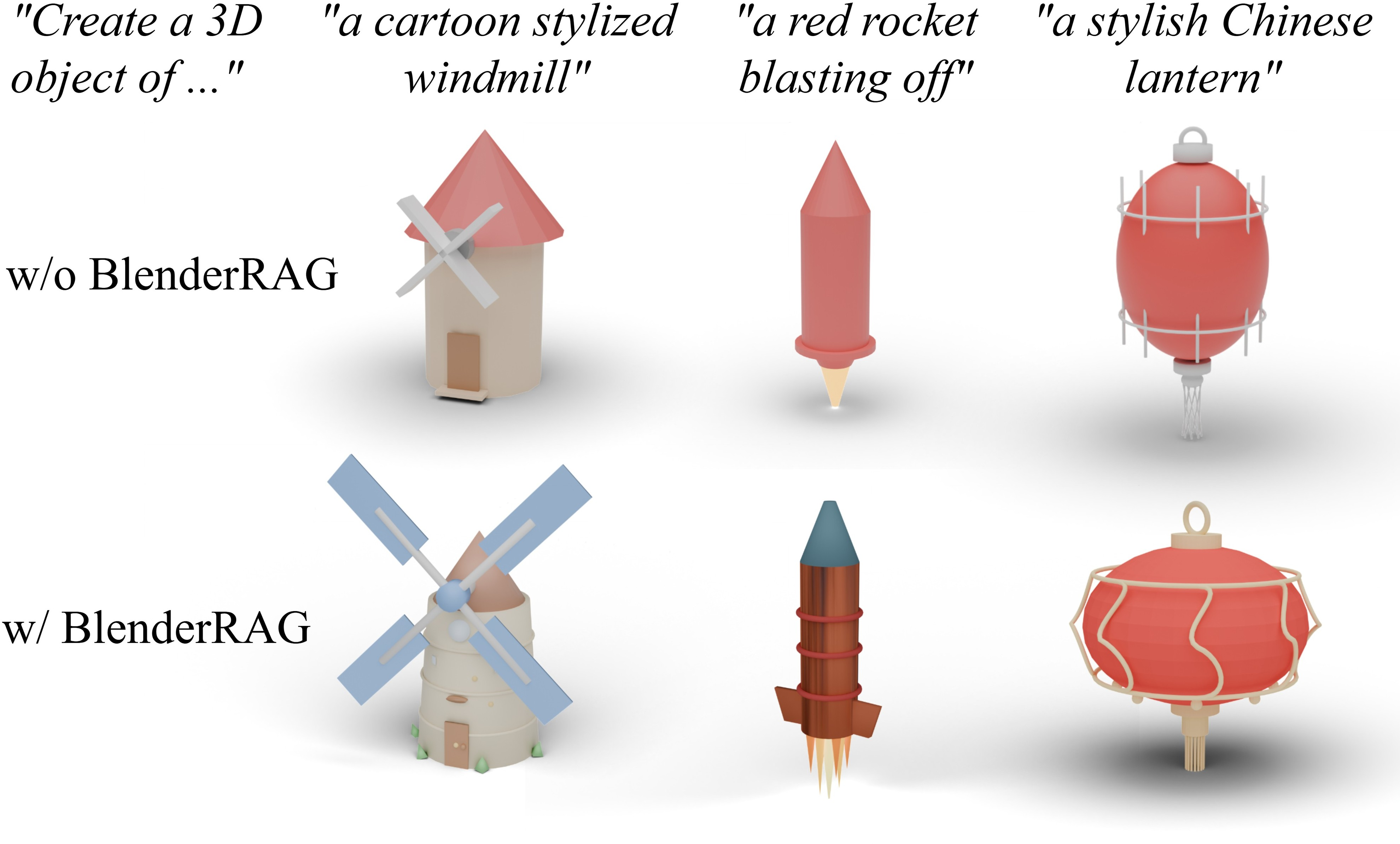
Figure 5: BlenderRAG enables the use of complex Blender functions, improving mesh quality and code sophistication.
Multi-Agent Collaboration and Context Sharing
Agents share a global context, allowing for coherent coordination and preservation of asset state across phases. The orchestrator manages agent order and communication, ensuring that edits are incremental and targeted rather than wholesale regenerations.
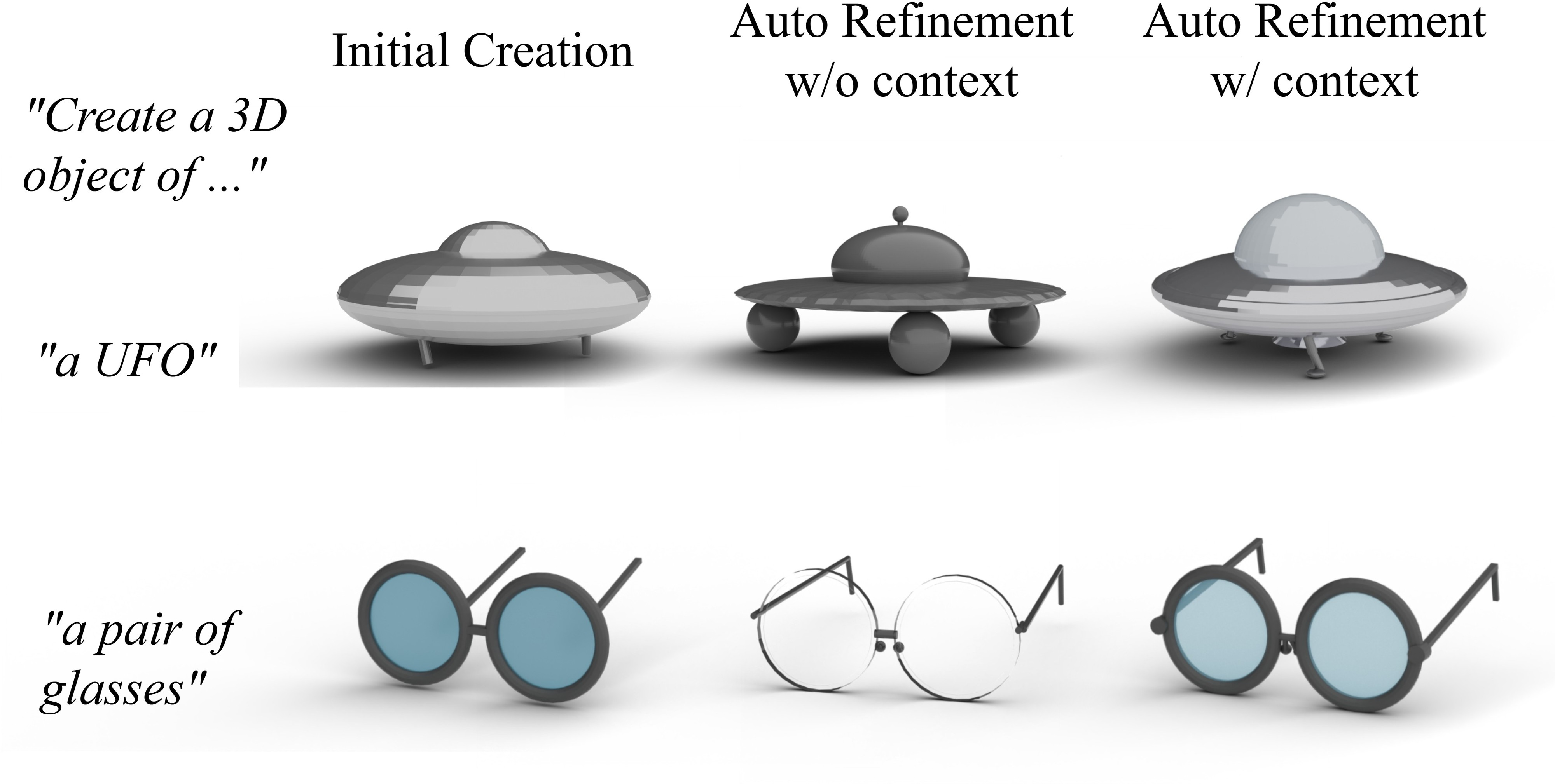
Figure 6: Context sharing across agents preserves and improves assets through iterative refinement.
Visual Critique and Verification
The critic and verification agents leverage VLMs to provide automatic visual feedback and ensure that code modifications align with user intent and prompt specifications. This loop enables high fidelity to input and robust error correction.
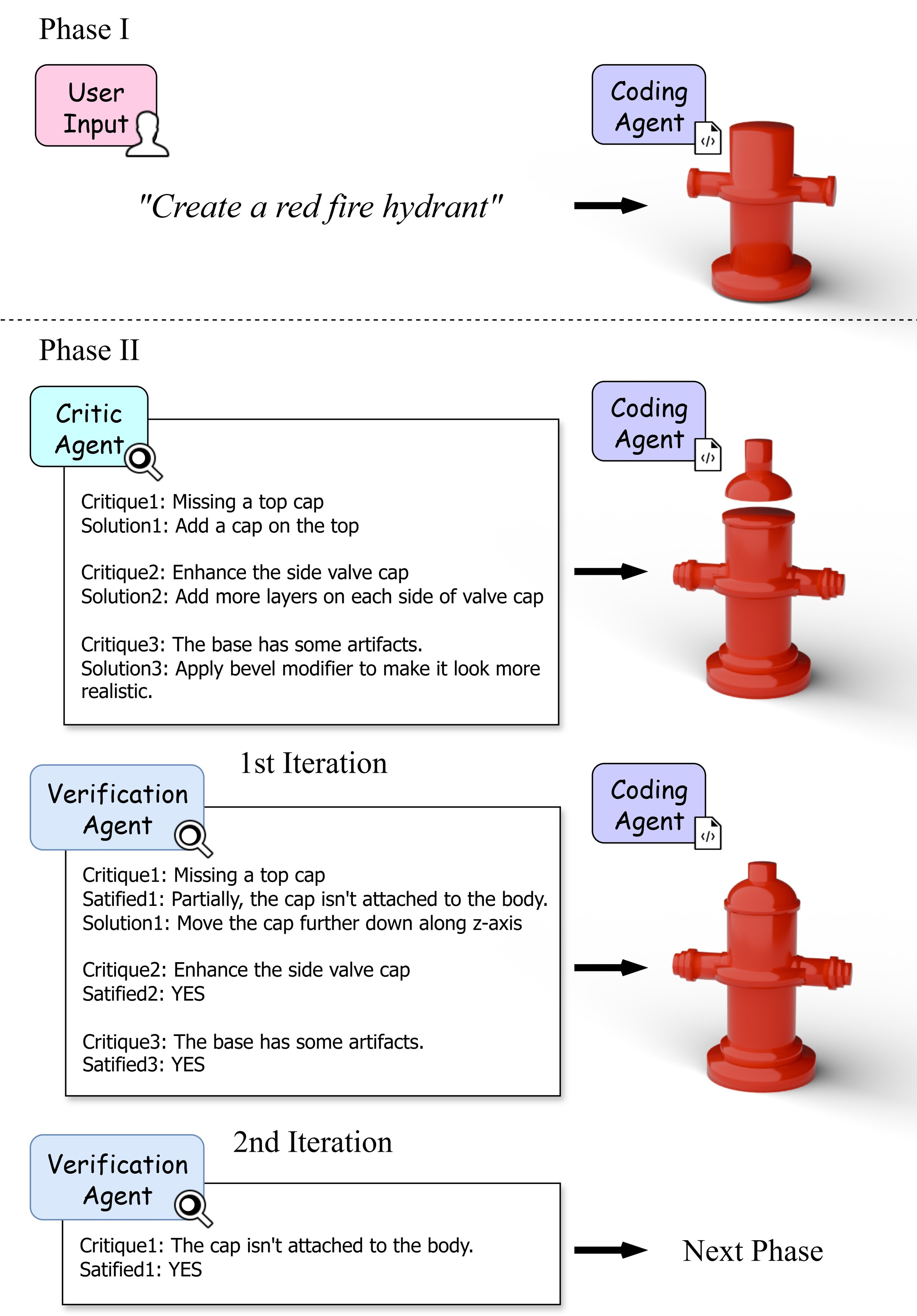
Figure 7: Verification agent ensures that all critiques are addressed, requiring multiple iterations if necessary.
Empirical Results and Evaluation
Generality and Versatility
LL3M demonstrates the ability to generate assets across a wide range of categories (vehicles, instruments, animals, scenes) with detailed geometry, textures, materials, and hierarchical relationships.
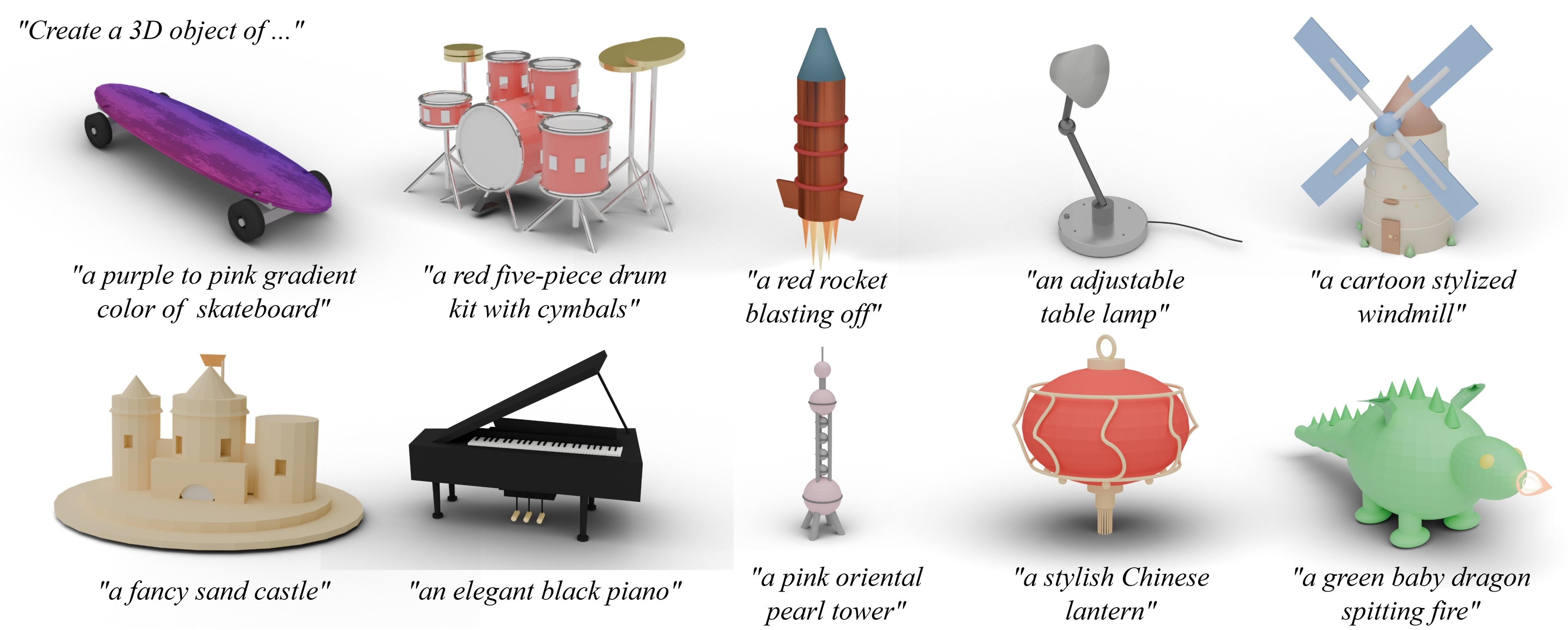
Figure 8: Gallery of results showcasing diverse, detailed, and editable 3D assets generated via Blender code.
Fidelity and Iterative Creation
The system exhibits high fidelity to user prompts, with the auto-refinement phase correcting implausible configurations and the user-guided phase enabling precise, iterative edits. Approximately 59% of user edits are achieved with a single instruction; more complex spatial edits require 3–4 follow-up prompts.

Figure 9: Iterative creation allows for successive, targeted edits while preserving asset identity.
Material and Stylization Edits
LL3M supports both geometric and material modifications, as well as high-level stylization instructions, applied consistently across different initial meshes.

Figure 10: Material editing via procedural shader nodes enables localized appearance changes.

Figure 11: Consistent stylization across assets in response to high-level style prompts.
Scene Generation and Hierarchical Structure
The system can generate multi-object scenes with appropriate spatial relationships and logical parenting, supporting scene graph behavior in Blender.
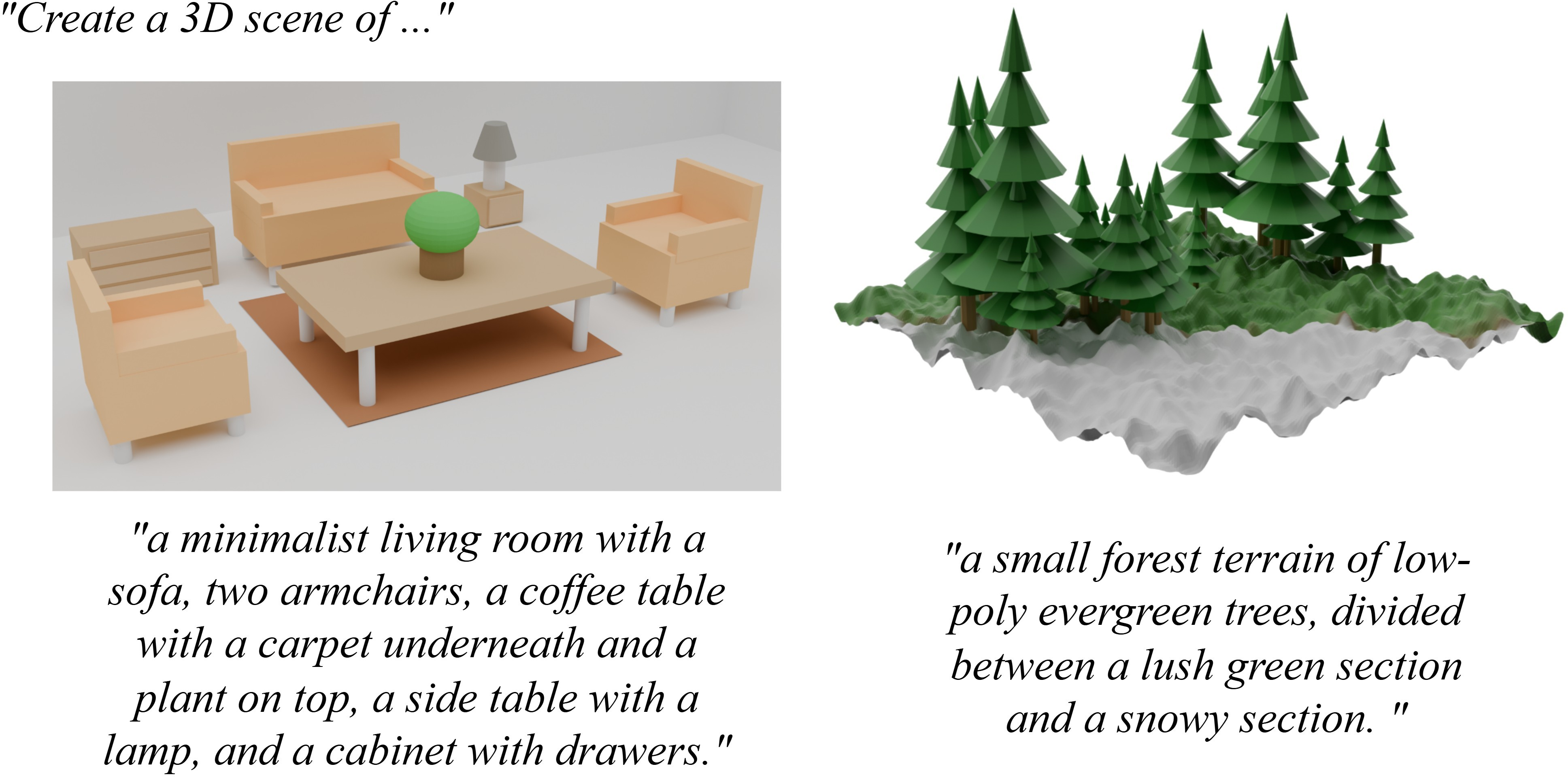
Figure 12: Scene generation with instancing and parenting relationships for hierarchical structure.
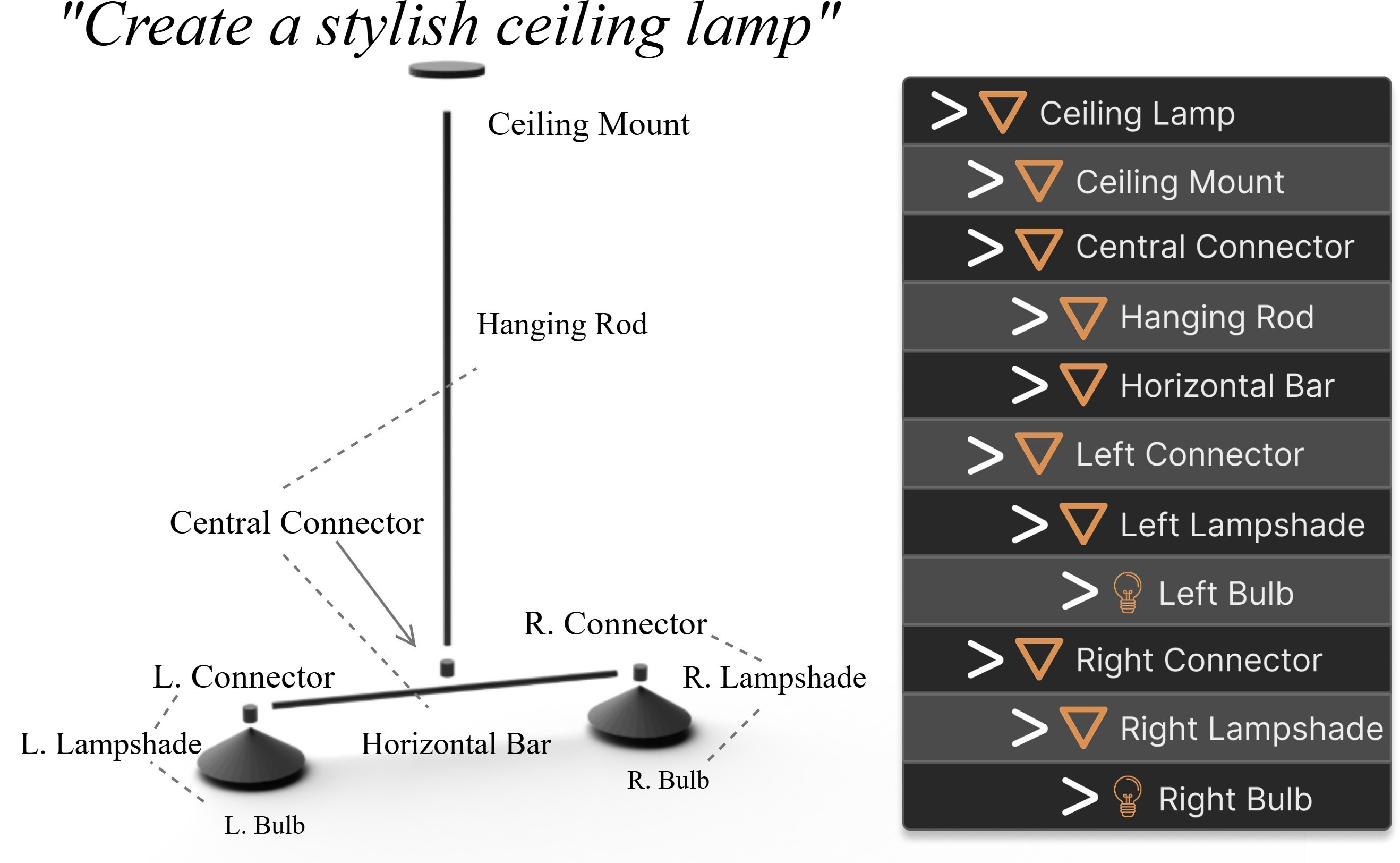
Figure 13: Hierarchical scene graph with semantic naming and parent-child relationships.
Baseline Comparison and Ablation
Compared to BlenderMCP, LL3M produces higher-quality meshes with richer details and greater alignment to input prompts. Ablation studies confirm the necessity of each agent for optimal asset quality.
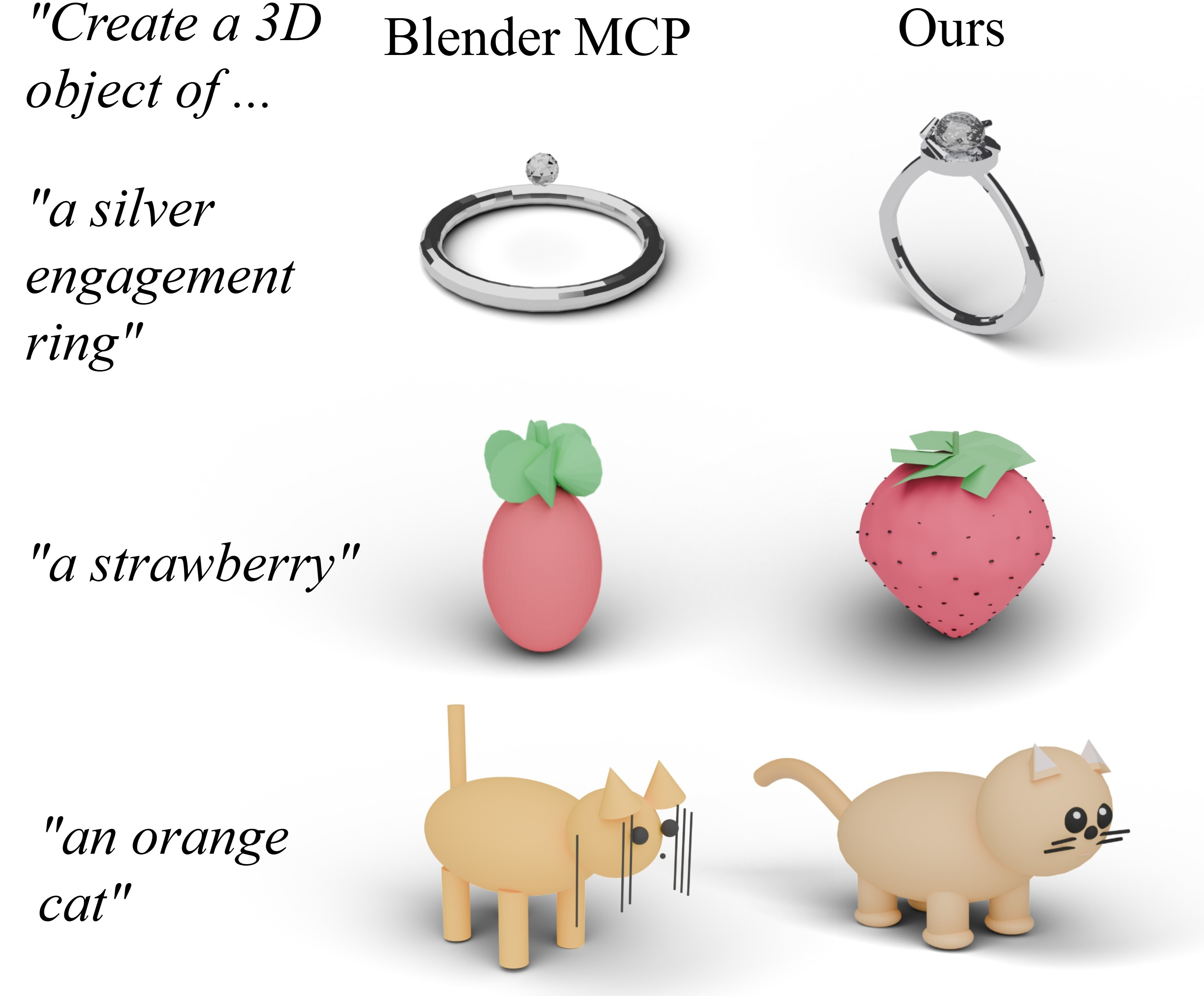
Figure 14: Baseline comparison showing superior mesh quality and detail in LL3M outputs.

Figure 15: Ablation study demonstrating progressive improvement with the addition of each agent.
Implementation Details
- Framework: Implemented in AutoGen, with agent orchestration and context sharing.
- Blender Version: 4.4, with BlenderRAG constructed from 1,729 documentation files.
- LLMs: GPT-4o (planner, retrieval), Claude 3.7 Sonnet (coding), Gemini 2.0 flash (critic, verification).
- Runtime: Initial creation ≈ 4 min, auto-refinement ≈ 6 min, user edits ≈ 38 sec per instruction.
Limitations and Future Directions
LL3M relies on the accuracy of VLMs for visual feedback, which may miss subtle spatial artifacts. However, user-driven iterative refinement can correct residual errors. The system is adaptable to future Blender versions via updates to BlenderRAG. Potential future work includes integrating more advanced VLMs, expanding multi-modal input capabilities, and optimizing agent collaboration for reduced latency.
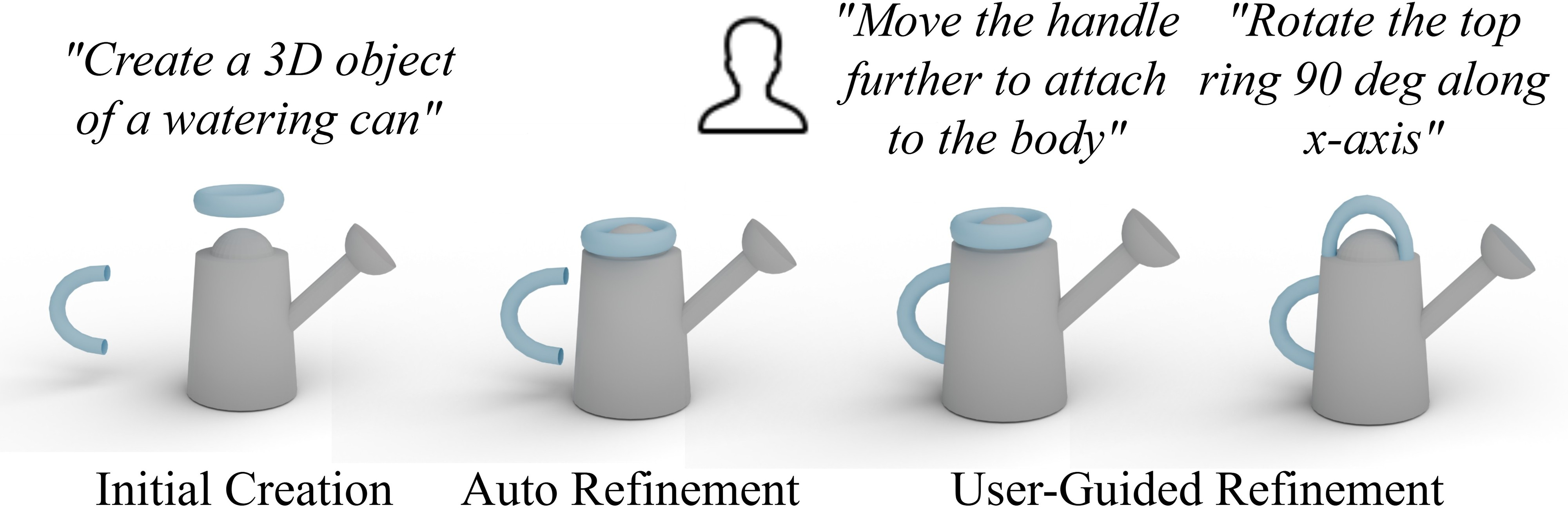
Figure 16: Limitations in automatic visual feedback can be overcome by user-supplied corrections.
Conclusion
LL3M establishes a robust framework for interpretable, modular 3D asset generation via multi-agent LLM collaboration. By representing assets as editable Blender code and leveraging retrieval-augmented generation, the system achieves generalization, fidelity, and user-driven co-creation without the constraints of category-specific models or low-level mesh representations. The approach bridges automation and creative control, offering a transparent and extensible solution for 3D modeling in graphics pipelines and artist workflows. Future developments may further enhance multi-modal capabilities, agent reasoning, and integration with evolving graphics software.
