- The paper introduces PEEK, a method that efficiently probes LLM knowledge by adapting pre-trained embeddings instead of using costly direct queries.
- It leverages techniques like sentence and graph embeddings with proxy tuning (e.g., low-rank and linear tuning) to predict factual accuracy.
- Experimental results show high performance with up to 91% accuracy and 88% AUC, demonstrating the approach's scalability and efficiency.
Efficient Knowledge Probing of LLMs by Adapting Pre-trained Embeddings
Introduction
The paper "Efficient Knowledge Probing of LLMs by Adapting Pre-trained Embeddings" proposes a novel approach to probing knowledge in LLMs by using Proxy Embeddings to Estimate Knowledge (PEEK). This method leverages pre-trained embedding models to determine which facts are known by LLMs without requiring multiple forward passes through the model. LLMs have emerged as general-purpose knowledge bases, yet their stochastic learning objectives obscure their learned knowledge landscapes. Existing knowledge probing techniques often necessitate computationally expensive operations and access to the model's internal states, limiting their scalability.
PEEK addresses this challenge by adapting existing embedding representations to predict LLM knowledge, offering a scalable and efficient alternative to traditional probing methods.
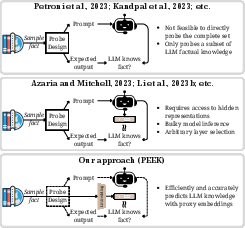
Figure 1: Comparison of our proposed approach, Proxy Embeddings to Estimate Knowledge (PEEK) with other knowledge probing approaches.
Methodology
PEEK capitalizes on the capabilities of embedding models to predict LLM knowledge through several key steps:
- Knowledge Probing Functions: The approach employs four distinct probing functions to determine LLM knowledge:
- Binary Generation: Simply asks whether a statement is true or false.
- Binary Logits Generation: Extracts the logits of expected tokens for a given prompt.
- Binary Activation Prediction: Utilizes hidden representations to predict if a fact is true.
- Fact Generation: Leverages existing datasets to determine if the LLM-supported facts are accurate.
- Proxy Embeddings: The foundation lies in embedding models, including:
- Proxy Tuning: This involves refining embedding models using techniques such as Low-rank tuning and Linear tuning to align them with LLM predictions. The adapted embeddings then serve as proxies for estimating LLM knowledge without querying the LLM directly.
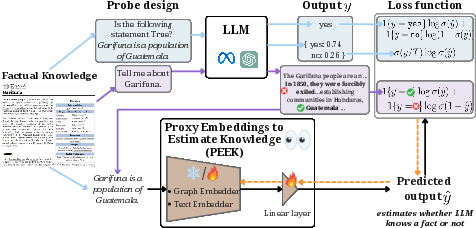
Figure 2: Proxy Embeddings to Estimate Knowledge (PEEK): In this framework, pre-trained embedding models are adapted to match the LLM knowledge for a training set of facts identified using different probing mechanisms. On a held-out set, we can then predict whether an LLM knows a fact or not by using the fact's embedding.
Experimental Setup
The experiments evaluate PEEK on various datasets, including DBP100k and YAGO310, downsampled to control complexity and focus on positive facts. A range of embedding models was tested for knowledge estimation, and several LLMs, such as GPT-4o, GPT-4o-mini, and Llama models, were used to benchmark the efficacy of PEEK.
Metrics such as Accuracy (ACC) and Area Under the ROC Curve (AUC) for binary tasks, and Mean Absolute Error (MAE) for continuous predictions, quantify performance.
Results and Analysis
- Binary Generation: High performance with up to 91% accuracy and 88% AUC was achieved using sentence embeddings, verifying the effectiveness of PEEK compared to more traditional hidden representation methods.

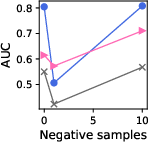
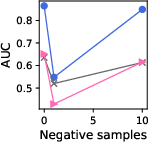
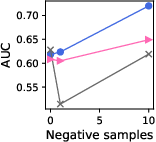
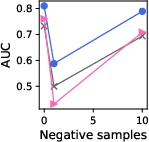
Figure 3: Effect of changing the number of negative samples in GPT models for knowledge graphs.
- Negative Sampling & Fine Tuning: Results indicate that models generally perform better with increased negative samples, reflecting natural class imbalances. Furthermore, linear tuning was competitive with more complex LoRA tuning, suggesting minimal fine-tuning is sufficient.

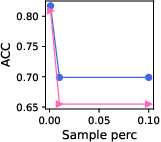
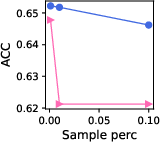
Figure 4: Effect of changing the number of negative samples in Llama3.1-8B for knowledge graphs.
Conclusion
This research introduces PEEK as a scalable method to probe LLM knowledge efficiently. By adapting pre-trained embeddings, PEEK provides an avenue to assess knowledge without requiring costly computations linked with direct LLM querying. Future directions could explore how these proxy embeddings dynamically adapt as LLMs evolve and expand their knowledge bases. Additionally, understanding the implications of embedding-based knowledge probing on the continual learning and updating of LLMs could be a significant area of further research.

