- The paper introduces an autonomous multi-agent framework that transforms single-cell multi-omics data into executable virtual cell models.
- It employs a graph-based expert discussion to synthesize innovative model architectures, outperforming state-of-the-art baselines.
- Experimental evaluations show up to 40% error reduction and robust generalization across gene, drug, and cytokine perturbations.
Agentic Design and Automated Implementation of Virtual Cell Models with CellForge
Introduction
CellForge introduces a fully autonomous, agentic system for the design and implementation of virtual cell models, specifically targeting the prediction of single-cell responses to diverse perturbations. The framework leverages a multi-agent architecture that transforms raw single-cell multi-omics data and natural language task descriptions into optimized, executable computational models. The system is structured into three core modules: Task Analysis, Method Design, and Experiment Execution, each orchestrated by specialized agents that collaborate through a shared memory protocol. This essay provides a detailed technical summary of the CellForge framework, its methodological innovations, empirical performance, and implications for the future of AI-driven scientific discovery.
CellForge addresses the challenge of predicting cellular responses to perturbations—such as gene knockouts, drug treatments, and cytokine stimulations—across multiple single-cell modalities (scRNA-seq, scATAC-seq, CITE-seq). The task is formalized as learning a mapping from a control cell state and perturbation condition to the resulting perturbed state in a high-dimensional gene expression space. The system is designed to generalize to unseen perturbations and cell states, requiring robust inductive reasoning and dataset-specific adaptation.
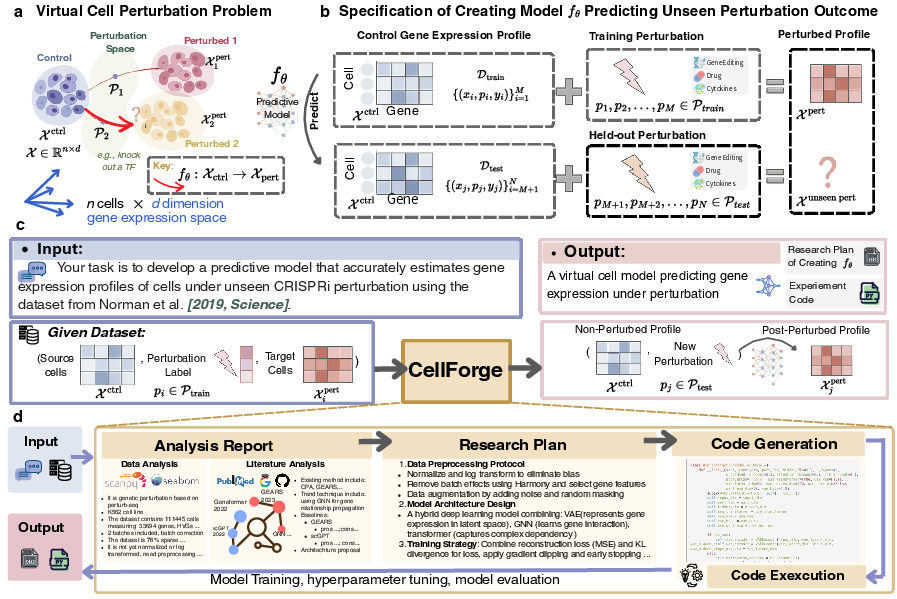
Figure 1: (a) Virtual cell modeling as a perturbation mapping problem; (b) Training and prediction for unseen perturbations across modalities; (c) CellForge input/output interface; (d) Core intermediate outputs from analysis to code generation.
The architecture of CellForge is organized into three sequential phases:
- Task Analysis: Automated dataset characterization, literature retrieval, and extraction of task-specific constraints.
- Method Design: Collaborative, graph-based expert discussion to synthesize novel model architectures and research plans.
- Experiment Execution: Automated code generation, training, validation, and iterative refinement.
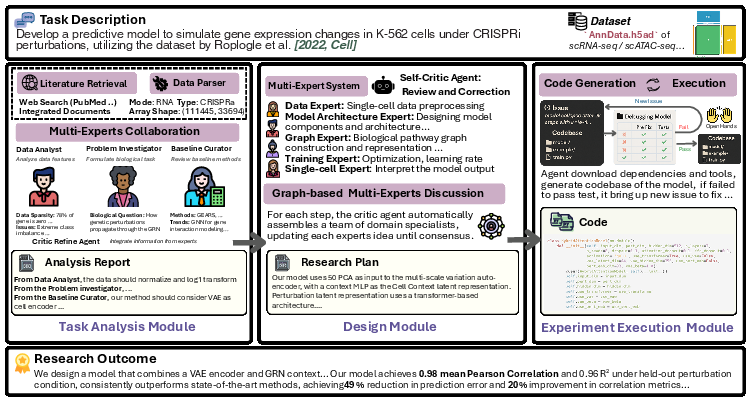
Figure 2: The CellForge architecture and workflow, illustrating the sequential phases and shared memory communication.
Task Analysis Module
The Task Analysis module integrates dataset profiling, literature-driven retrieval, and agentic collaboration. The Data Parser standardizes metadata across modalities, while the retrieval system combines a static corpus with dynamic PubMed and GitHub search, employing an alternating BFS/DFS strategy with Sentence-BERT embeddings for relevance scoring. Three specialized agents—Dataset Analyst, Problem Investigator, and Baseline Assessor—process the retrieved information, producing a structured analysis report that informs downstream model design.
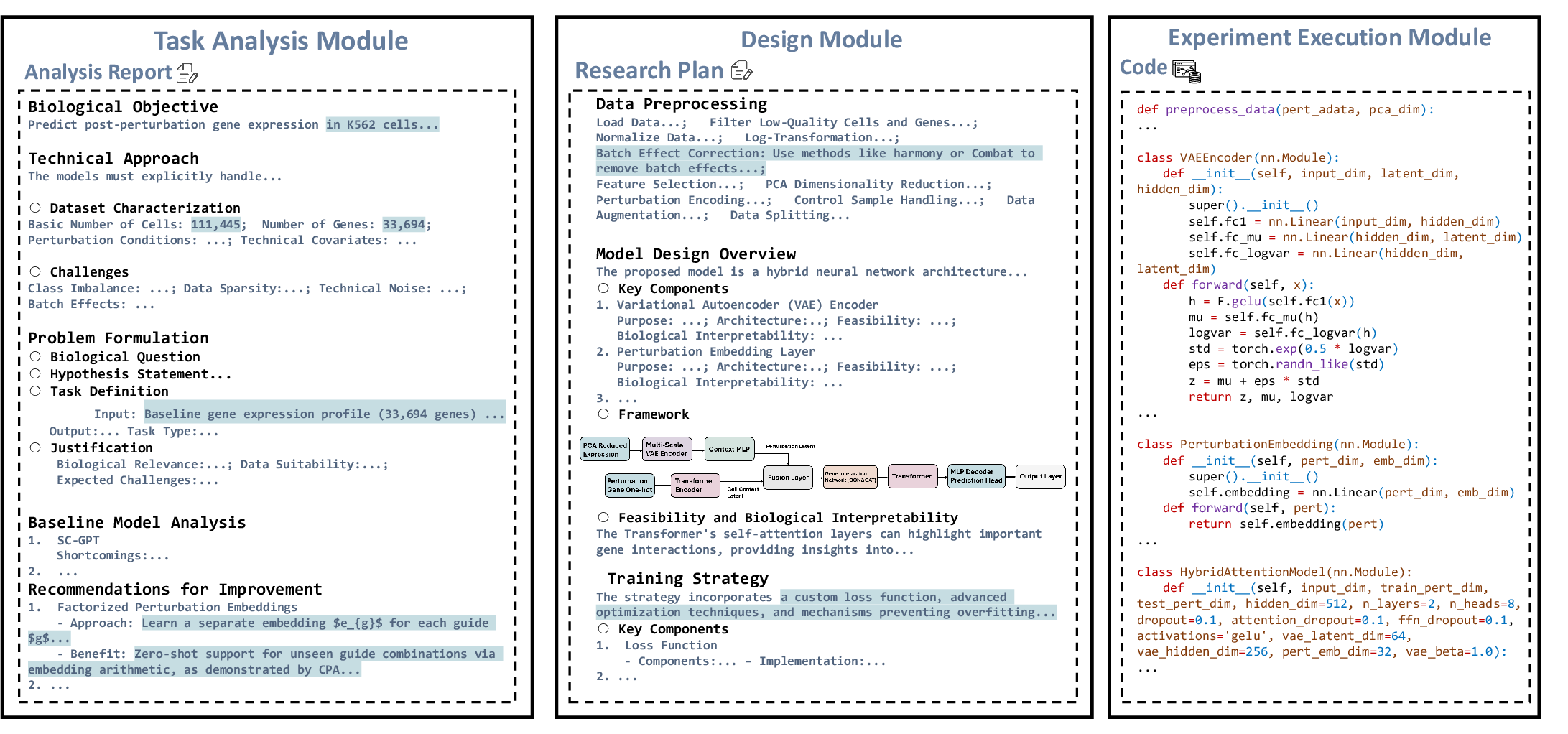
Figure 3: Example outputs from the three modules: analysis report, research plan, and code snippets.
Method Design: Multi-Expert Graph-Based Discussion
The Method Design module employs a graph-based, multi-agent discussion framework. Domain experts (e.g., Data, Model Architecture, Deep Learning, Pathway, Training) are instantiated via role-specific prompts and engage in iterative rounds of proposal, critique, and refinement. Each expert maintains a confidence score, updated via a weighted combination of historical confidence, critic agent evaluation, and peer feedback. The discussion terminates upon consensus or after a fixed number of rounds, yielding a research plan with detailed model architecture, preprocessing, and training strategies.
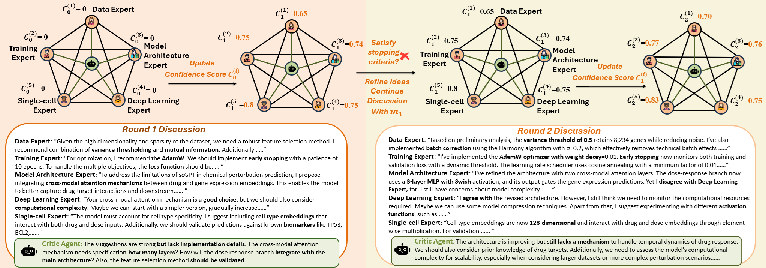
Figure 4: Graph-based discussion workflow, showing iterative expert proposal refinement and confidence score updates.

Figure 5: Example of confidence score evolution for a domain expert during multi-round discussion.
The architectural search is not limited to hyperparameter tuning but focuses on emergent, dataset-specific model design. The system frequently converges on hybrid architectures (e.g., VAE + GNN + Transformer) tailored to the biological and technical characteristics of each dataset.
Experiment Execution: Automated Code Generation and Validation
The Experiment Execution module translates the research plan into executable code, orchestrating training, validation, and iterative refinement. The code generator produces production-ready scripts, with self-debugging capabilities that handle syntax and runtime errors via event stream analysis. Training is managed with best-practice safeguards (early stopping, cross-validation, adaptive learning rates), and validation agents monitor performance metrics (MSE, PCC, R2), triggering hyperparameter tuning or retraining as needed.
CellForge was evaluated on six benchmark datasets spanning gene knockouts, drug treatments, and cytokine stimulations across scRNA-seq, scATAC-seq, and CITE-seq modalities. The models designed by CellForge consistently outperformed state-of-the-art baselines, achieving up to 40% reduction in prediction error and 20% improvement in correlation metrics. Notably, on the challenging scATAC-seq dataset, CellForge achieved a ~16-fold gain in Pearson correlation on differentially expressed genes compared to linear regression.
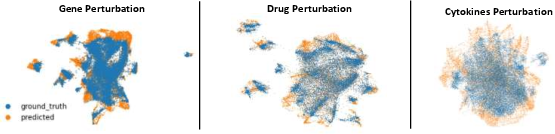
Figure 6: UMAP visualizations of predicted and ground truth gene expression profiles under gene knockout, drug, and cytokine perturbations, demonstrating high fidelity in capturing cellular state distributions.
CellForge also demonstrated strong performance in recovering differentially expressed genes (DEGs), with recall rates exceeding 69% and ROC-AUC values above 0.65 on well-characterized genetic perturbation datasets. The system's ability to generalize to unseen perturbations and modalities was validated through stratified cross-validation and held-out perturbation scenarios.
Ablation and Component Analysis
Ablation studies revealed that both the agentic retrieval system and the graph-based expert discussion are critical for performance. The combination of these components yielded synergistic effects, with performance gains far exceeding their individual contributions. The system's robustness was further demonstrated by stable performance across all perturbation types and modalities.
LLM and Human Evaluation
CellForge's outputs were evaluated by both LLM-based judges and human experts across multiple scientific dimensions (validity, feasibility, innovation, experimental design, impact). The system consistently outperformed DeepResearch variants and single-LLM baselines, with strong alignment between agent confidence scores, LLM, and human expert evaluations.
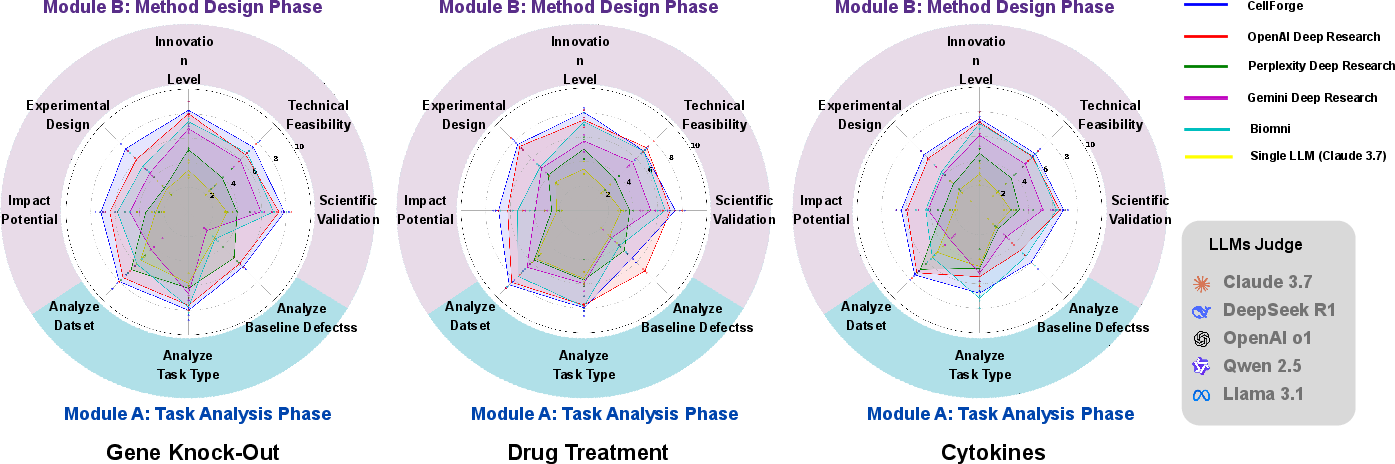
Figure 7: Comparative evaluation of CellForge and DeepResearch variants by LLM judges across key scientific dimensions.
Architectural Adaptation and Model Diversity
Post-hoc analysis of the architectures designed by CellForge revealed emergent, biologically plausible model-task pairings. Transformers dominated cytokine data, GNNs were favored for regulatory network-rich datasets, and hybrid or novel variants emerged through agentic debate and literature integration.
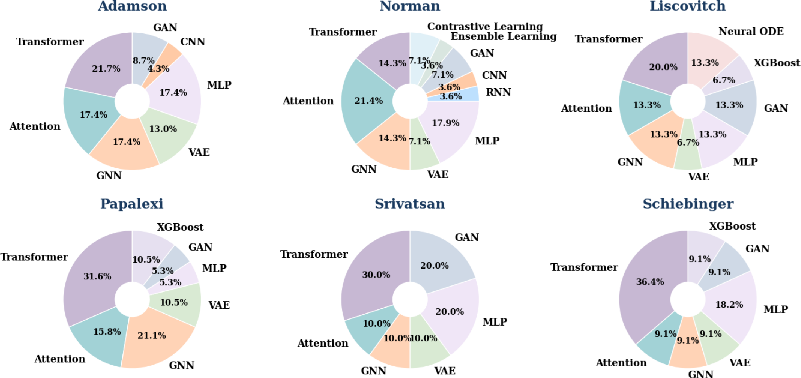
Figure 8: Categorization and quantification of architectures designed by CellForge across six datasets.
Failure Modes and Resource Considerations
The most common failure modes were computation execution errors (41%), primarily due to tensor operation issues, and invalid type/operation errors (23%). The system incorporates self-debugging strategies, such as dynamic shape printing and error recovery, to mitigate these issues. Training infrastructure requirements are moderate (2x NVIDIA H20 GPUs, 16-core CPU, 150 GB RAM), with average per-experiment costs of \$5–\$20, significantly lower than manual expert labor.
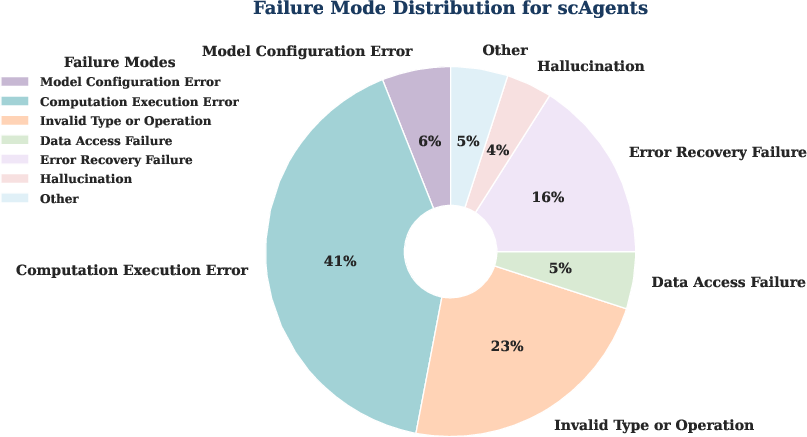
Figure 9: Distribution of failure modes in CellForge, highlighting the prevalence of computation and type errors.
Implications and Future Directions
CellForge demonstrates that autonomous, multi-agent systems can effectively integrate computational, biological, and statistical expertise to design and implement optimized models for complex scientific tasks. The framework's architecture-agnostic, literature-grounded, and collaborative reasoning approach enables adaptation to new modalities and tasks without manual intervention. The strong empirical results and robust evaluation suggest that agentic systems can serve as foundational tools for next-generation virtual cell modeling and, more broadly, for automated scientific discovery in data-rich domains.
Future developments may focus on extending CellForge to additional omics modalities (spatial transcriptomics, proteomics), enhancing novelty detection for de novo biological mechanisms, and integrating prospective wet-lab validation. The system's modular design and open-source availability facilitate community-driven improvements and cross-domain adaptation.
Conclusion
CellForge represents a significant advance in the automation of scientific model design, integrating agentic reasoning, domain knowledge retrieval, and collaborative architecture synthesis into a unified, end-to-end framework. Its consistent outperformance of state-of-the-art baselines, robust generalization across modalities, and alignment with human expert judgment underscore the potential of multi-agent AI systems to accelerate and democratize scientific discovery. The methodological innovations in agentic retrieval, graph-based expert discussion, and automated code generation provide a blueprint for future AI-driven research platforms in computational biology and beyond.