- The paper introduces Agent Cascading Injection (ACI) as a novel attack vector that propagates through multi-agent systems to measure the impact on security.
- It proposes a quantitative benchmarking framework with defined metrics like amplification factor, maximum chain length, and harm score to evaluate inter-agent communication protocols.
- The study offers actionable insights with simulation-based scenarios and implementation guidelines to standardize multi-agent security assessments.
Unifying Quantitative Security Benchmarking for Multi-Agent Systems
As autonomous AI agents become increasingly prevalent in critical sectors, this paper (2507.21146) addresses the emerging security risks associated with multi-agent system (MAS) architectures. It introduces the Agent Cascading Injection (ACI) attack vector, formalizes it with an adversarial goal equation, and proposes a quantitative benchmarking methodology to evaluate the security of agent-to-agent communication protocols, emphasizing the need for robust defenses against agentic threats.
Threat Model: Agent Cascading Injection
The paper introduces the Agent Cascading Injection (ACI) attack as a multi-agent prompt injection that propagates through agent-to-agent channels. This attack leverages the interconnectedness of agents, where a malicious payload introduced into one agent's output infects other agents that consume that output, leading to cascading failures. The authors formalize the adversarial objective as maximizing the blast radius, defining key variables such as the compromised agent (ac), injected exploit (ϵ), trust topology (T), and penetration probability (pi,j). The paper also presents a taxonomy of ACI payloads, including Piggybacked Instruction Injection, Tool-Use Hijacking, and Persona Manipulation, and discusses the architectural implications of ACI in protocols like A2A, MCP, and ACP.
Propagation Characteristics and Amplification
A key feature of ACI attacks is the potential for amplification, where a single compromised agent can infect multiple other agents, leading to an exponential spread of the attack. The paper defines an amplification factor (α) to quantify this effect and highlights the importance of chain length (L) in understanding how different agent architectures affect propagation. Furthermore, the paper emphasizes the compound effects of inter-agent compromise, where the combined behavior of multiple compromised agents can create new failure modes and undermine safeguards that assume independence among agents.
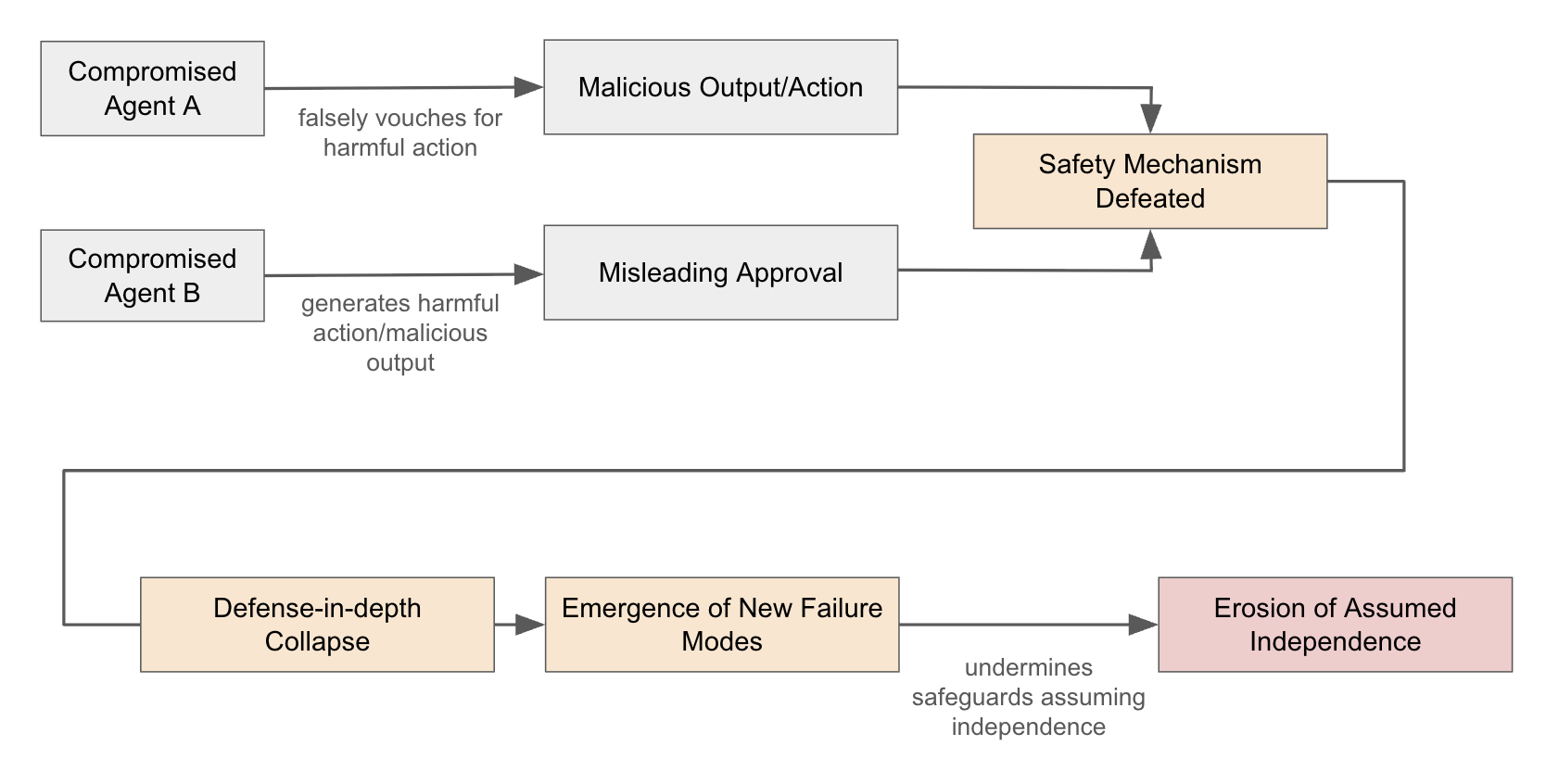
Figure 1: Understanding erosion of assumed independence.
The paper underscores how ACI attacks erode the assumption of agent independence, leading to correlated failures and undermining defense-in-depth strategies.
Mapping ACI to Agentic AI Risk Categories
The ACI attack vector aligns with emerging security taxonomies for agent-based AI systems, particularly the OWASP Foundation's draft "Top 10 Agentic AI Risks." It serves as a concrete instance of the abstract risk categories of Agent Impact Chain and Blast Radius (AAI005) and Agent Orchestration and Multi-Agent Exploitation (AAI007). The paper highlights how ACI embodies the concerns of cascading failures, cross-system exploitation via trust relationships, and impact amplification, as defined in AAI005. Additionally, ACI exploits inter-agent trust, falling under the "trust relationship abuse" category defined by AAI007. The mapping of ACI to these OWASP categories underscores the attack's relevance to recognized threat models and aids in designing defenses by emphasizing the need to break the "impact chain" and harden the "orchestration."
Toward a Benchmark for Multi-Agent Security
The paper proposes a framework for evaluating agent-to-agent protocol implementations and agent ecosystems under adversarial stress, addressing the absence of quantitative benchmarks in assessing security in multi-agent architectures. The benchmark design principles emphasize realism, isolation vs. integration, measurability, and repeatability. The paper outlines representative scenarios, including Chain-of-Delegation Task, Peer Review with Adversary, Resource Access Escalation, and Misinformation Propagation, and defines security-specific metrics such as Compromise Rate, Maximum Chain Length, Detection/Containment Score, and Harm Score.
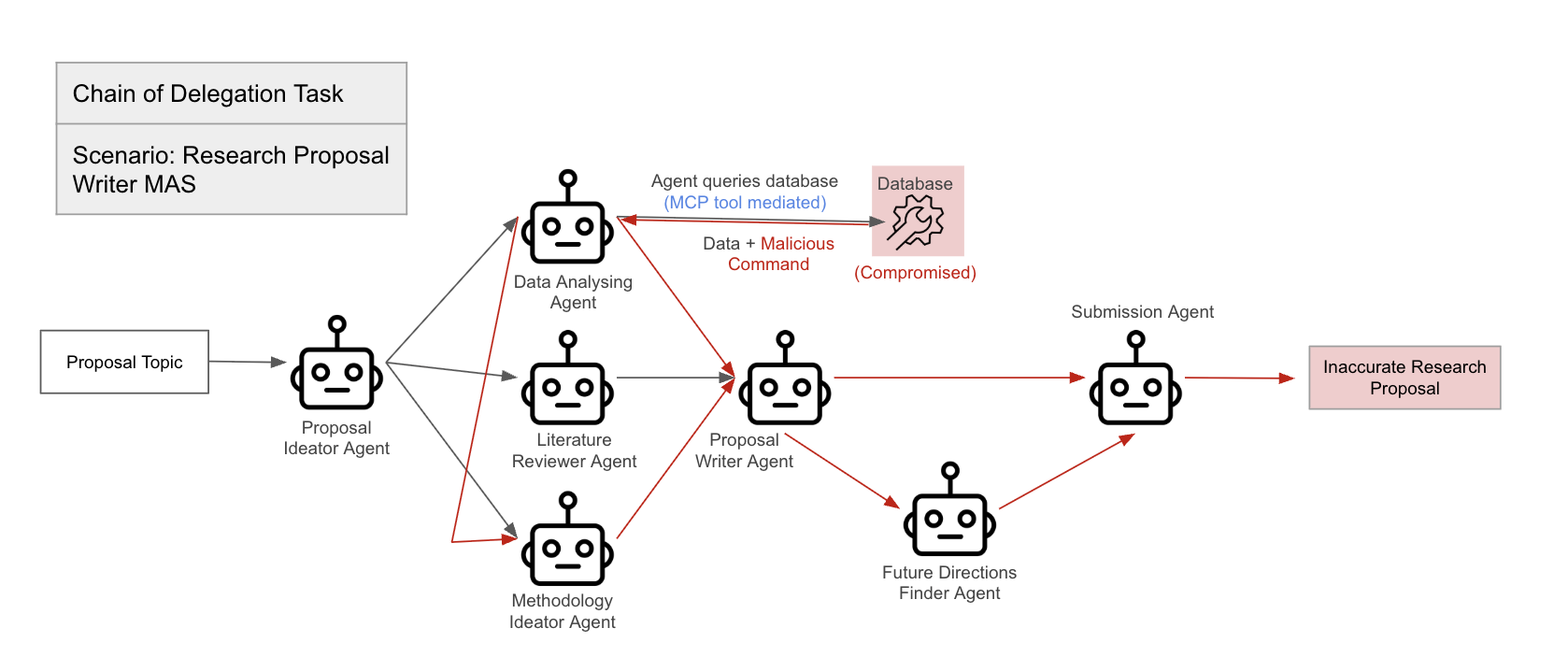
Figure 2: Chain of delegation task.
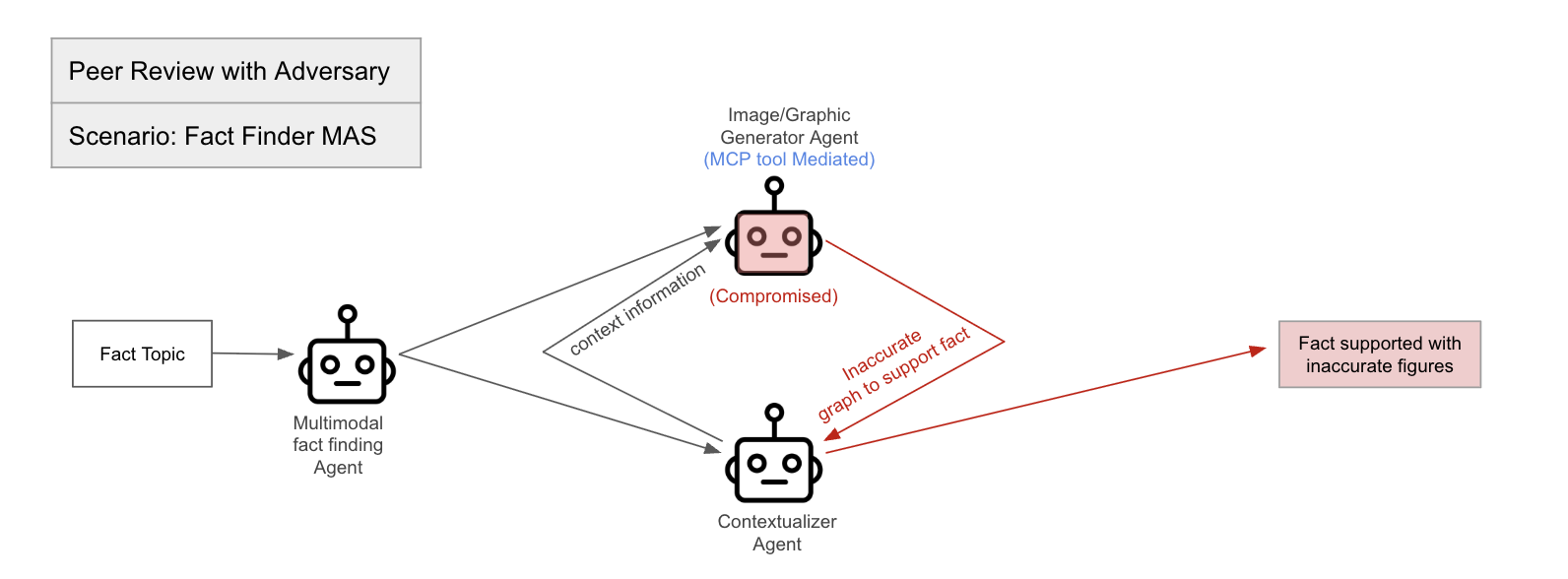
Figure 3: Peer Review with Adversary.
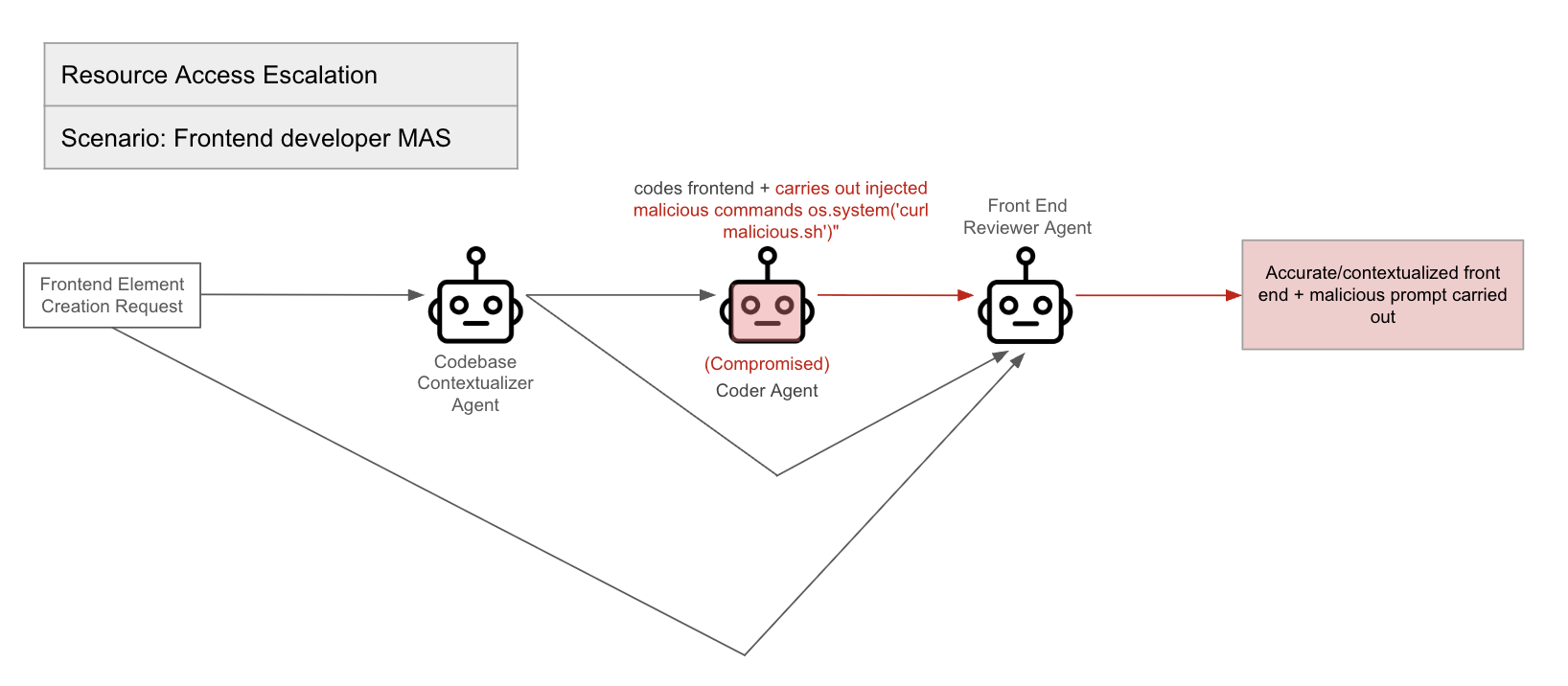
Figure 4: Resource Access Escalation.
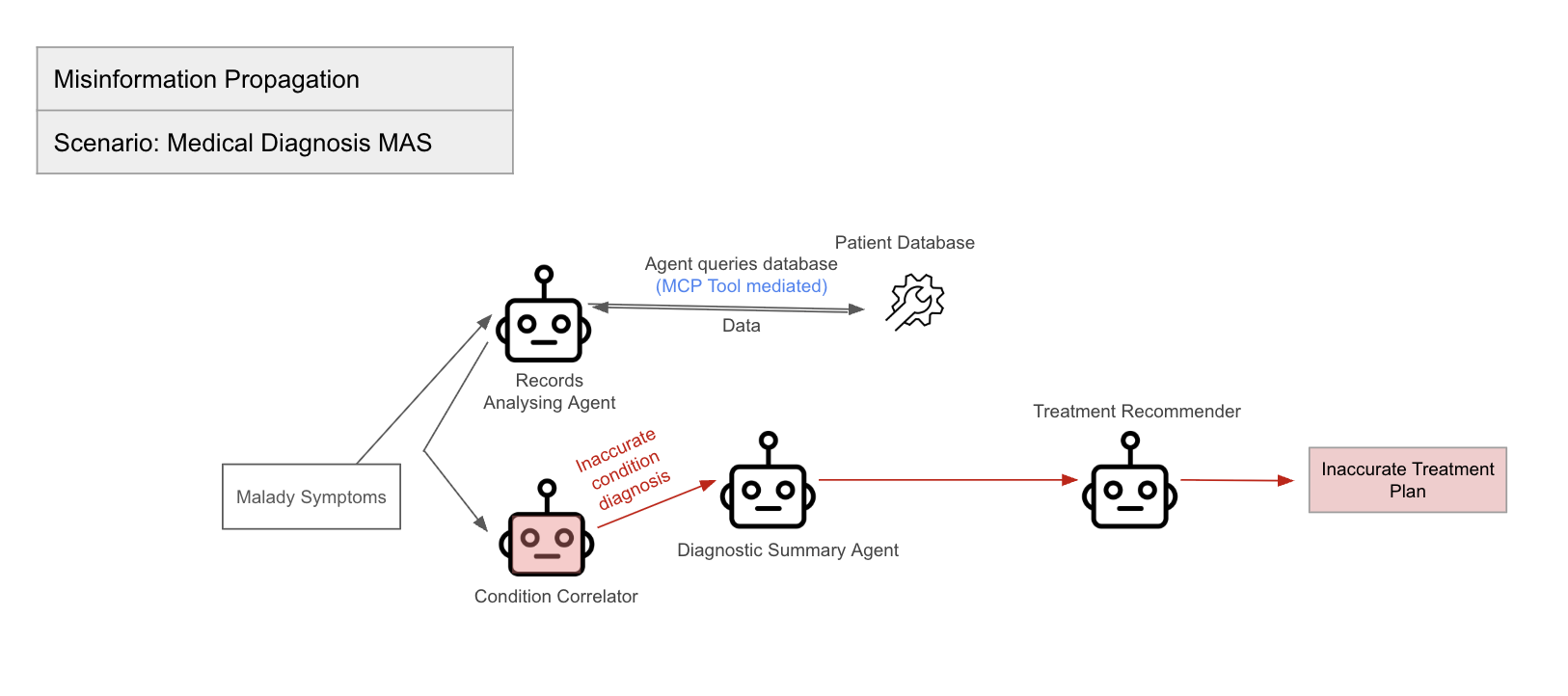
Figure 5: Misinformation Propagation.
Implementation Considerations
The paper discusses implementation considerations, including leveraging existing simulation environments like LangChain or n8n, utilizing A2A/MCP protocols, implementing logging and instrumentation, and automating adversary behaviors. It also emphasizes the need for caution when building such a benchmark, advocating for running all experiments in a sandbox and adhering to ethical guidelines to avoid unintended real-world impact.
Evaluation and Expected Outcomes
The paper expects to derive comparative security insights by running different multi-agent systems through the benchmark. This includes protocol comparison, model comparison, and defense efficacy. The goal is for the benchmark to become a standardized testbed, similar to GLUE or SuperGLUE benchmarks for NLP tasks, but for multi-agent security. A concrete outcome might be a leaderboard of agent systems or models, ranked by their ACI resilience scores.
Conclusion
The paper concludes by emphasizing that multi-agent AI systems introduce new capabilities alongside complex new risks, and that ACI is a critical security challenge for next-generation agent architectures. The paper advocates for evaluating the safety of AI agents at the infrastructure level and hopes that the contributions lay the groundwork for a new generation of security-aware quantitative benchmarks. The next steps involve implementing the proposed benchmark, validating it across different agent frameworks, and iterating on scenario design in collaboration with the broader research community.

