- The paper introduces CaliDrop to calibrate token eviction in KV caching, reducing memory usage without compromising accuracy.
- It employs a methodology based on query similarity and historical attention outputs to precompute and refine evicted token outputs.
- Extensive benchmarks demonstrate significant efficiency gains in LLMs, particularly in scenarios with limited cache sizes and long-context tasks.
CaliDrop: KV Cache Compression with Calibration
CaliDrop is an advanced strategy for compressing Key-Value (KV) caches in LLMs, specifically designed to overcome memory bottlenecks in scenarios involving lengthy inputs. This essay examines the technical components, empirical observations, and implications of the CaliDrop method, with an emphasis on theoretical insights and numerical results.
Introduction to Key-Value Caching in LLMs
LLMs are renowned for their capacity to process extensive texts via auto-regressive generation. One of the critical mechanisms to enhance computational efficiency is the use of KV caching, which prevents repeated calculation of attention intermediates. Unfortunately, the memory footprint of KV caches scales linearly with sequence length and model size, posing significant challenges for deployment, especially in long-context scenarios. Token eviction methods aim to alleviate this problem by removing tokens deemed non-critical, but often compromise accuracy when high compression ratios are demanded.
CaliDrop's Methodology
CaliDrop introduces a calibration-based enhancement to token eviction strategies. This is predicated on the observation that queries in adjacent positions typically have high similarity. Thus, CaliDrop employs speculative calibration to mitigate accuracy loss by precomputing attention outputs for evicted tokens via historical queries.
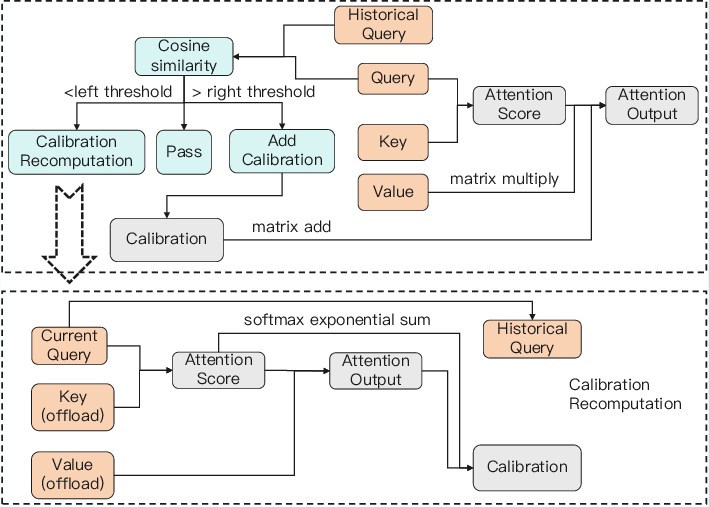
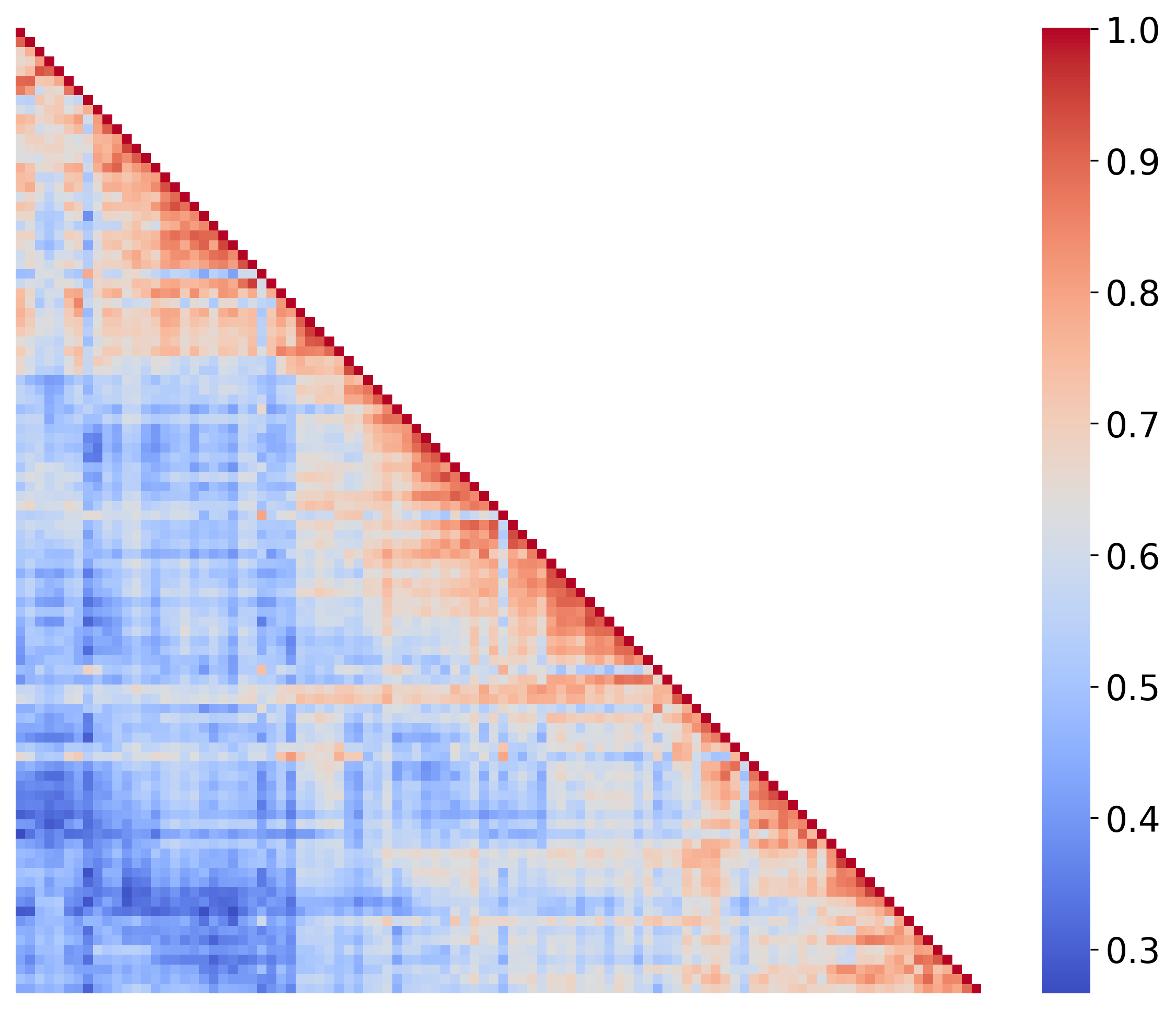
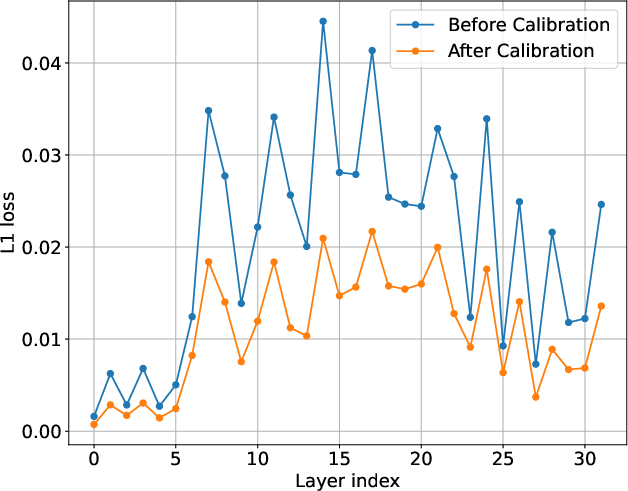
Figure 1: Overview of the CaliDrop method in decoding. The left figure illustrates the process of query similarity assessment and subsequent action, while the top-right and bottom-right figures detail similarity heatmaps and L1 losses before and after calibration, respectively.
The calibration approach leverages this similarity to predict future attention outputs from historical patterns. This method decomposes attention computation, distributing it between the current query and historical query for evicted tokens (Figure 1). Critical to this method is an empirical and theoretical framework demonstrating that attention outputs for historical queries can help approximate future attention outputs.
Numerical Results and Analysis
Extensive experimentation on benchmarks such as LongBench, RULER, and Needle-in-a-Haystack demonstrates significant accuracy improvements with CaliDrop when applied to existing token eviction techniques. For instance, in tasks requiring deep contextual understanding and multi-hop reasoning, CaliDrop consistently surpassed traditional methods across varied compression ratios. Particularly notable are the improvements evident in small KV cache sizes, where challenges to maintain accuracy are most pronounced.
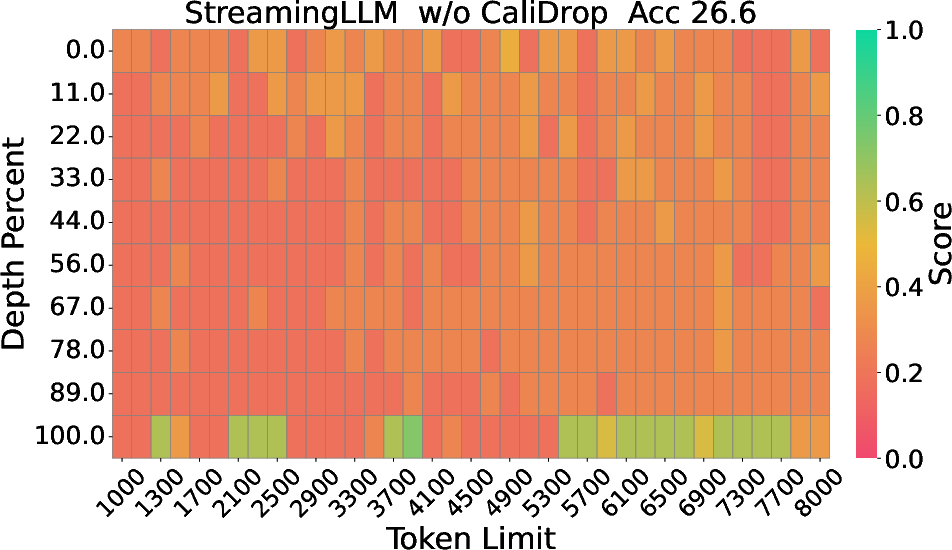
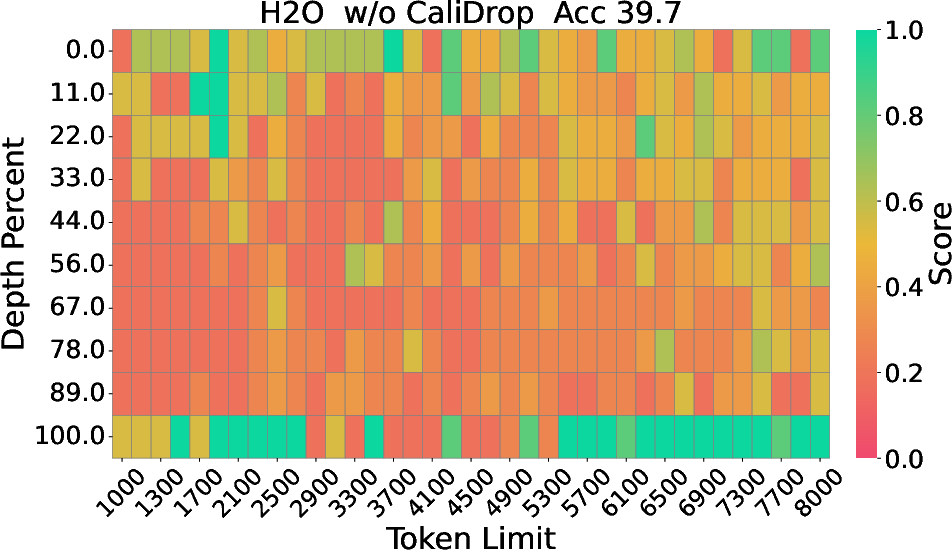
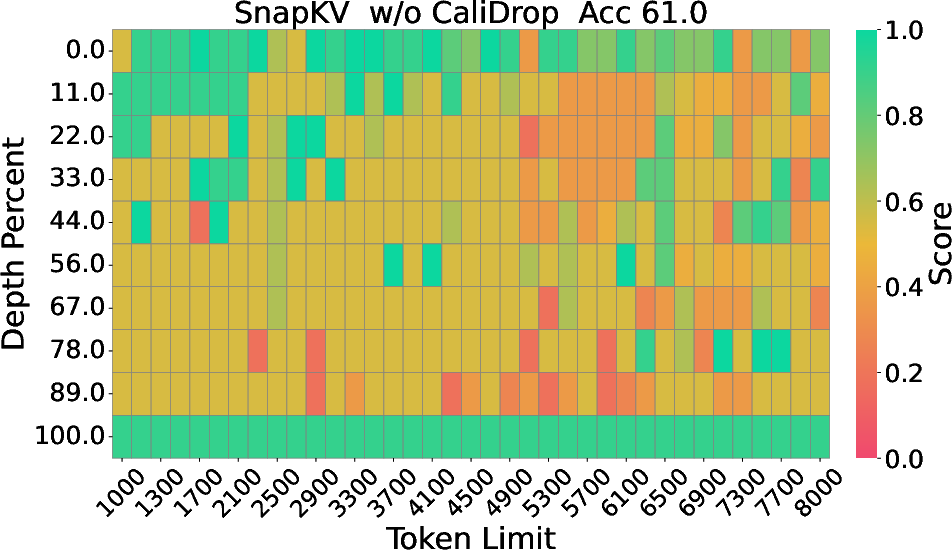
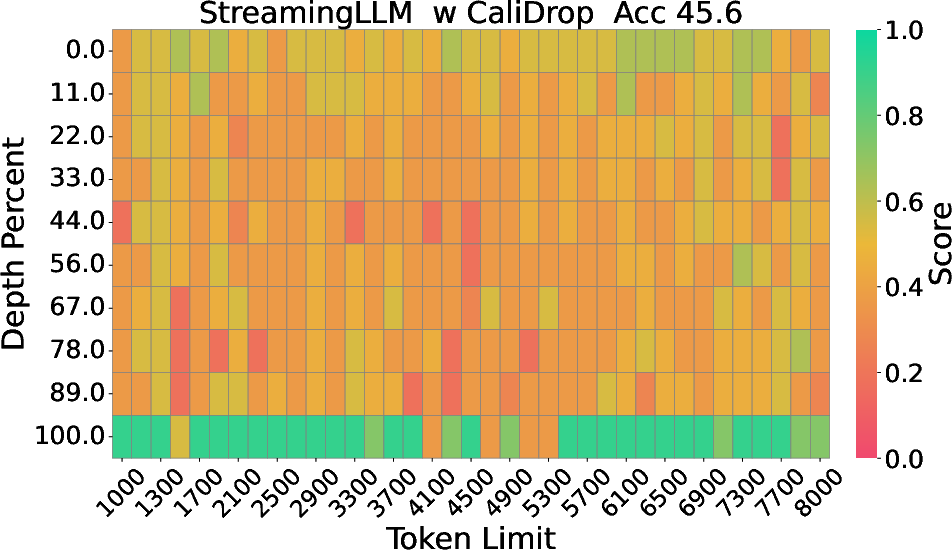
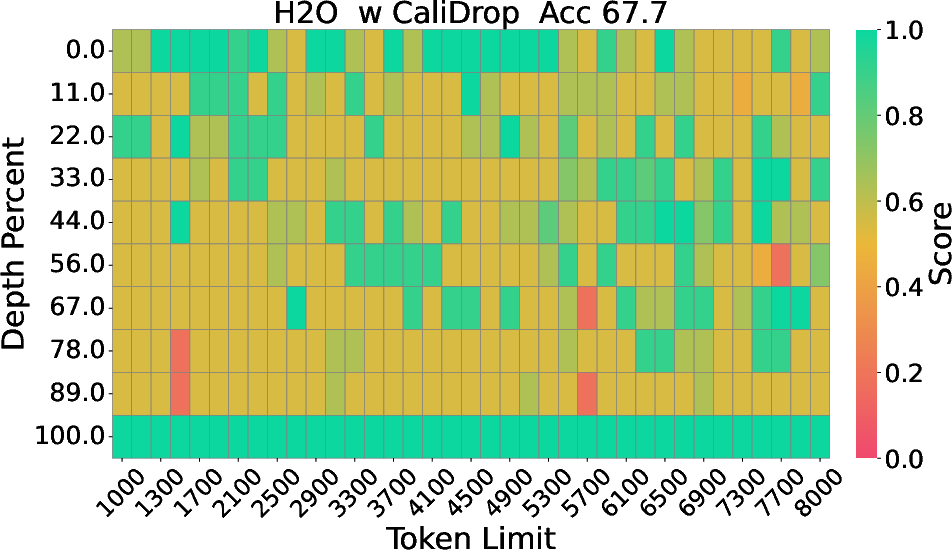
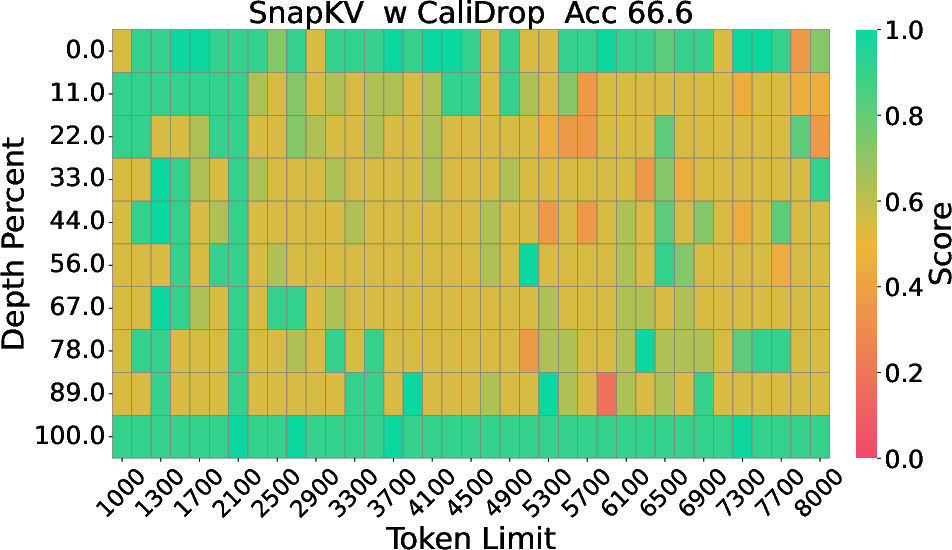
Figure 2: The Needle-in-a-Haystack results of LLaMA-3-8B-Instruct with 8k context size and 64 KV size, displaying depth percentage against token length.
Implications and Future Prospects
Practically, CaliDrop offers a substantial boost in efficiency for deploying LLMs in resource-constrained environments. Theoretical implications suggest further exploration into hybrid attention concepts, potentially paving the way for dynamically adaptive LLM architectures. Future research could focus on refining calibration thresholds to optimize for varying trade-offs between accuracy and computational overhead, along with expansive testing on diverse LLM architectures.
Conclusion
CaliDrop represents an innovative step in addressing the accuracy-memory trade-off inherent in KV caching strategies for LLMs. By employing calibration, its application extends the viability of token eviction methods and facilitates more efficient long-context processing. Ongoing research will undoubtedly refine these methods and expand their applicability, further enhancing LLM performance and deployment efficacy.