- The paper introduces a novel TDGF formulation that reformulates American option pricing as an energy minimization problem to tackle free-boundary PDEs.
- It employs a time-stepping scheme combined with a DGM-inspired neural network and box-based stratified sampling to effectively handle high-dimensional boundaries.
- The TDGF method demonstrates high accuracy with faster training and inference times compared to conventional DGM and Monte Carlo approaches.
Time Deep Gradient Flow Method for Pricing American Options: An Expert Analysis
The paper addresses the high-dimensional pricing of American put options under both the Black–Scholes and Heston models, focusing on the computational challenges posed by the early exercise feature and the curse of dimensionality. The American option pricing problem is formulated as a free-boundary PDE or, equivalently, a system of variational inequalities. The operator A, which encodes the dynamics of the underlying assets, is derived for both the multidimensional Black–Scholes and Heston models, with explicit expressions for the drift and diffusion coefficients. The reformulation of the PDE as an energy minimization problem is central to the Time Deep Gradient Flow (TDGF) method, enabling the use of neural networks for efficient approximation.
Time Deep Gradient Flow Method: Algorithmic Structure
The TDGF method extends the time-stepping deep gradient flow approach to the free-boundary PDEs characteristic of American options. The time interval [0,T] is discretized into K steps, and at each step, the solution is approximated by minimizing a discretized energy functional. The neural network parameterizes the continuation value, ensuring the no-arbitrage lower bound by construction. The cost functional at each time step is minimized using stochastic gradient descent, with the Adam optimizer and a carefully designed learning rate schedule.
A key innovation is the restriction of training to the region where the continuation value exceeds the intrinsic value, reflecting the free-boundary nature of the problem. The architecture is based on the DGM network, with three hidden layers and 50 neurons per layer, using tanh and softplus activations to guarantee positivity and smoothness.
Sampling Strategies for High-Dimensional Domains
Uniform sampling in high dimensions leads to poor coverage of the domain, especially at the boundaries, which is detrimental for learning the option price near the exercise boundary. The paper introduces a box-based stratified sampling scheme, partitioning the domain into multiple boxes and sampling uniformly within each. This ensures adequate representation across the range of moneyness, as illustrated in the following figures.
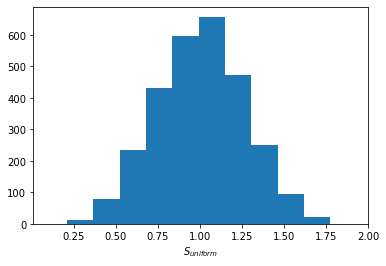
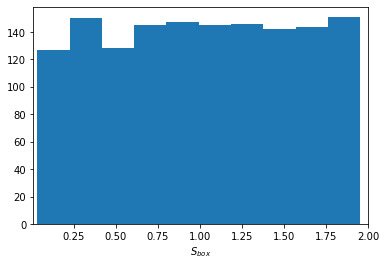
Figure 1: Uniform sampling in five dimensions results in poor coverage at the domain boundaries, leading to suboptimal learning near the exercise boundary.
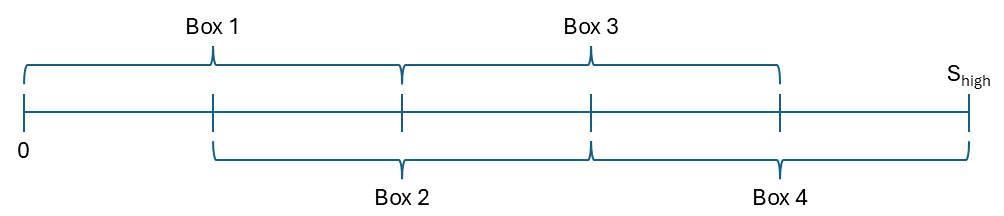
Figure 2: The domain is partitioned into four boxes for stratified sampling, improving coverage across moneyness levels.
This box sampling approach is used for initial training, while uniform sampling is employed during time-stepping, focusing on regions where the continuation value is positive.
Numerical Results: Accuracy and Efficiency
The TDGF method is benchmarked against the Deep Galerkin Method (DGM) and the Monte Carlo Longstaff–Schwartz approach. The evaluation metric is the difference between the option price and the payoff as a function of moneyness, across multiple time-to-maturity points and dimensions.
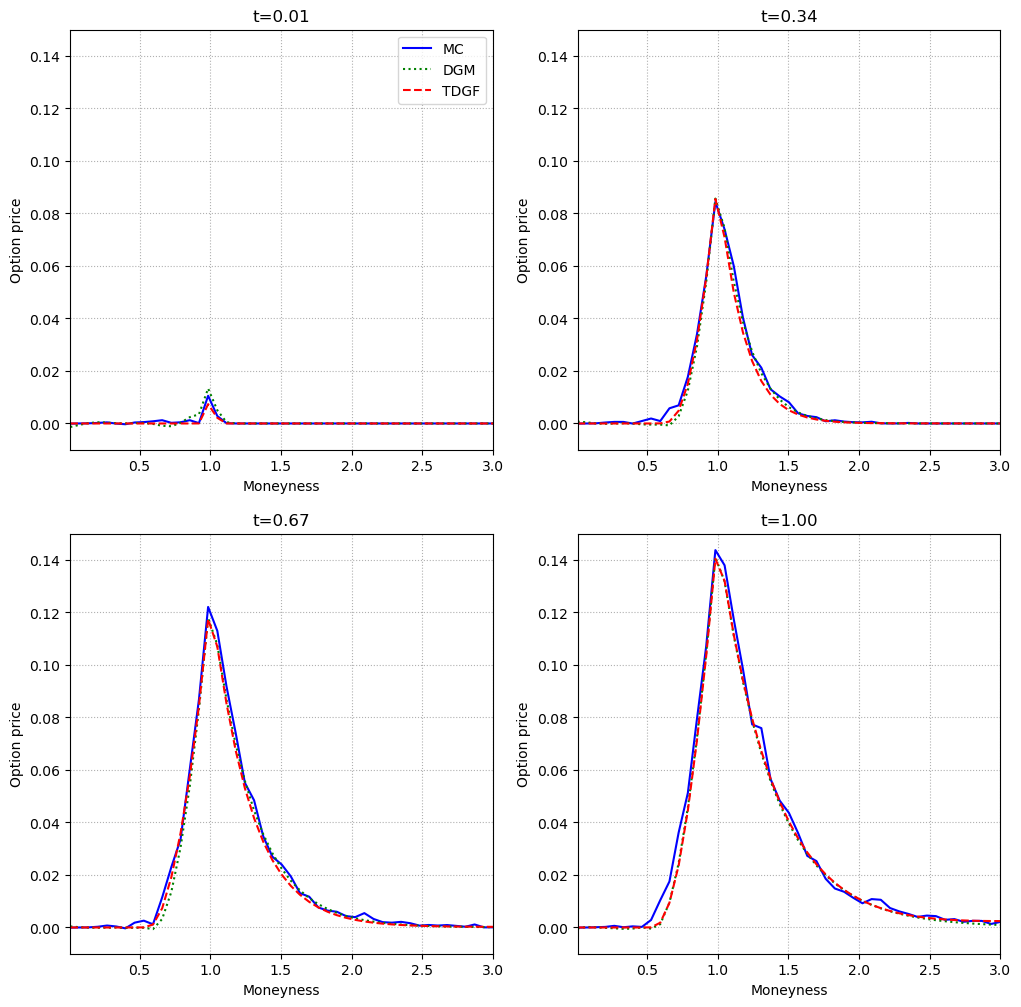
Figure 3: In the two-dimensional Black–Scholes model, TDGF and DGM closely match the Monte Carlo reference across moneyness and time.
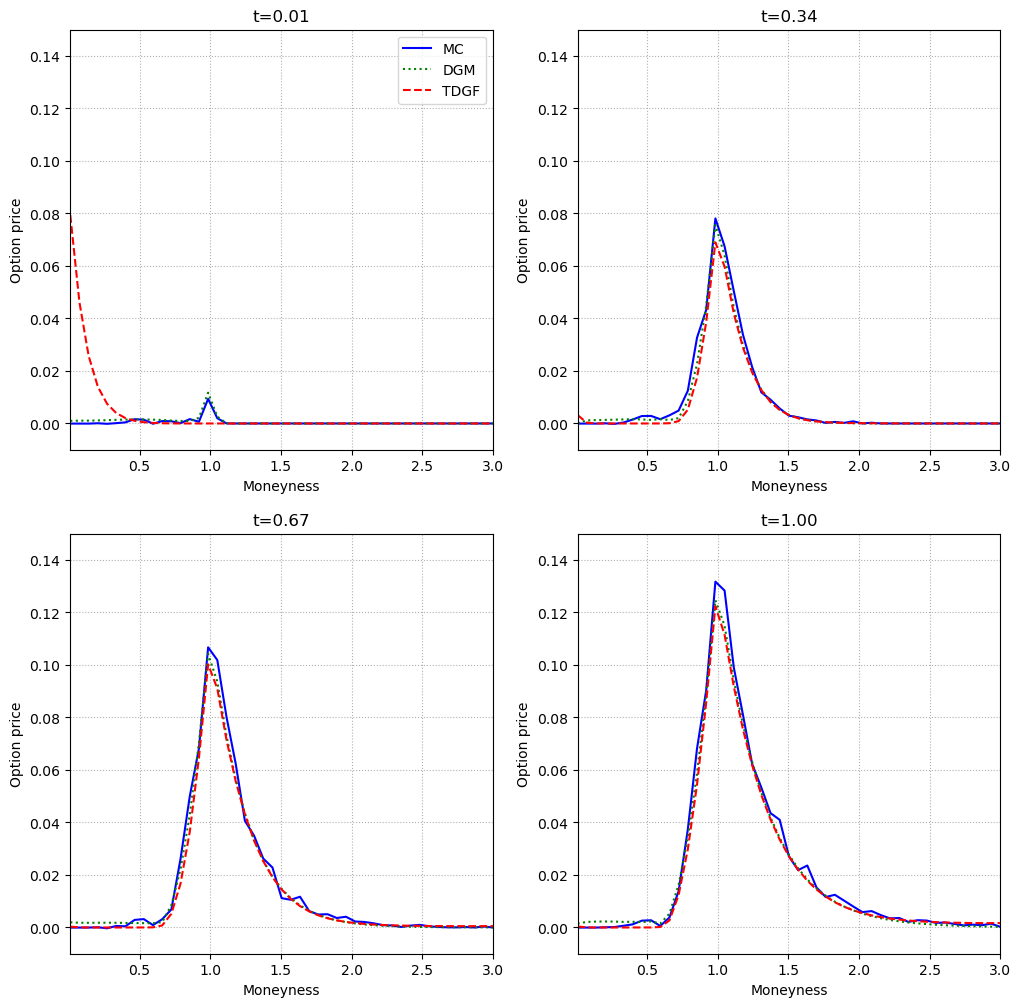
Figure 4: In the five-dimensional Black–Scholes model, both neural methods maintain high accuracy, with negligible deviation from Monte Carlo.
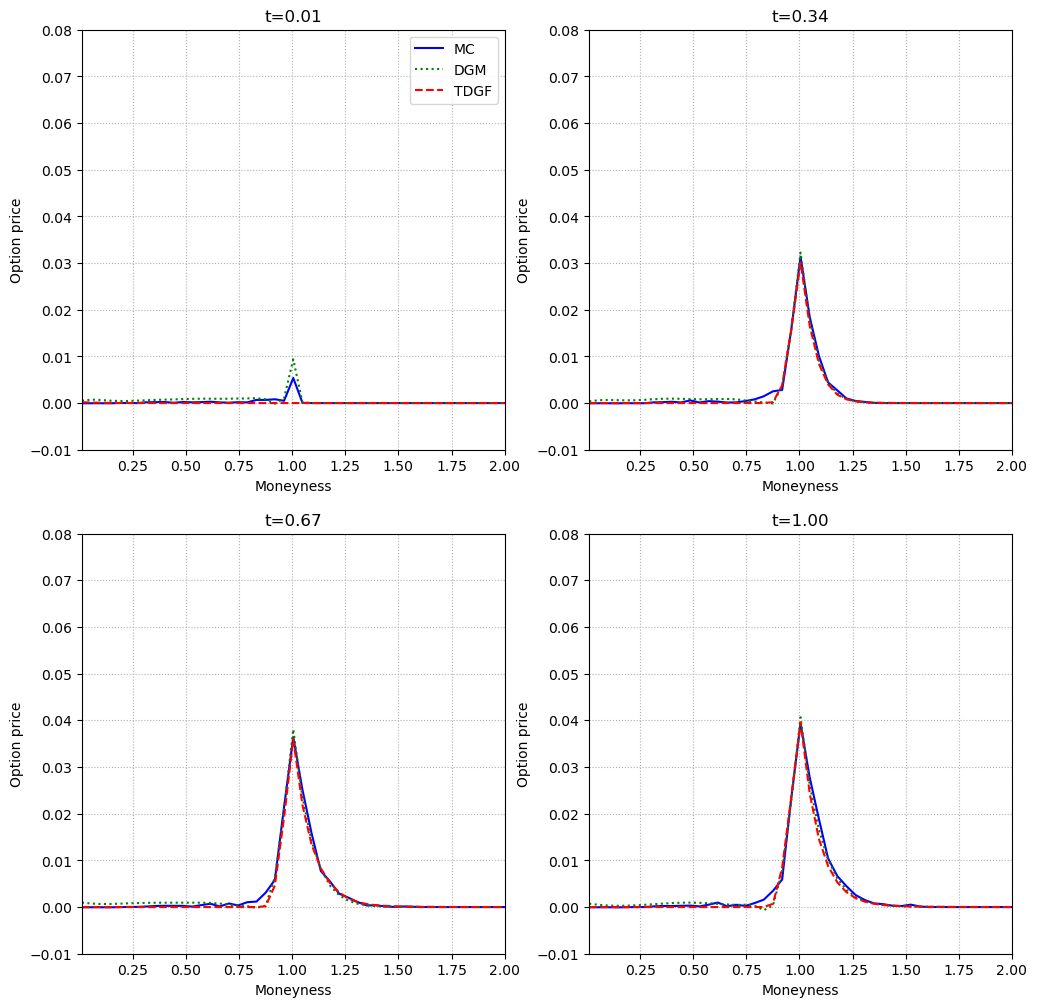
Figure 5: In the two-dimensional Heston model, TDGF and DGM again align with Monte Carlo, demonstrating robustness to stochastic volatility.
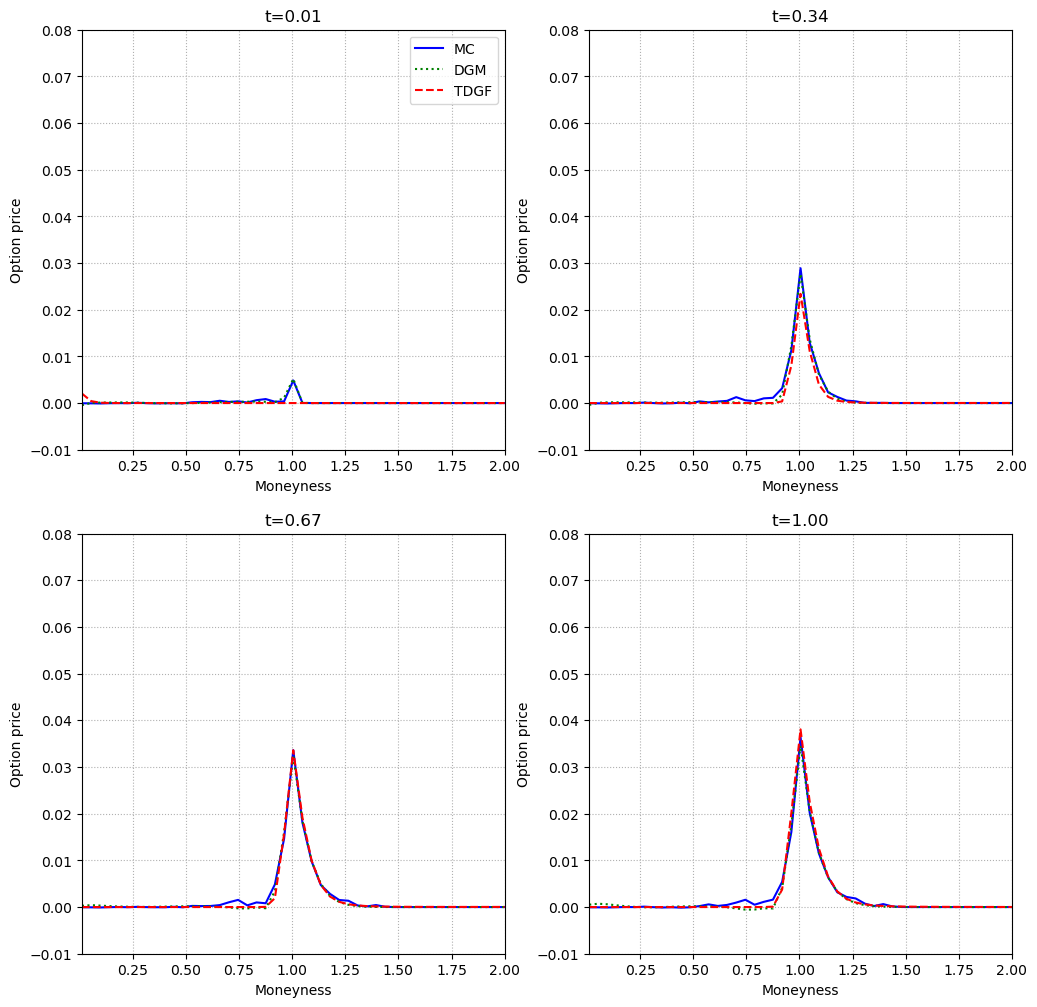
Figure 6: In the five-dimensional Heston model, TDGF and DGM preserve accuracy, even as the continuation value vanishes for high moneyness.
Across all tested scenarios, both TDGF and DGM achieve high accuracy, with the TDGF method exhibiting faster training times due to the absence of second derivatives in the loss and the efficiency of the time-stepping scheme. Computational times for inference are orders of magnitude lower than Monte Carlo, with both neural methods requiring less than 2 ms per evaluation, compared to several seconds for Monte Carlo.
Implementation Considerations
- Neural Network Architecture: The DGM-inspired architecture is well-suited for PDEs with free boundaries. The use of softplus activation in the output layer enforces the lower bound constraint.
- Sampling: Stratified box sampling is essential for high-dimensional problems to ensure adequate learning near the exercise boundary.
- Optimization: Adam optimizer with a fixed learning rate and no weight decay is effective. Training is performed on a single high-end GPU, but the method is amenable to further parallelization.
- Scalability: The method scales efficiently to five dimensions, with no significant degradation in accuracy or computational efficiency.
- Limitations: The approach relies on the ability to parameterize the continuation value and may require adaptation for more exotic payoffs or path-dependent options.
Implications and Future Directions
The extension of TDGF to free-boundary problems demonstrates that neural network-based PDE solvers can efficiently handle high-dimensional American option pricing, outperforming traditional Monte Carlo methods in both speed and, in some cases, accuracy. The explicit incorporation of the free-boundary constraint into the architecture and training regime is a significant methodological advance.
Potential future developments include:
- Extension to path-dependent and exotic options.
- Integration with variance reduction techniques for further efficiency gains.
- Exploration of alternative architectures (e.g., transformers or diffusion models) for even higher-dimensional problems.
- Theoretical analysis of convergence and generalization properties in the context of free-boundary PDEs.
Conclusion
The paper provides a rigorous and practical framework for high-dimensional American option pricing using the Time Deep Gradient Flow method. By combining a principled reformulation of the PDE, a tailored neural network architecture, and advanced sampling strategies, the approach achieves high accuracy and computational efficiency. The results indicate that TDGF is a viable and scalable alternative to both DGM and Monte Carlo methods for multidimensional American options under both Black–Scholes and Heston dynamics. The methodological innovations and empirical findings have significant implications for computational finance and the broader application of deep learning to high-dimensional PDEs.