- The paper introduces FormulaOne, a benchmark that measures deep algorithmic reasoning on real-world graph problems using MSO logic.
- The methodology employs dynamic programming on tree decompositions and precise state design to handle connectivity and combinatorial challenges.
- Results show top models solving less than 1% of tasks, underscoring the need for improved architectures in algorithmic reasoning.
Introduction
The paper introduces FormulaOne, a benchmark designed to assess the depth of algorithmic reasoning, particularly in real-world research problems. This benchmark diverges from conventional competitive programming tasks by focusing on complex, real-world challenges that require extensive reasoning capabilities, encompassing graph theory, combinatorics, and algorithm design. FormulaOne is rooted in Monadic Second-Order (MSO) logic on graphs, facilitating the creation of sophisticated problems with implications for real-world optimization and theoretical computer science.
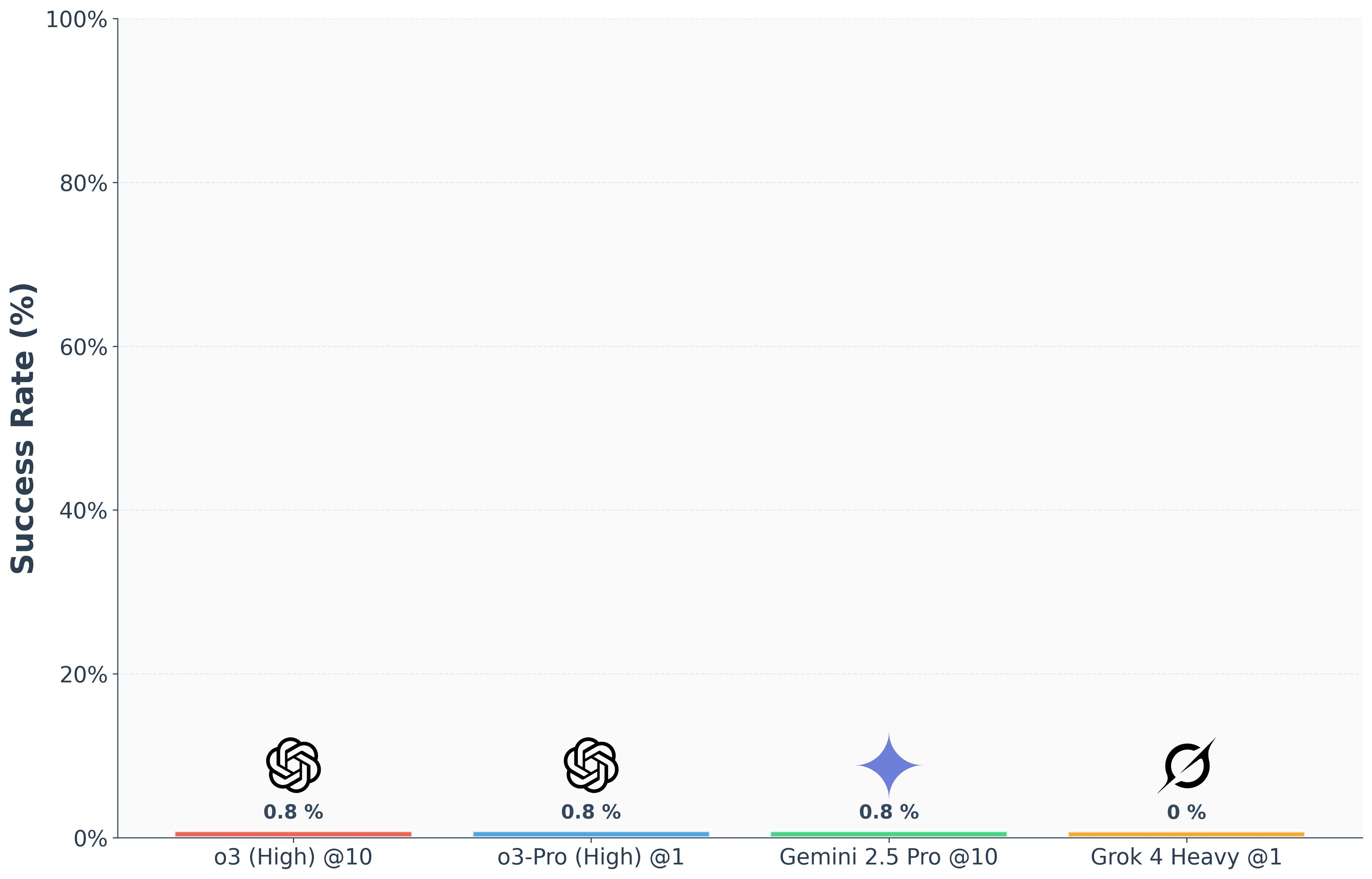
Figure 1: Performance of frontier reasoning models on the FormulaOne dataset.
Dataset and Problem Characteristics
FormulaOne comprises a collection of algorithmically intricate problems generated via MSO logic, a powerful framework known for its expressiveness in graph properties. These problems reflect real-life challenges, such as network design and scheduling, and are tied to significant theoretical constructs like the Strong Exponential Time Hypothesis (SETH). The dataset includes two key offerings: FormulaOne, with its challenging problems, and FormulaOne-Warmup, a subset designed to ease entry into this demanding research area.
Problems in FormulaOne challenge AI models beyond current capabilities, highlighting deficiencies in algorithmic comprehension. Notably, top models like OpenAI’s o3 manage to solve less than 1% of the problems, underscoring the difficulty of translating competitive programming prowess into solving fundamentally complex problems. The problems demand multi-step reasoning involving dynamic programming on tree-like graph structures.
Implementation Considerations
The implementation of solutions on FormulaOne problems requires constructing dynamic programming algorithms that leverage tree decompositions. This involves maintaining efficient state representations for each problem, where the complexity often arises from the need to summarize global graph properties within local computation contexts. The challenges encompass ensuring states adhere to constraints such as connectivity and edge-induced properties, which require sophisticated data structures and algorithmic strategies.
Dynamic Programming on Tree Decompositions
Tree decompositions allow handling of the complex structure of graphs by breaking them down into tree-like components, facilitating localized reasoning. Implementation involves:
- State Design: Defining minimal yet sufficient profiles to capture the essential properties of the problem within the confines of each bag in the decomposition.
- Transition Logic: Handling introduce, forget, and join operations effectively, ensuring logical consistency across subgraph joins and transitions between states.
The implementation thus demands both algorithmic precision and flexibility to adjust state representations dynamically as the tree decomposition is processed.
The evaluation on FormulaOne and FormulaOne-Warmup provides a stark view of current AI capabilities in deep algorithmic reasoning. Success rates are low, with severe limitations in models' ability to perform multi-step reasoning when faced with complex logical requirements and combinatorial challenges inherent to these problems. This signals a necessity for advancing model architectures and training methodologies that can capture these intricate reasoning chains.
Figure 2: Performance of top frontier models on the FormulaOne dataset.
Conclusion
FormulaOne serves as a significant benchmark for algorithmic reasoning in AI, challenging existing models to push beyond standard programming tasks to tackle complex, real-world problems. The dataset's foundation in MSO logic not only promotes rigorous testing of AI capabilities but also aligns with practical computational challenges and theoretical implications in computer science. Future advancements in AI will need to address these challenges by enhancing models' reasoning depth and adaptability, potentially reshaping approaches to both AI development and theoretical problem-solving.

