Solving the compute crisis with physics-based ASICs
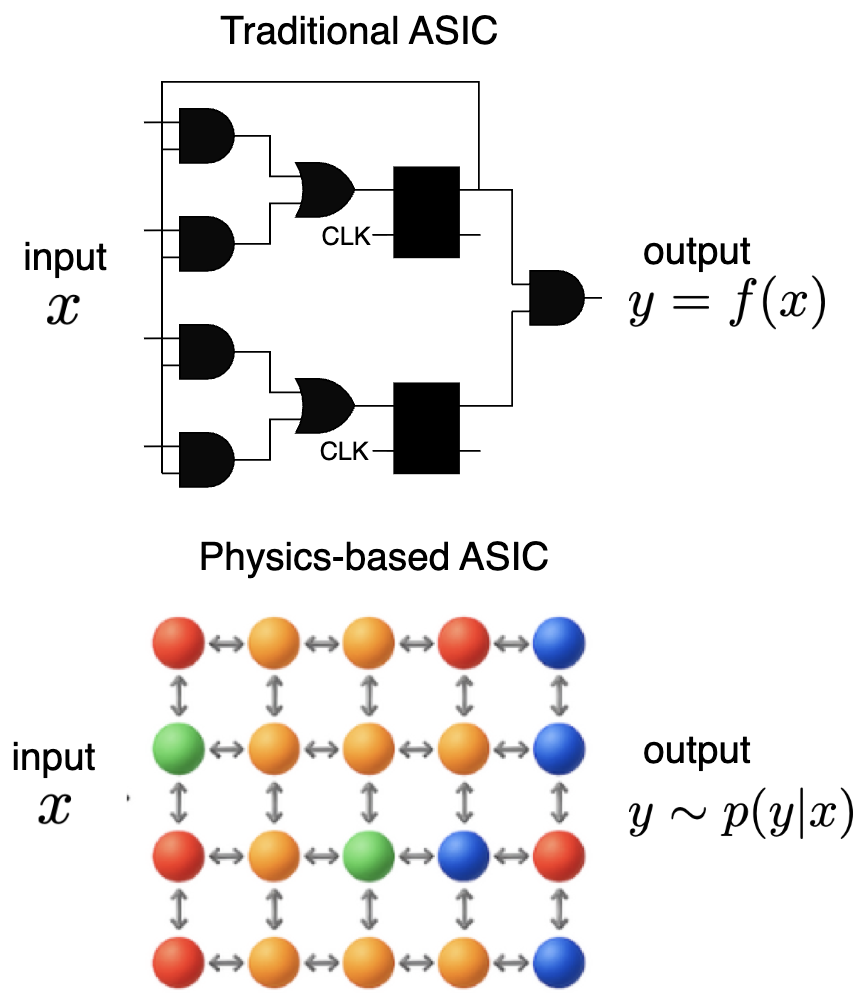
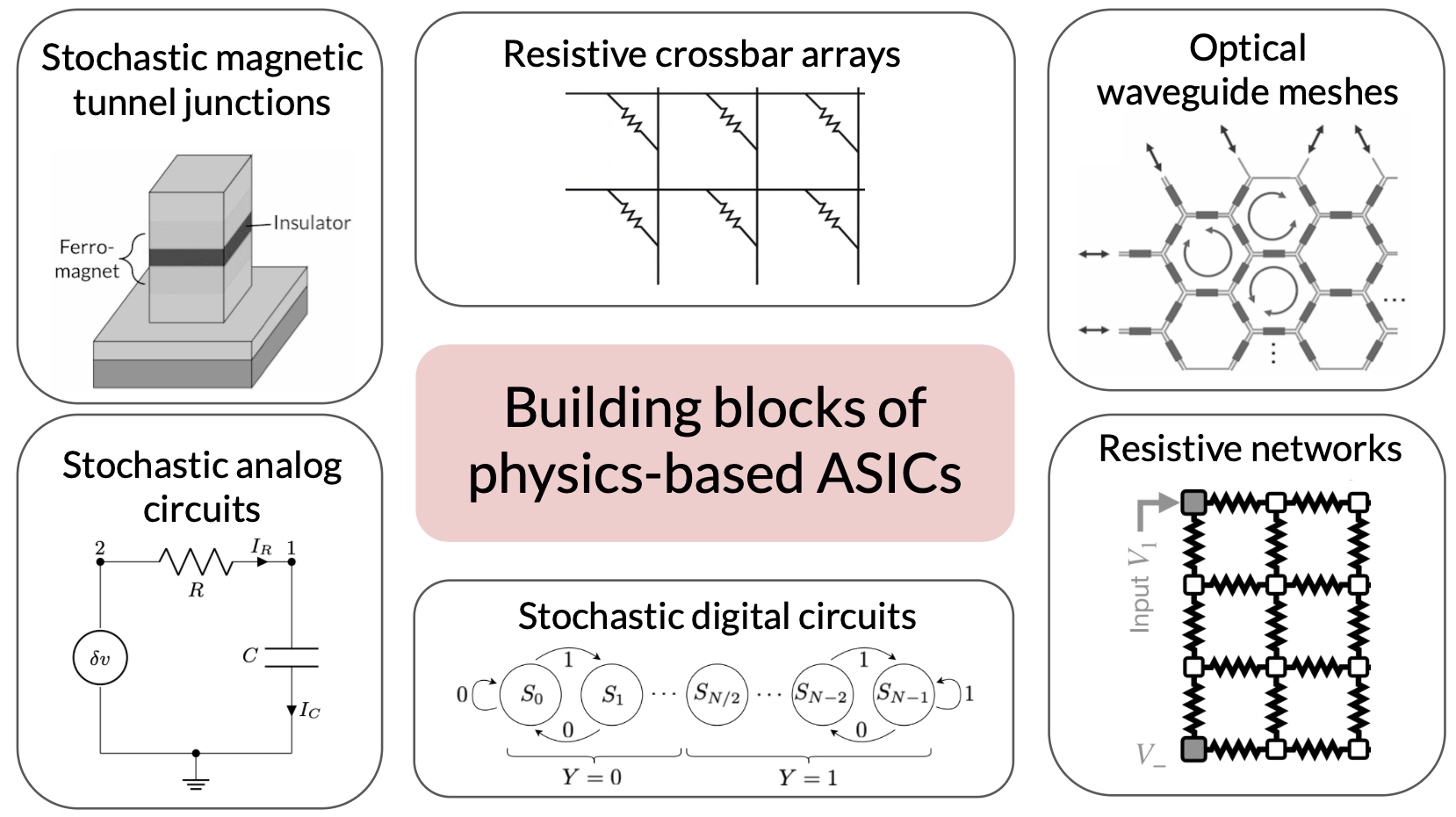
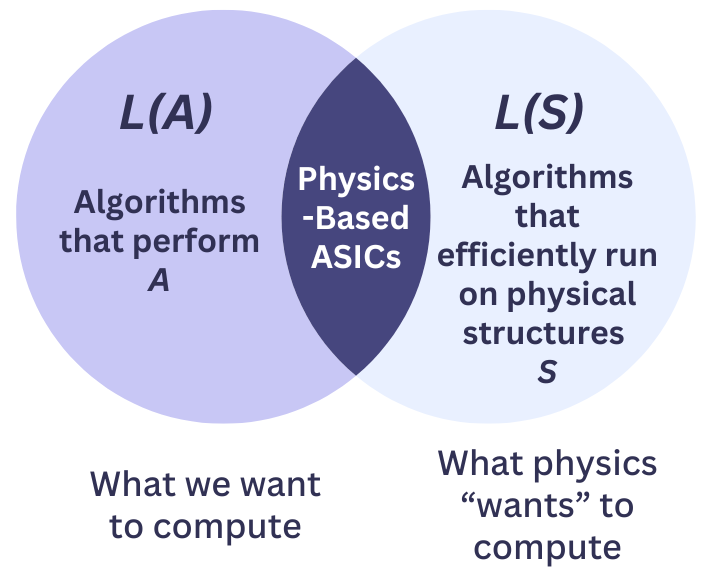
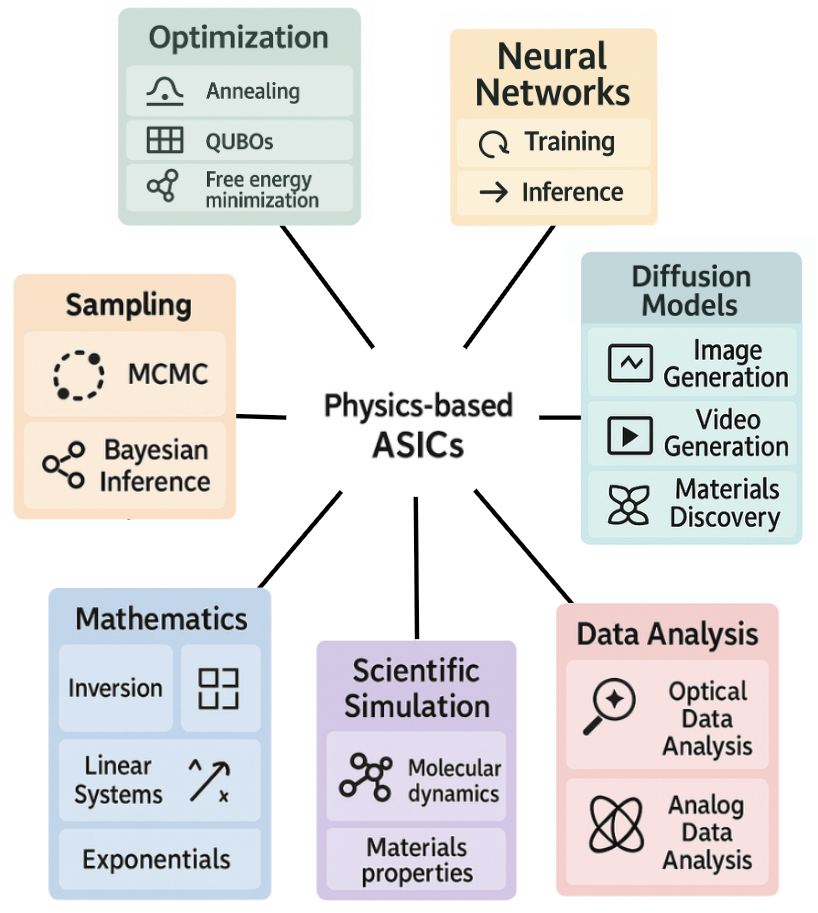
Abstract: Escalating AI demands expose a critical "compute crisis" characterized by unsustainable energy consumption, prohibitive training costs, and the approaching limits of conventional CMOS scaling. Physics-based Application-Specific Integrated Circuits (ASICs) present a transformative paradigm by directly harnessing intrinsic physical dynamics for computation rather than expending resources to enforce idealized digital abstractions. By relaxing the constraints needed for traditional ASICs, like enforced statelessness, unidirectionality, determinism, and synchronization, these devices aim to operate as exact realizations of physical processes, offering substantial gains in energy efficiency and computational throughput. This approach enables novel co-design strategies, aligning algorithmic requirements with the inherent computational primitives of physical systems. Physics-based ASICs could accelerate critical AI applications like diffusion models, sampling, optimization, and neural network inference as well as traditional computational workloads like scientific simulation of materials and molecules. Ultimately, this vision points towards a future of heterogeneous, highly-specialized computing platforms capable of overcoming current scaling bottlenecks and unlocking new frontiers in computational power and efficiency.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The paper articulates a vision but leaves several concrete issues open. The following list identifies specific gaps that future research can address:
- Comparative evaluation framework: Define precise, reproducible methodologies for runtime and energy comparisons (end-to-end), including data encoding/decoding, A/D–D/A, initialization, calibration, partitioning/tiling, and control overheads. Specify standardized workloads, scaling ranges, and reporting (e.g., J/sample with CIs). Clarify and correct the formal definitions of the proposed ratios (e.g., , ) and how they aggregate across heterogeneous pipelines.
- Accuracy–energy tradeoffs and error budgets: Develop quantitative error models for analog, stochastic, asynchronous hardware (noise, drift, device mismatch) and methods to bound and propagate errors through linear algebra, sampling, optimization, and neural network inference/training. Identify application-level tolerance thresholds and mechanisms to meet them at minimal energy.
- Mapping high-level workloads to physical primitives: Specify which components of prominent workloads (e.g., diffusion models, LLMs) run on physics-based ASICs versus digital accelerators, with concrete examples (model sizes, layer types, denoising steps). Provide co-design recipes that increase the accelerated fraction in Amdahl’s law and quantify resulting speedups.
- Sampler correctness and efficiency: Establish mixing-time and sampling-quality guarantees for physical samplers (Ising and Langevin circuits) under non-idealities. Quantify spectral gaps, metastability, temperature-control accuracy, and biases from imperfect couplings. Develop certification/diagnostics for large-scale sampling.
- Combinatorial optimization via Ising/oscillators: Characterize embedding overheads for dense graphs (chain formation, parameter ranges), success probability vs. problem structure, and energy/time scaling. Benchmark rigorously against state-of-the-art digital solvers (e.g., Gurobi, CPLEX, specialized heuristics) on standardized instances.
- Thermodynamic linear algebra claims: Provide rigorous convergence and complexity analyses that include analog settling dynamics, conditioning, finite precision, and noise. Determine classes of matrices with provable advantages, required preconditioning strategies, and worst-case behavior.
- Memory and interconnect bottlenecks: Quantify when I/O dominates total runtime/energy and propose architectures to mitigate it (e.g., in-memory compute, analog SRAM/NVM, 3D integration, HBM coupling). Provide concrete bandwidth/latency/energy budgets for analog–digital boundaries.
- Reconfigurable interactions at scale: Design and evaluate circuits enabling dense, programmable couplings with manageable area, parasitics, and calibration needs. Determine crossbar size/fidelity limits, routing/NoC strategies, and the trade-offs between analog density and digital programmability.
- Calibration and variability management: Create scalable auto-calibration and drift-compensation methods for millions of analog parameters, including temperature/aging tracking and recalibration policies. Quantify their time/energy overhead and impact on uptime.
- Programmability and toolchains: Develop intermediate representations, compilers, and autotuners that map algorithms to stochastic/asynchronous hardware primitives. Build fast, faithful simulators (bridging the sim2real gap) and verification flows that can handle nondeterminism.
- Learning algorithms for physical machine learning (PML): Devise scalable gradient-estimation techniques (adjoint, perturbation, implicit differentiation) robust to noise and latency; mitigate barren plateaus; deliver convergence and generalization guarantees; and quantify sample efficiency versus digital baselines.
- In-situ physical learning: Identify local update rules with proven convergence/stability on realistic hardware graphs; specify required observables and control signals; assess precision/dynamic range demands; and select memory mechanisms (NVM endurance, retention) for storing learned parameters.
- CMOS co-integration and manufacturability: Determine process-compatible device stacks (memristors, MTJs, photonics) at advanced nodes, yield/yield-learning strategies, and design-for-test (DFT) methodologies for stochastic analog blocks. Evaluate area/power penalties of peripheral circuits (biasing, readout).
- System-level energy accounting: Incorporate the energy costs of DAC/ADC, clocks, control logic, calibration, packaging, and cooling into efficiency claims. Establish measurement protocols that isolate compute energy from support infrastructure.
- Reliability and fault tolerance: Develop error detection/correction, redundancy, and reconfiguration strategies suitable for analog/stochastic computation. Study resilience to soft errors, thermal fluctuations, aging, and their implications for reproducibility and acceptance in scientific/regulated settings.
- Asynchrony and polysynchrony: Create programming models, runtimes, and debugging methods for asynchronous systems; define deterministic execution modes when needed; evaluate performance/energy trade-offs of clocking strategies.
- Security and randomness: Assess side-channel risks in analog inference and training; certify the quality of on-chip randomness for sampling and cryptographic use; examine implications of nondeterminism for safety-critical and privacy-sensitive applications.
- End-to-end application benchmarks at scale: Deliver full-system demonstrations (e.g., ImageNet-scale inference, Stable-Diffusion-class generation, large QUBO instances, realistic MD with long-range interactions) with throughput, energy, and accuracy comparisons against contemporary GPUs/TPUs.
- Thermal management: Model and measure self-heating in dense analog arrays, temperature-dependent noise, and thermal gradients. Co-design cooling solutions and algorithms to maintain accuracy and stability.
- Economic viability: Build total-cost-of-ownership models (silicon area, NRE, yield, packaging, calibration time, deployment/maintenance) to identify break-even points versus GPU clusters for specific workloads.
- Benchmark standardization: Propose open, community-accepted benchmark suites and measurement harnesses for physics-based compute (sampling, optimization, diffusion, analog ML), including accuracy and energy metrics.
- Environmental and materials considerations: Evaluate supply-chain and lifecycle impacts (e.g., magnetic materials, photonics), recycling/end-of-life, and data-center deployment constraints.
- Fundamental limits: Analyze thermodynamic and information-theoretic bounds on efficiency gains from relaxing statelessness/unidirectionality, and identify regimes where further relaxation yields diminishing returns.
- Heterogeneous system integration: Define APIs and orchestration for CPU/GPU/physics-ASIC co-processing, including partitioning strategies, latency hiding, and back-pressure across analog–digital boundaries.
- Platform selection criteria: Provide a decision framework (with PPA and risk projections) for choosing among MTJ/p-bits, memristors, photonics, and analog CMOS for given algorithm classes and scaling targets.
- Reproducibility protocols: Establish statistical reporting standards for nondeterministic outputs (confidence intervals, seeds, trial counts) to enable fair comparisons and scientific rigor.
Collections
Sign up for free to add this paper to one or more collections.

