- The paper introduces the PyVision framework that dynamically generates Python code for visual reasoning tasks through a multi-turn process.
- The methodology leverages process isolation, cross-turn persistence, and a detailed taxonomy of tools to enhance flexibility and interpretability.
- Experimental results show performance gains of +7.8% for GPT-4.1 and +31.1% for Claude-4.0-Sonnet, highlighting the framework's impact.
The paper "PyVision: Agentic Vision with Dynamic Tooling" (2507.07998) introduces an interactive, multi-turn framework called PyVision that enables Multimodal LLMs (MLLMs) to autonomously generate, execute, and refine Python-based tools tailored to specific visual reasoning tasks. This approach moves beyond predefined workflows and static toolsets, allowing for more flexible and interpretable problem-solving. The core idea is to leverage the coding and reasoning capabilities of modern MLLMs, such as GPT-4.1 and Claude-4.0-Sonnet, to dynamically create code snippets that act as specialized tools for analyzing and manipulating visual information.
Core Framework and Implementation
PyVision operates as an agentic loop where the MLLM receives a multimodal query, generates Python code, executes it within an isolated runtime, and then uses the output (textual or visual) to refine its reasoning in subsequent turns (Figure 1). This process continues until the MLLM arrives at a final answer. The system prompt is carefully engineered to guide the MLLM in accessing input images, structuring code, and providing final answers. Input images are pre-loaded as variables (e.g., image_clue_i), and the MLLM is encouraged to use Python libraries like OpenCV, Pillow, NumPy, and Scikit-image to analyze and transform the images. The system prompt also specifies that code outputs should be printed using print() for textual results and plt.show() for image visualizations, with code blocks wrapped in <code> tags and final answers enclosed in <answer> tags.
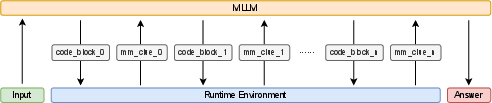
Figure 1: PyVision, an interactive and multi-turn framework capable of dynamic tool generation, designed for multimodal reasoning.
Key implementation details include process isolation (each code snippet runs in a separate subprocess), cross-turn persistence (variables and state are maintained across turns), and file-system safe I/O (communication between the runtime and the MLLM occurs through structured variable passing). These features contribute to the robustness, security, and flexibility of the PyVision framework.
The authors developed a taxonomy to categorize the tools generated by PyVision, identifying four major classes: basic image processing, advanced image processing, visual prompting and sketching, and numerical and statistical analysis. Basic image processing tools include cropping, rotation, and enhancement operations. Advanced image processing tools encompass segmentation, object detection, and OCR. Visual prompting and sketching involve rendering marks and lines on images to aid reasoning. Numerical and statistical analysis includes image histograms and quantitative analysis of visual inputs. The authors also note the existence of a long tail of novel, task-specific operations that don't fall neatly into these categories, showcasing the creative potential of dynamic tooling. For example, (Figure 2) demonstrates how PyVision solves a "spot the difference" task by subtracting pixel values between two images and visualizing the result.

Figure 2: Case Study: Spot-the-Difference showcases structured visual comparison.
Experimental Results and Discussion
The paper presents quantitative results across several benchmarks, demonstrating that PyVision consistently improves the performance of strong backend models. For example, PyVision boosted GPT-4.1 by +7.8% on V* and Claude-4.0-Sonnet by +31.1% on VLMsAreBlind-mini. The authors found that PyVision amplifies the strengths of the backend model; it gains more on perception tasks when paired with perceptually strong models like GPT-4.1 and gains more on abstract reasoning when paired with Claude-4.0-Sonnet. This suggests that dynamic tooling does not override model capabilities but rather unlocks them. The distribution of tool categories varies across benchmarks and domains (Figure 3), indicating that PyVision adapts its strategy to the unique demands of each task. For instance, math-related benchmarks often trigger numerical and statistical analysis tools, while visual search tasks rely heavily on cropping.
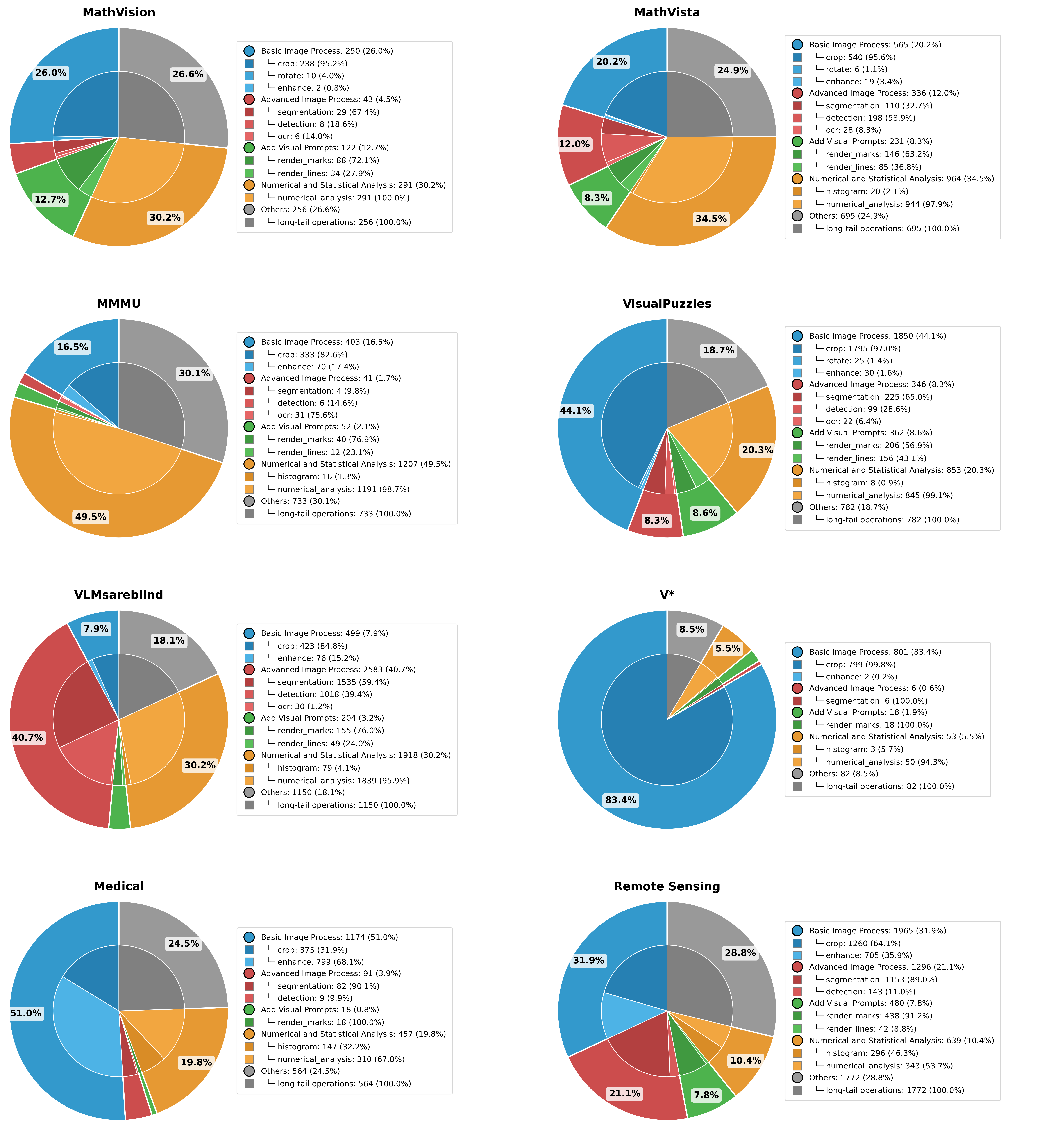
Figure 3: Taxonomy Distribution Across Benchmarks and Domains.
The paper also analyzes multi-turn interaction patterns (Figure 4), showing that Claude-4.0-Sonnet tends to generate more code and engage in longer toolchains than GPT-4.1, reflecting differences in how each MLLM approaches complex reasoning.
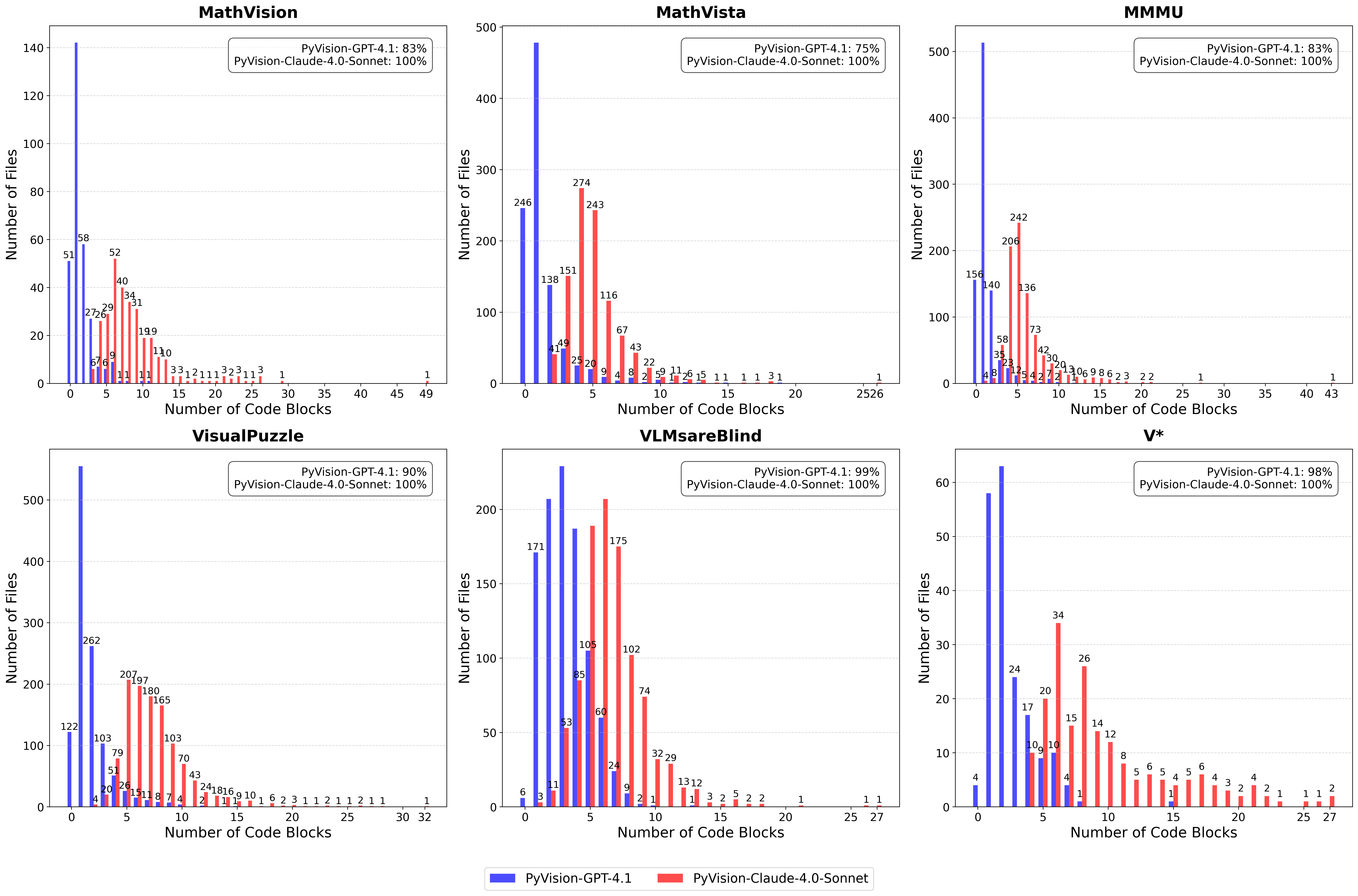
Figure 4: Multi-Turn Interaction Patterns Across Tasks and Backend Models.
Implications and Future Directions
The PyVision framework represents a significant advancement in agentic visual reasoning. By enabling MLLMs to dynamically generate and execute Python code, it overcomes the limitations of predefined workflows and static toolsets. This approach not only improves performance on a variety of visual tasks but also offers greater interpretability and flexibility. The ability to invent new computational tools on the fly moves AI systems closer to versatile, autonomous, and creative problem-solving. Future research could explore more sophisticated methods for tool generation, integration with external knowledge sources, and applications in real-world scenarios such as robotics and autonomous navigation.
Conclusion
The PyVision framework demonstrates the potential of dynamic tooling for visual reasoning. By empowering MLLMs to generate and execute Python code on the fly, PyVision achieves significant performance improvements and unlocks new capabilities for complex visual tasks. The framework's modular design, combined with the versatility of Python, makes it a promising platform for future research in agentic AI and multimodal reasoning.

