- The paper introduces hPGA-DP, demonstrating that embedding geometric inductive biases via PGA accelerates training and enhances robot manipulation performance.
- The architecture hybridizes P-GATr with denoising networks, achieving nearly 100% success on stack tasks in only 30 epochs.
- Extensive simulations and real-world experiments validate hPGA-DP’s superior convergence, reduced training time, and robustness to loss masking variations.
Hybrid Diffusion Policies with Projective Geometric Algebra for Efficient Robot Manipulation Learning
Introduction
The paper "Hybrid Diffusion Policies with Projective Geometric Algebra for Efficient Robot Manipulation Learning" introduces hPGA-DP, a hybrid diffusion policy architecture designed to enhance robot manipulation learning tasks. The core innovation is the integration of Projective Geometric Algebra (PGA) into the architecture, specifically employing the Projective Geometric Algebra Transformer (P-GATr) as a state encoder and action decoder. This method leverages geometric inductive biases to improve the spatial reasoning capabilities of neural networks, enabling more efficient training and superior task performance in robotic environments.
Technical Contributions
Geometric Inductive Biases
The hPGA-DP architecture embeds geometric inductive biases by using PGA, which provides a compact and unified framework for representing geometric primitives and transformations. Traditional neural networks often need to relearn basic spatial concepts in each new task, a computationally expensive process. By representing these concepts inherently through PGA, hPGA-DP reduces redundancy in learning, leading to faster convergence and improved efficiency.
Hybrid Architecture Design
The architecture combines P-GATr with established neural network modules like U-Net or Transformers for denoising tasks. P-GATr is used as a spatial state encoder and an action decoder, ensuring that the network can effectively reason about geometric structures while still taking advantage of the robust denoising capabilities of traditional architectures. This hybrid strategy avoids the slow convergence issues faced by models that rely entirely on geometrically biased architectures, like those using P-GATr for all components.





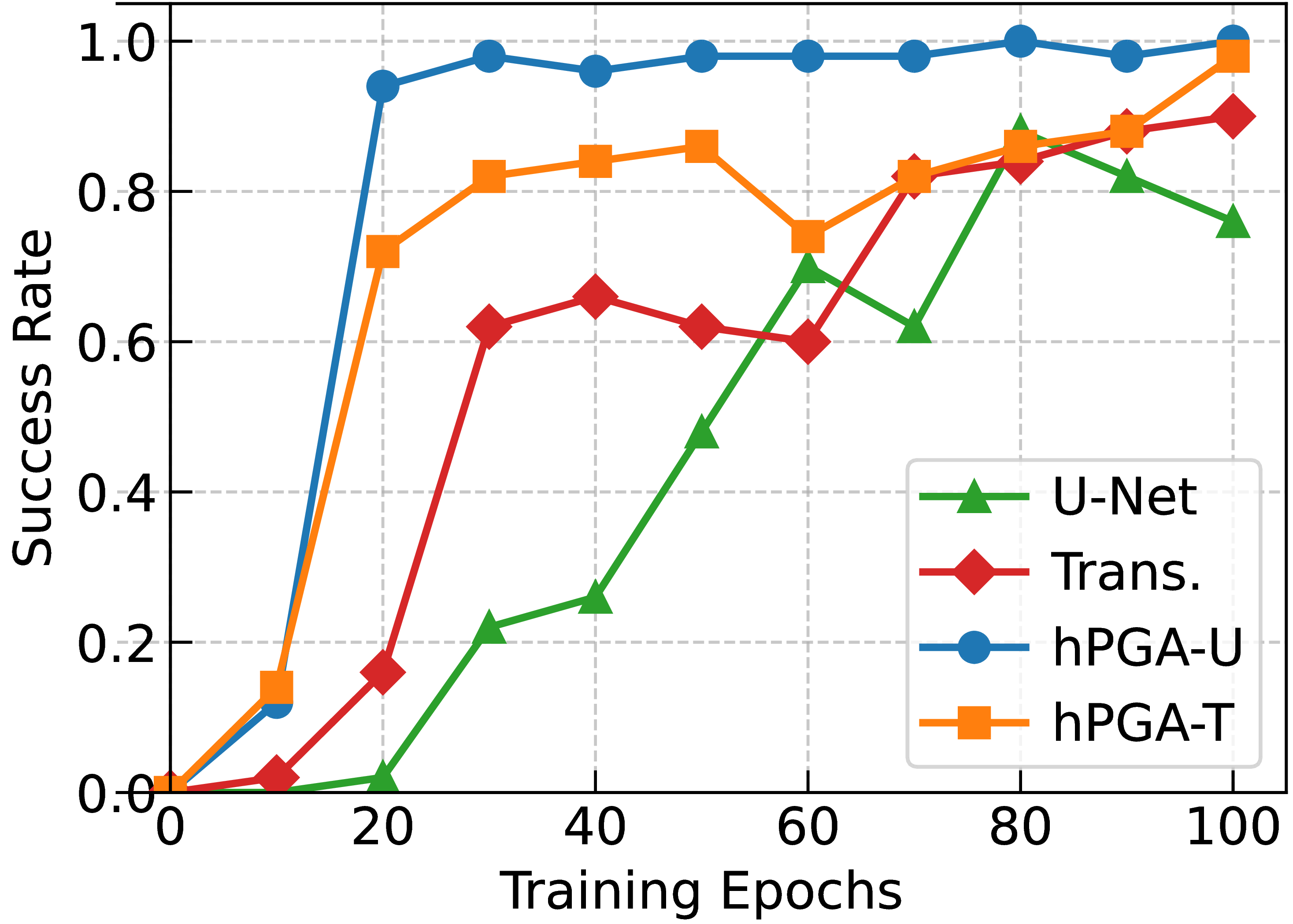
Figure 1: Top: simulation tasks in robosuite, with colored 3D bounding boxes indicating task-relevant objects. Bottom left: success rates for diffusion policies with different network backbones for various tasks, and mean epoch training time (MET) for each network on all tasks together. Bottom right: plot of success rate for state-based policies with U-Net, Transformer, hPGA-U, and hPGA-T for 100 training epochs of the Stack task.
Experimentation
Simulation Results
Extensive simulations were conducted on tasks within Robosuite, analyzing the performance of hPGA-DP compared to baselines using U-Net, Transformer, and standalone P-GATr architectures. The study found that hPGA-DP variants converged significantly faster and required fewer epochs to achieve superior task success rates. For instance, in the Stack task, hPGA-DP achieved nearly 100% success rates in only 30 epochs, whereas U-Net and Transformer baselines required substantially longer training periods to reach similar efficacy. This result highlights the improved training efficiency conferred by embedding spatial inductive biases within the architecture.
Ablation Studies
Ablation studies further validate the effectiveness of the hPGA-DP design choices. The experiments demonstrated robustness to variations in the loss masking threshold η, which controls the application of the action decoder loss. It also showed that the geometric inductive bias, rather than the encoder-decoder structure, was the key factor contributing to performance gains.
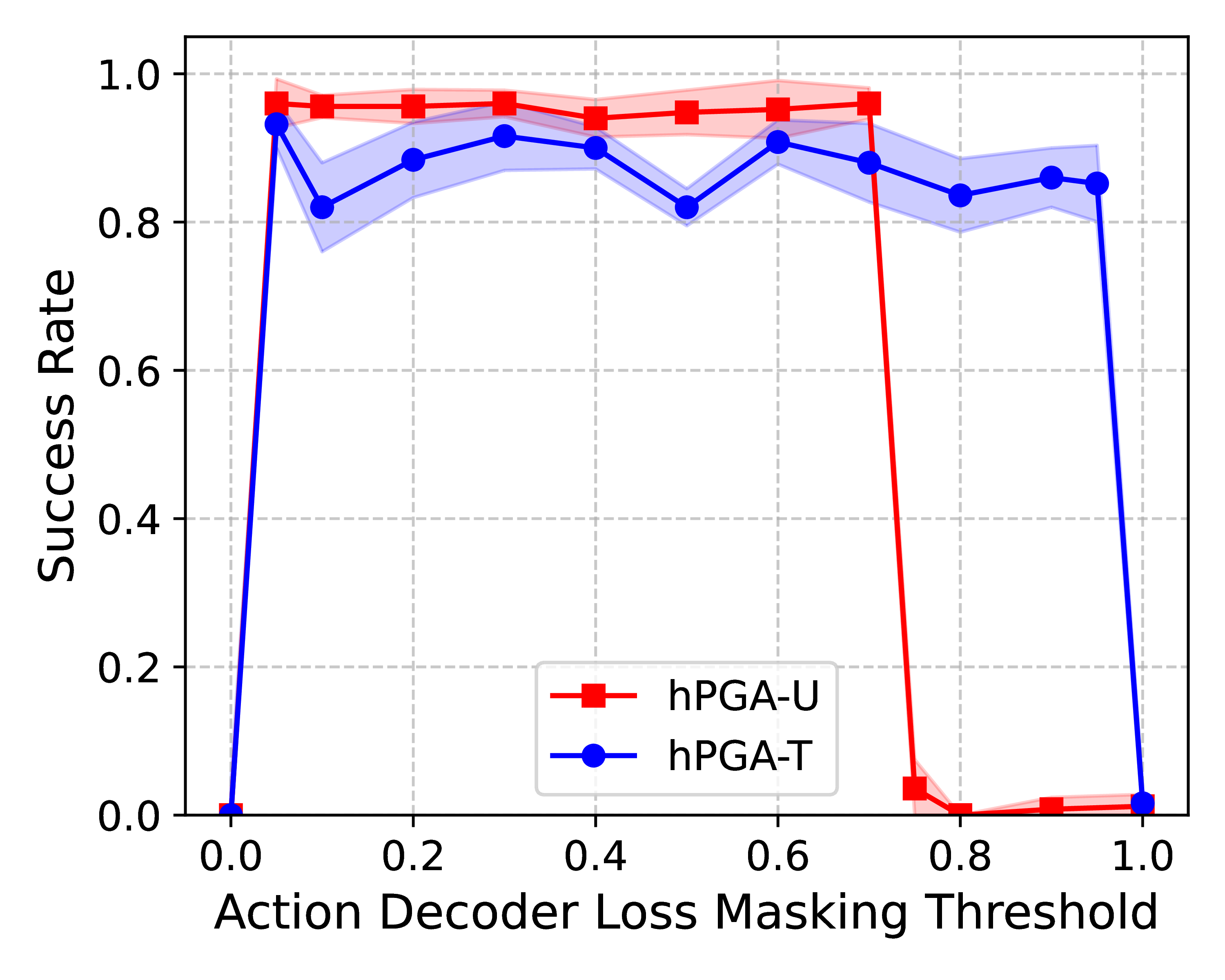
Figure 2: Top: Success rate of hPGA-DP under different decoder loss masking thresholds η, where solid line denotes the mean and shaded region indicates the standard deviation. Bottom: Performance of diffusion policies with various combinations of \underline{backbone} and encoder, and decoder (italicized).
Real-World Evaluation
Real-world experiments using a dual-arm system further corroborate the simulation findings. Tasks such as block stacking and drawer interaction showcased the applicability of hPGA-DP, providing high success rates with reduced training times compared to traditional architectures. This confirms the practicality of deploying hPGA-DP in real robotic systems and its capacity to generalize across different robot learning frameworks.

Figure 3: Results for real-world experiments with Block Stacking and Drawer Interaction tasks showing the effectiveness of hPGA architectures.
Conclusion
The hPGA-DP architecture significantly advances robot manipulation learning by embedding geometric inductive biases through Projective Geometric Algebra, thereby enhancing performance and training efficiency. This hybrid approach effectively integrates geometric reasoning into diffusion policies, outperforming standard diffusion-based architectures and offering potential for broader application in robotic learning tasks. Future work may focus on further optimizing computational efficiency, including the exploration of lower-level implementations to accelerate geometric algebra computations and the investigation of potential extensions beyond Euclidean space constraints.