- The paper introduces an intrinsic fingerprinting approach using attention parameter standard deviations to reliably detect model lineage.
- The methodology leverages statistical correlations of attention matrices across layers to identify potential unauthorized model derivations.
- Experimental validation across various LLMs highlights the method’s effectiveness in enhancing intellectual property protection in AI.
Intrinsic Fingerprint of LLMs: Continue Training is NOT All You Need to Steal A Model!
Introduction
The paper "Intrinsic Fingerprint of LLMs: Continue Training is NOT All You Need to Steal A Model" identifies the vulnerabilities of traditional watermarking techniques and introduces a novel fingerprinting method to address issues of intellectual property protection and model lineage identification within LLMs. As the cost of training such models escalates, the potential for plagiarism and unauthorized reuse of models grows, which underscores the importance of establishing robust mechanisms for verifying model origin.
Methodology
Problem Definition
The research formalizes lineage detection as a binary classification task where the goal is to ascertain if a model A is derived from model B through continued training or other modifications, rather than being independently developed from scratch. This determination is crucial for protecting intellectual property and ensuring proper attribution.
Intrinsic Fingerprinting
The methodology leverages unique statistical properties of attention mechanism parameters as intrinsic fingerprints. Specifically, the standard deviation of attention matrix parameters (query, key, value, and output matrices) across layers is utilized as a distinctive signature (Figure 1).
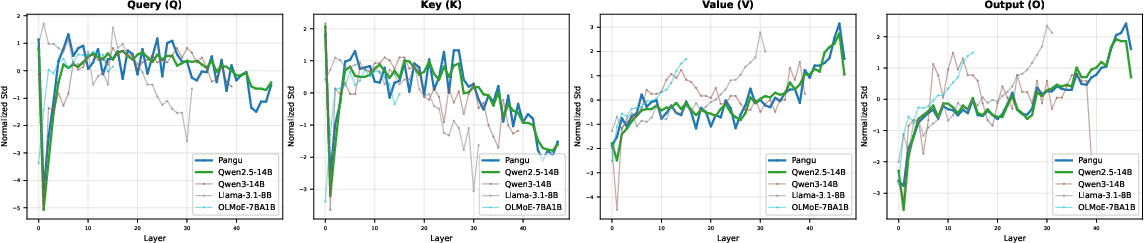
Figure 1: Normalized standard deviation patterns of attention matrices (Q, K, V, O) across different model families.
These distributions are computed and normalized for comparison across different models, ensuring robustness against parameter scaling and architectural changes. The correlations of these distributions between models are used to assess potential lineage relationships.
Correlation Analysis
To determine lineage, correlation coefficients between the normalized standard deviation sequences of different models are calculated. High correlation coefficients indicate potential derivation or model reuse. The study finds a remarkable correlation between Pangu Pro MoE and Qwen2.5-14B, suggesting potential unauthorized derivation (Figure 2).
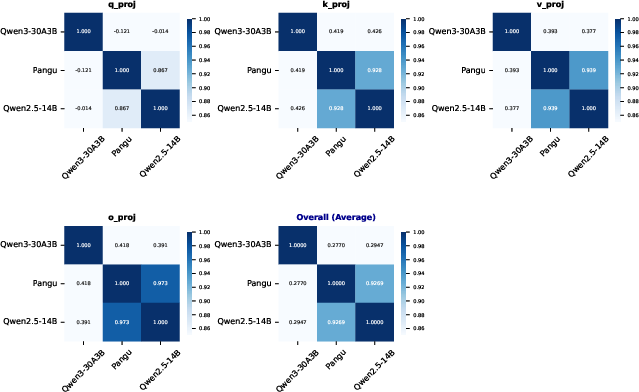
Figure 2: Correlation matrices for three key models (Qwen3-30A3B, Pangu, Qwen2.5-14B) across different attention matrix types.
Experiments
Cross-Family Model Analysis
Through extensive comparative analysis across multiple model families, the paper reveals significant insights into the intrinsic fingerprints of LLMs. Models such as Pangu and Qwen2.5-14B exhibit nearly identical distribution patterns, an extraordinary finding given their purportedly independent development paths (Figure 3).
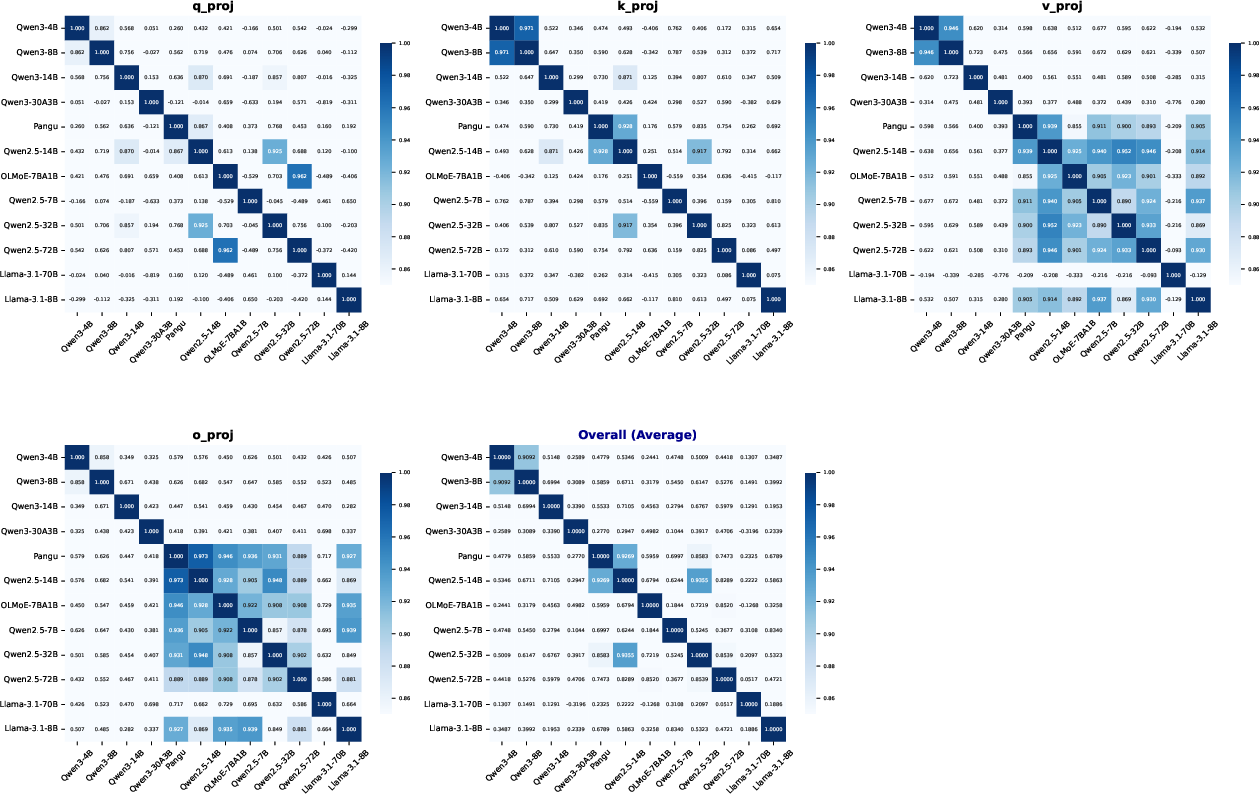
Figure 3: Comprehensive correlation analysis across twelve models from various families.
Validation Through Known Model Lineages
Validation experiments with models of known derivation, such as Llama-3.1-Nemotron, demonstrate the reliability of the proposed fingerprinting methodology for detecting lineage relationships and the methodology's robustness against common model adaptation techniques (Figure 4).
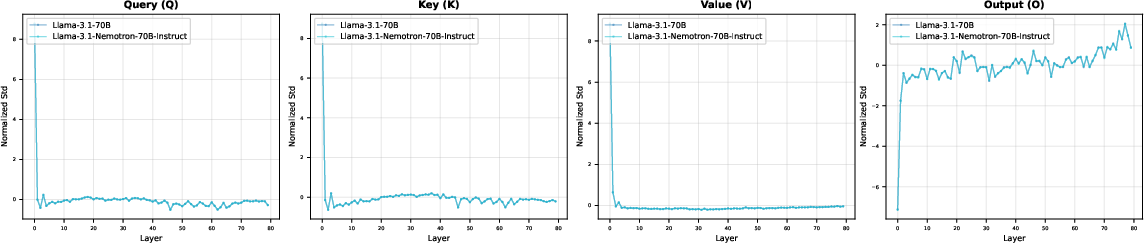
Figure 4: Attention parameter distribution comparison between Llama-3.1-70B and its fine-tuned derivative Llama-3.1-Nemotron-70B-Instruct.
Limitations
The effectiveness of the fingerprinting method improves with model size, as parameter distributions in smaller models may yield less distinguishable fingerprints due to statistical sampling limitations. Furthermore, application caution is advised for models intended for resource-constrained environments.
Broader Impacts
The paper has significant implications for intellectual property protection within the AI industry, offering new tools for verifying model origin and deterring unauthorized model reuse. In particular, it highlights potential risks of derivative models being misrepresented as independently developed efforts, a scenario exemplified by Huawei's Pangu Pro MoE and its suspected derivation from Qwen-2.5 14B.
Conclusion
This research presents a fingerprinting approach based on intrinsic statistical properties of attention parameters for robust LLM authentication and lineage detection. Through comprehensive validation, the study affirms that statistical properties embedded within attention matrices can reliably signal model lineage, offering an effective mechanism against potential model plagiarism and intellectual property violations. As the LLM landscape evolves, the adoption of such authentication measures becomes increasingly critical for maintaining fair competition and fostering innovation.

