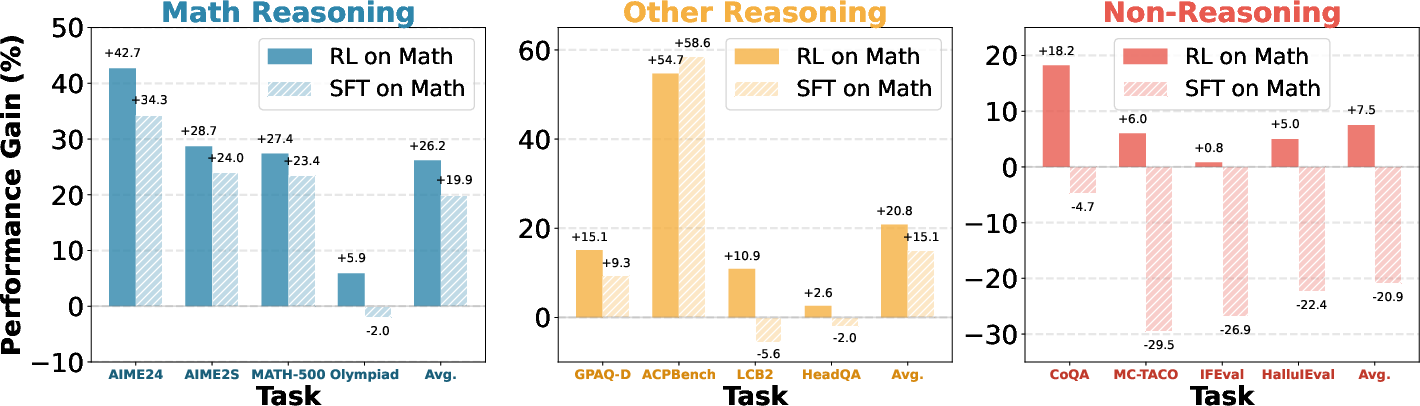
- The paper demonstrates that RL-tuned LLMs maintain robust transferability across tasks while SFT models show performance degradation.
- Methodology comparisons using controlled experiments on Qwen3-14B reveal that RL tuning incurs less latent representation drift, ensuring stable feature geometry.
- Token distribution analysis indicates that RL models selectively adjust task-relevant tokens, reducing catastrophic forgetting across diverse applications.
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
Introduction
The research detailed in the paper "Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning" explores the implications of mathematical reasoning abilities in LLMs for broader problem-solving skills. The paper assesses over twenty open-weight reasoning-tuned models, examining their ability to generalize from mathematical reasoning tasks to other reasoning and non-reasoning tasks. It highlights a significant observation: while models trained using reinforcement learning (RL) demonstrate high transferability across domains, those trained with supervised fine-tuning (SFT) often exhibit limited generality and even forget general capabilities. This study proposes a careful reconsideration of standard post-training practices, particularly the prevalent reliance on SFT-distilled data.
Methodology
The paper uses controlled experiments with Qwen3-14B models to explore transferability, utilizing math-only datasets for varying tuning methods—RL and SFT. The models are evaluated across a suite of tasks including math, scientific question answering, agent planning, coding, and instruction-following.
Experimental Setup:
- Data and Models: Qwen3-14B models were fine-tuned with high-quality math datasets using different methods.
Results and Analysis
The analysis uncovers that RL-tuned models maintain broader generalization capabilities, while SFT-tuned models exhibit substantial representation drift when transitioning to non-reasoning tasks.
Transferability
The Transferability Index (TI) is introduced to quantify models' domain transfer capabilities. The RL models consistently outperform SFT models, displaying superior transferability across diverse task categories.
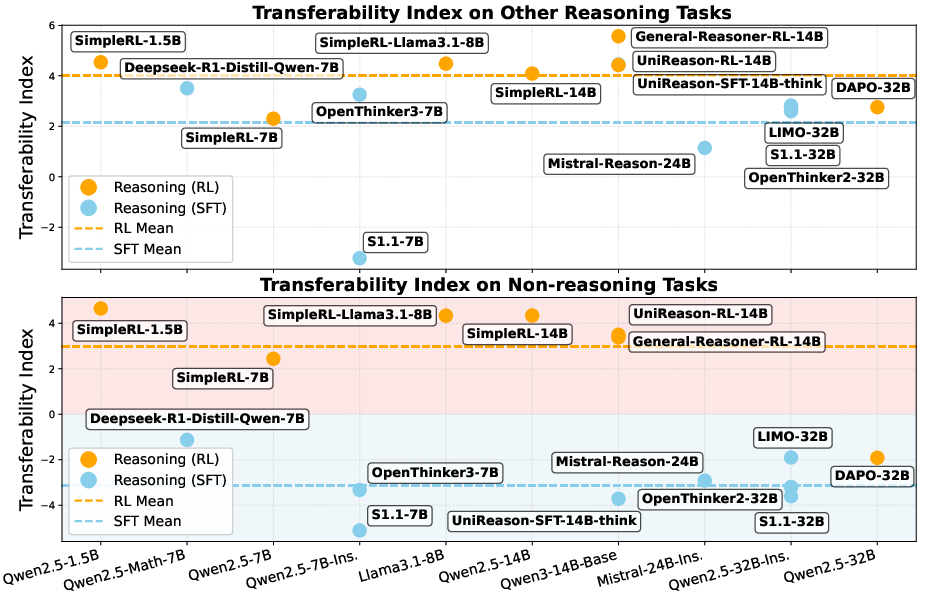
Figure 2: Transferability of mathematical reasoning to other reasoning and non-reasoning tasks.
Latent Representation Shift
PCA shift analysis reveals RL models exhibit smaller shifts in latent space representation compared to SFT models, indicating more stable feature geometry and less catastrophic forgetting.
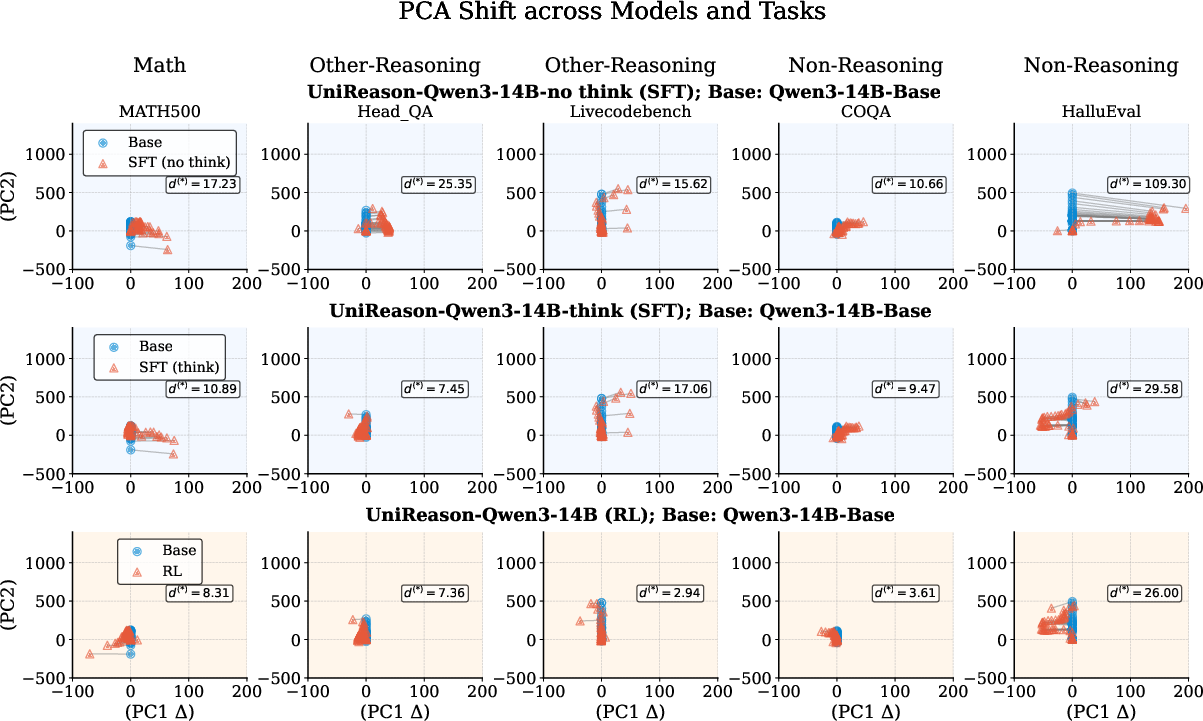
Figure 3: PCA shift of Qwen3-14B-Base across different training methods and tasks.
Token Distribution Shift
Token rank shift and KL divergence analyses show RL models undergo less distribution shift, selectively adjusting task-relevant tokens, contrary to SFT models which alter numerous irrelevant tokens.
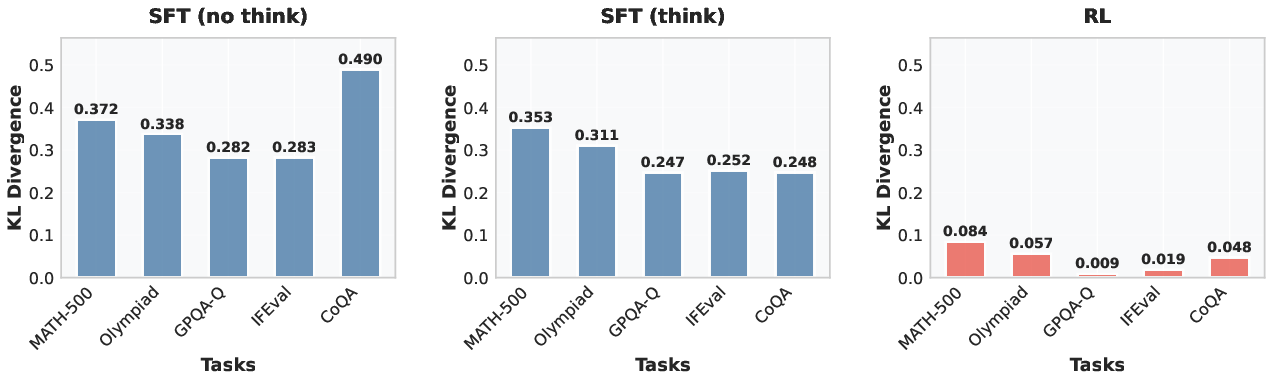
Figure 4: KL divergence analysis of RL and SFT models.
Discussion
The findings prompt the consideration of reinforcement learning as a viable post-training approach for developing robust and versatile LLMs. The RL paradigm's ability to maintain general-domain representation without catastrophic forgetting underpins its potential superiority over traditional SFT methods.
Conclusion
The paper argues for adopting RL-based training methods to optimize reasoning models while preserving general capabilities. This approach potentially facilitates the development of models that excel in both specialized reasoning tasks and general language processing applications.
The study significantly contributes to understanding the transferability of reasoning-tuned LLMs, paving the way for new strategies in model tuning and development. As AI continues to evolve, such insights are crucial for enhancing model usability across varied applications.