A Self-Training Approach for Whisper to Enhance Long Dysarthric Speech Recognition
Abstract: Dysarthric speech recognition (DSR) enhances the accessibility of smart devices for dysarthric speakers with limited mobility. Previously, DSR research was constrained by the fact that existing datasets typically consisted of isolated words, command phrases, and a limited number of sentences spoken by a few individuals. This constrained research to command-interaction systems and speaker adaptation. The Speech Accessibility Project (SAP) changed this by releasing a large and diverse English dysarthric dataset, leading to the SAP Challenge to build speaker- and text-independent DSR systems. We enhanced the Whisper model's performance on long dysarthric speech via a novel self-training method. This method increased training data and adapted the model to handle potentially incomplete speech segments encountered during inference. Our system achieved second place in both Word Error Rate and Semantic Score in the SAP Challenge.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping computers understand speech from people with dysarthria, a condition that makes speaking clearly difficult. The researchers focus on long recordings (not just short words or commands) and improve a well-known speech recognition model called Whisper so it can better handle this challenging speech.
Goals
The paper asks two main questions:
- How can we make Whisper recognize long, dysarthric speech more accurately?
- Can we create a system that works well for many different speakers and sentences (not just for one person or one set of phrases)?
Methods (explained simply)
Think of teaching a computer like training a student:
- First, you teach the student using clear, short examples with answers (short audio clips with correct text).
- Then, you let the student try longer, harder examples. The student writes down what they thinks was said (these are “pseudo-labels”).
- You keep only the parts the student seems confident about, and you add these to the training set to teach the student again.
- You repeat this a few times so the student gets better.
That’s the idea behind the paper’s “self-training” approach. Here are the key parts:
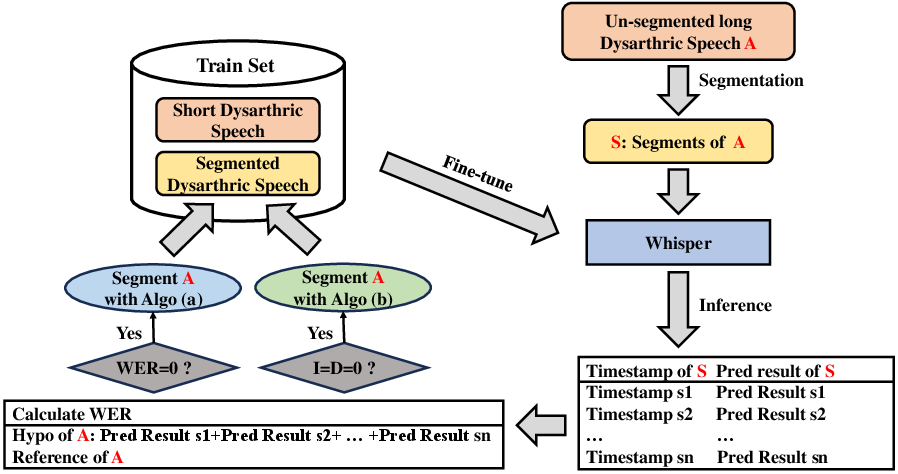
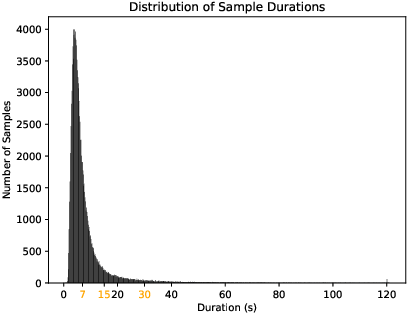
- Why long speech is hard: Whisper is designed to handle up to about 30 seconds at a time. Long recordings get cut off, which can make it miss words or finish sentences badly.
- Segmentation (cutting audio into pieces): The team slices long recordings into shorter chunks before recognition.
- Even Segmentation: Cut the audio into equal pieces (like slicing a long baguette into equal slices).
- VAD Segmentation: Use a tool called Voice Activity Detection (VAD) to find parts where someone is actually speaking, then group those parts into chunks.
- Decoding strategies (how the model chooses words):
- Greedy Search: Pick the best next word each time, quickly.
- Beam Search: Try several possible sentences at once and pick the best one (like exploring multiple paths before deciding).
- Prompting: Feed the text from the previous chunk to help the next chunk stay consistent. This sometimes helps meaning but can hurt accuracy.
- Teacher–Student Self-Training:
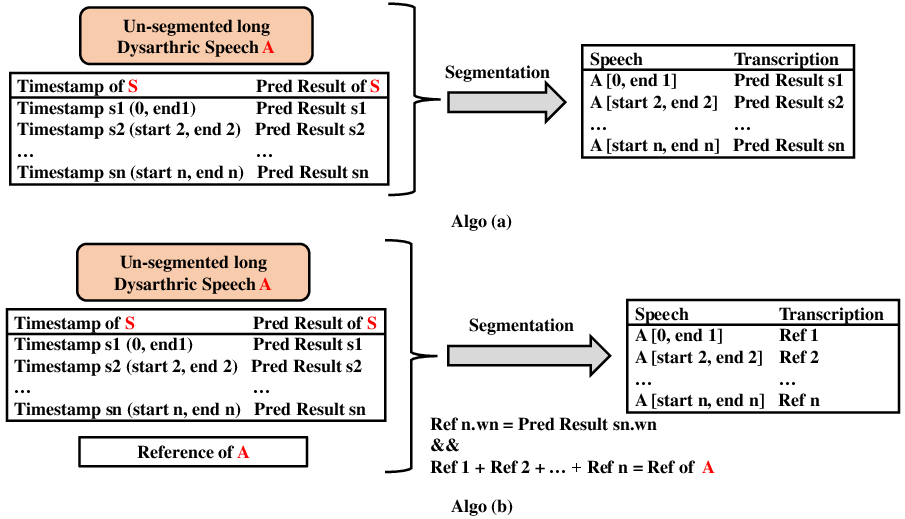
- If a chunk has WER = 0 (perfect match), they trust it.
- If WER isn’t zero but there are no extra or missing words (only substitutions), they still consider it useful.
- 4. Label and add those good chunks to the training set.
- 5. Train a “student” model on the bigger dataset. Make it the new teacher.
- 6. Repeat a few times.
- Matching the training format to Whisper: Whisper was originally trained on text where only the first letter is uppercase and the rest are lowercase (like “Hello world”). Training with the same format (“First-letter uppercase,” called F-U) gave better results than using ALL UPPERCASE (A-U).
Main Findings and Why They Matter
- Whisper performs best among several speech models when long audio is split into chunks before recognition.
- Using VAD-based segmentation + beam search (with a beam size around 10) + the F-U text format gave strong results.
- The self-training approach steadily improved accuracy over several rounds. After about three iterations, performance was best; too many iterations started to cause overfitting (the model focuses too much on the training data and gets worse on new data).
- The system ranked second in both Word Error Rate (WER) and Semantic Score (SemScore) in the SAP Challenge, a competition focused on dysarthric speech recognition.
- WER: Lower is better; it’s like counting spelling mistakes compared to the true answer.
- SemScore: Higher is better; it measures how similar the meaning is to the correct sentence, not just exact words.
These results matter because they show a practical way to make speech technology more accurate for people with speech disorders, especially for longer, real-world conversations.
Implications and Impact
- Accessibility: Better recognition of dysarthric speech helps people control devices, write messages, and use smart assistants more easily.
- General approach: The self-training plus smart segmentation strategy can be used to improve other models on long, difficult audio—not just Whisper.
- Real-world readiness: By adapting training to match how the system actually works at test time (short chunks from long audio), the model becomes more reliable in everyday use.
In short, this research provides a clear, effective recipe to make speech recognition fairer and more usable for people with dysarthria, moving beyond short commands toward long, natural speech.
Collections
Sign up for free to add this paper to one or more collections.