- The paper proposes a novel mixture-based output layer that mitigates rank bottlenecks in knowledge graph embedding models for improved link prediction.
- It employs a Mixture of Softmaxes formulation to enhance model expressivity with minimal increase in parameter costs.
- Empirical evaluations on datasets like ogbl-biokg show significant gains in ranking accuracy and distribution fidelity over traditional methods.
Breaking Rank Bottlenecks in Knowledge Graph Embeddings
Overview
The paper introduces methods to overcome rank bottlenecks in knowledge graph embedding models for link prediction tasks. These bottlenecks arise when the number of entities exceeds the embedding dimension, limiting model expressivity. The authors propose a mixture-based output layer inspired by language modeling to alleviate these constraints, showing enhanced performance on large-scale datasets with minimal increase in parameter costs.
Knowledge Graph Completion Tasks
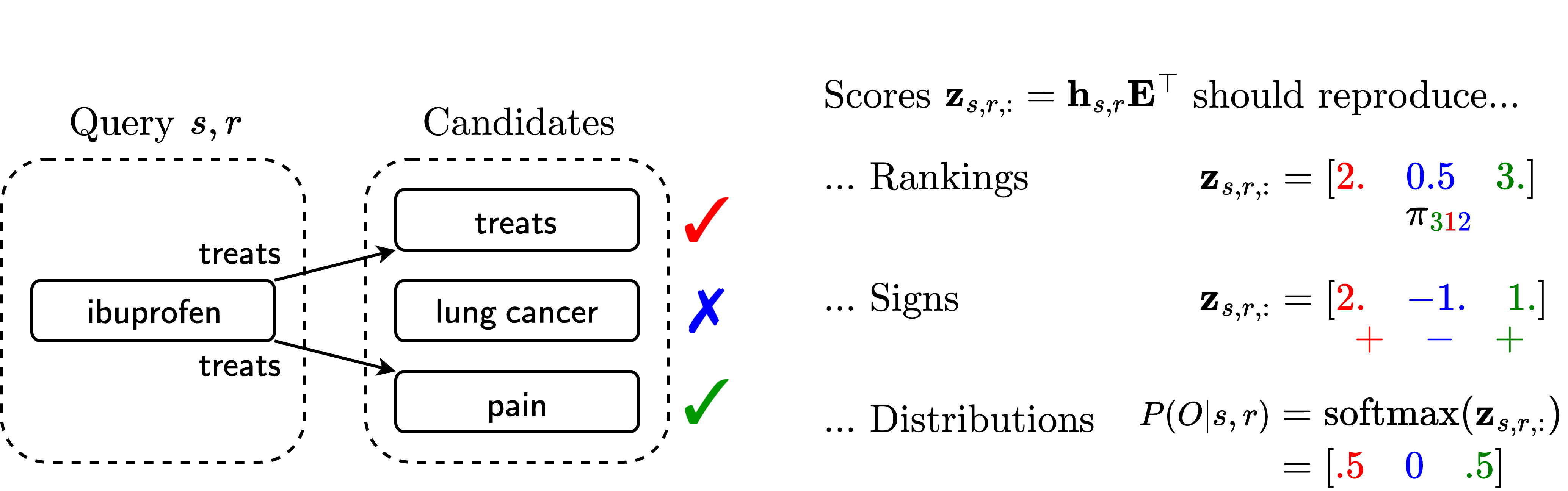
Knowledge Graph Completion (KGC) involves predicting missing triples in a knowledge graph (KG). For this, Knowledge Graph Embeddings (KGE) score entities given a subject-relation pair through vector-matrix multiplications, leading to potential rank bottlenecks. These issues impact three tasks:
- Ranking Reconstruction (RR): Ensures true history triples receive higher scores than negative ones, typically using margin-based loss.
- Sign Reconstruction (SR): Uses a binary classification on triples, aiming for positive scores for true triples.
- Distributional Reconstruction (DR): Models require assignments of specified scores to true/false triples, demanding precise reproduction of probability distributions over triples.
Rank Bottlenecks in KGEs
Rank bottlenecks occur due to low-rank linear subspaces confining feasible predictions, affecting ranking accuracy and distribution fidelity. This bottleneck arises from linear constraints related to embeddings' dimensionality which is much lower than the number of entities, leading to the following limitations:
Overcoming Bottlenecks: Mixture of Softmaxes (MoS)
The proposed solution, Mixture of Softmaxes (MoS), breaks rank bottlenecks by utilizing multiple softmax components. This non-linear mixture can model a more complex set of distributions than a single softmax layer:
- Formula: $P(O|s,r) = \sum_{k=1}^{K} \pi_k(\bh_{s,r})\, \text{softmax}(f_k(\bh_{s,r}) \bE^\top)$.
- Component-specific Parameters: Extending output capabilities with additional components incurs low parameter costs, facilitating scalability without drastic dimensional increases.
- Empirical Benefit: Extensive testing shows that models with MoS outperform traditional bottlenecked KGEs on large datasets while efficiently handling computation needs.
Implications and Future Directions
This approach especially shines when KGEs are challenged with large, dense knowledge graphs, as seen in the empirical results on datasets like ogbl-biokg. Future work could aim to refine the bounds on embedding dimensions further and explore the scalability of MoS in even larger KGs. Investigating other forms of output layers across different architectures beyond bilinear and neural networks would also be valuable.
Conclusion
The MoS layer provides a versatile tool for mitigating expressivity limitations due to rank bottlenecks in KGE models. By doing so, it offers practical improvements in modeling large-scale knowledge graphs with higher accuracy and in a computationally feasible manner.