- The paper presents CM-SSM, a novel architecture that integrates cross-modal state space modeling for real-time RGB-thermal semantic segmentation.
- It employs dual encoders with specialized CM-SS2D and CM-SSA modules to fuse RGB and thermal features, achieving impressive mIoU improvements on the CART dataset.
- Experimental results show enhanced performance (mIoU up to 85.9%) and high inference speeds (114 FPS), proving its potential for resource-constrained applications.
Cross-Modal State Space Modeling for Real-time RGB-Thermal Wild Scene Semantic Segmentation
This paper introduces CM-SSM, a novel and efficient RGB-thermal semantic segmentation architecture designed to address the computational limitations of existing methods in wild environments. By leveraging a cross-modal state space modeling (SSM) approach, CM-SSM achieves state-of-the-art performance on the CART dataset with fewer parameters and lower computational cost, offering a promising solution for resource-constrained systems.
Proposed Method: CM-SSM Architecture
The CM-SSM architecture, illustrated in (Figure 1), adopts a typical encoder-decoder structure. It consists of two image encoders for extracting features from RGB and thermal images, four CM-SSA modules for RGB-T feature fusion across four stages, and an MLP decoder for predicting semantic segmentation maps. The EfficientVit-B1 is used for feature extraction.
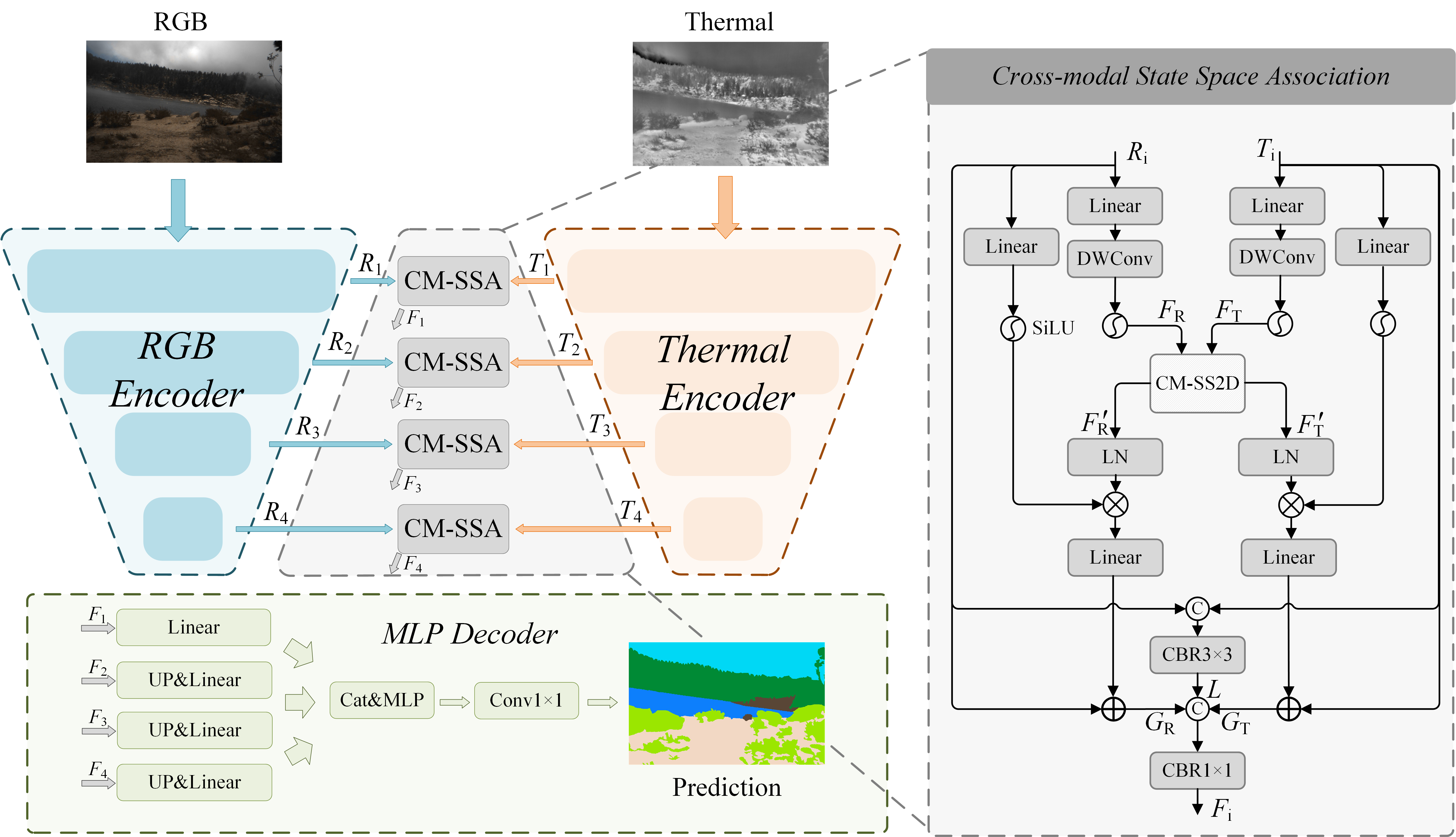
Figure 1: Illustration of CM-SSM. CM-SSM consists of two image encoders to extract the feature of RGB and thermal images, four CM-SSA modules to perform RGB-T feature fusion in four stages, and an MLP decoder to predict the semantic segmentation maps.
To achieve multi-modal feature fusion, the paper introduces two key modules: the cross-modal 2D-selective-scan (CM-SS2D) module and the cross-modal state space association (CM-SSA) module. The CM-SS2D module constructs cross-modal vision feature sequences through 'RGB–thermal–RGB' scanning and derives hidden state representations of one modality from the other. The CM-SSA module effectively integrates global associations from CM-SS2D with local spatial features extracted through convolutional operations.
Cross-Modal 2D-Selective-Scan (CM-SS2D)
The CM-SS2D module, depicted in (Figure 2), consists of three steps: cross-modal selective scanning, cross-modal state space modeling, and scan merging. This module is designed to construct the cross-modal SSM by building cross-modal vision sequences and generating the hidden state of one modality from the other.
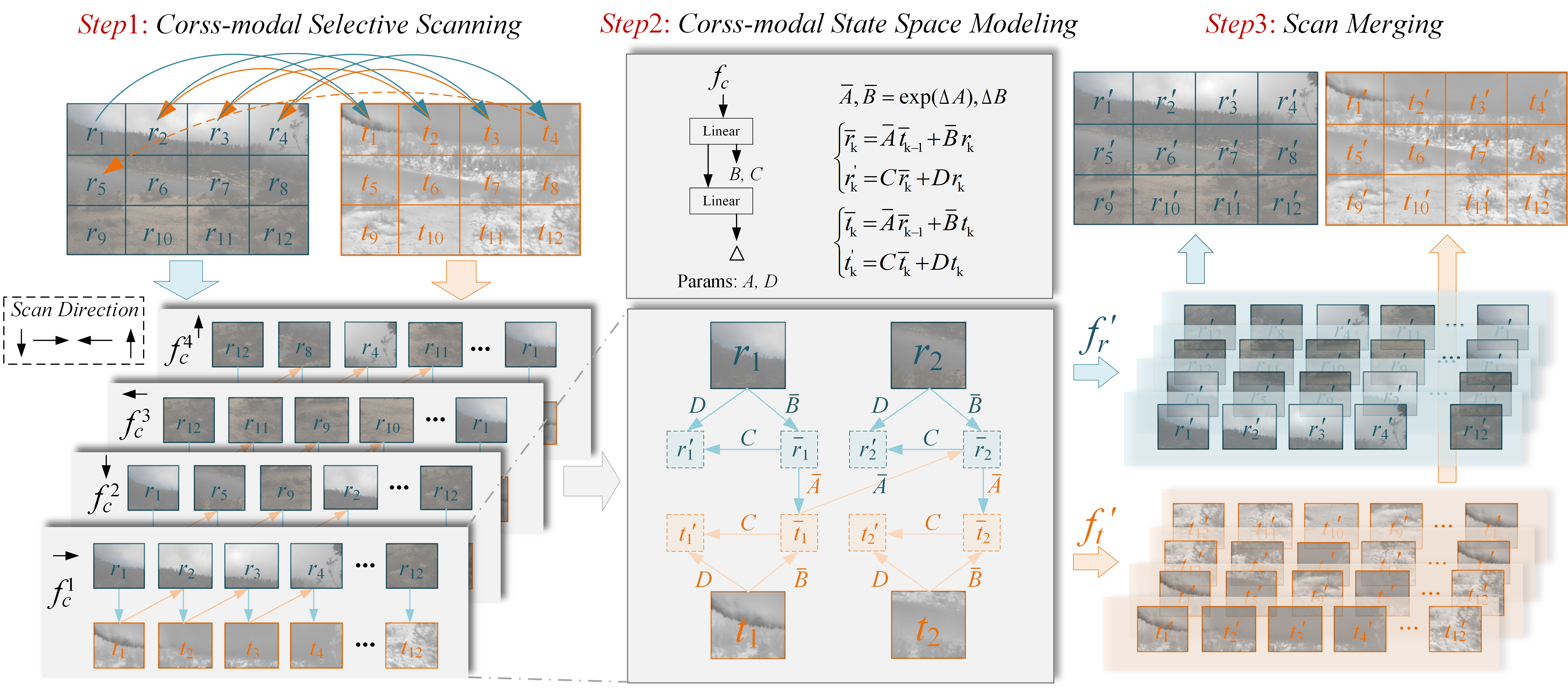
Figure 2: Illustration of CM-SS2D. CM-SS2D consists of three steps: 1) cross-modal selective scanning, 2) cross-modal state space modeling, and 3) scan merging.
In the cross-modal selective scanning step, the module builds the cross-modal visual feature sequence by performing cross-modal scanning in the sequence of 'RGB–thermal–RGB', obtaining the cross-modal visual feature sequence $f_{\text{c} = \{f_{\text{c}^1, f_{\text{c}^2, f_{\text{c}^3, f_{\text{c}^4\} \in \mathbb{R}^{4 \times \text{C} \times 2\text{HW}}$. Then, the hidden state rˉk for the RGB modality is built using the current input rk and the last state of thermal modality tˉk-1, while the hidden state $\bar{t}_{\text{k}$ for the thermal modality is derived using the current input $t_{\text{k}$ and the last state of RGB modality rˉk−1. Finally, the rectified RGB and thermal features from four directions are summed up to obtain $F_{\text{R}'$ and $F_{\text{T}' \in \mathbb{R}^{\text{C} \times \text{H} \times \text{W}$.
Cross-Modal State Space Association (CM-SSA)
The CM-SSA module is proposed to combine the global association from CM-SS2D and local association from convolution. It first achieves global association through CM-SS2D, with linear, activation, and layer-normalization layers appended. The global association features $G_{\text{R}$ and $G_{\text{T}$ are derived from residual connection. The local association features L is obtained from the convolution. Finally, GR, $G_{\text{T}$ and L are combined to incorporate both local and global associations.
Experimental Results
The CM-SSM was evaluated on the CART and PST900 datasets, demonstrating its superiority over SOTA methods. On the CART dataset, CM-SSM achieved the best performance with an mIoU of 74.6%, surpassing CMX by 0.6% in mIoU while significantly reducing FLOPs and parameters. On the PST900 dataset, CM-SSM achieved the best performance with an mIoU of 85.9%. The model achieved an inference speed of 114 FPS on an RTX 4090 GPU with 12.59M parameters.

Figure 3: Visual diagram of the segmentation maps of CM-SSM and some SOTA models on the CART dataset.
Ablation Studies
Ablation studies were conducted to prove the effectiveness of the proposed CM-SS2D and CM-SSA modules. The results demonstrate that CM-SSM achieves the best improvement compared to the baseline variation with the addition operation to fuse RGB-T features, with a 2.0% increase in mIoU. The necessity of the CM-SS2D module is confirmed by a 1.3% decrease in mIoU when the module is removed from CM-SSA.
Conclusion
The paper presents CM-SSM, a real-time RGB-T semantic segmentation model that improves the accuracy of RGB-T segmentation. The model establishes global correlation across various modalities while keeping linear computational complexity with respect to image resolution. The CM-SSM achieves an inference speed of 114 frames per second on an RTX 4090 GPU, with 12.59M parameters. Future work will explore the use of knowledge distillation to enhance the generalization ability of lightweight models across diverse terrains.

