- The paper introduces Mercury models that leverage diffusion processes to achieve ultra-fast performance in language modeling.
- It employs a Transformer architecture with dynamic refinement over trillions of tokens, optimizing speed and quality on coding tasks.
- Benchmark results show Mercury models outperform traditional autoregressive LLMs in throughput and latency while maintaining competitive quality.
Mercury: Ultra-Fast LLMs Based on Diffusion
The paper "Mercury: Ultra-Fast LLMs Based on Diffusion" introduces the Mercury family of diffusion-based LLMs (dLLMs) designed to significantly enhance the speed-quality trade-off in LLM implementations, with a particular emphasis on coding applications.
Introduction to Mercury Models
The Mercury models are built upon diffusion processes rather than traditional autoregressive methods, providing notable advantages in parallel token generation, speed, and efficiency. The adoption of diffusion models, traditionally successful in image and video generation, marks a novel approach to addressing the challenges of speed and control in LLMs for text. Mercury Coder models, specifically, implement this approach to enhance coding tasks, achieving higher throughput on standard GPU hardware like the NVIDIA H100.
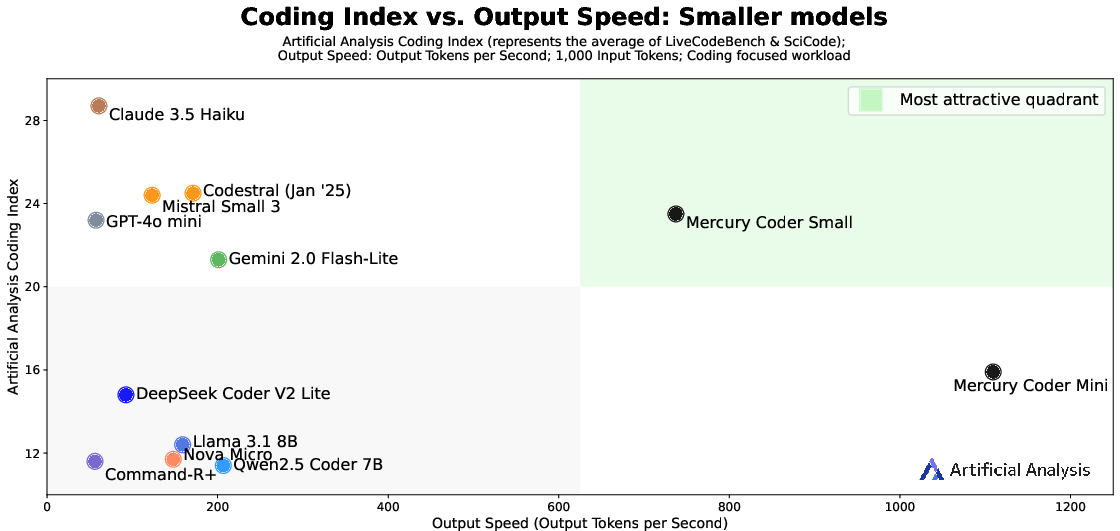
Figure 1: Quality vs. Speed Trade-offs for Mercury Coder models, demonstrating superior throughput while maintaining quality.
Architecture and Training Details
The Mercury models leverage a Transformer architecture, optimized for diffusion processes. They engage in a dynamic refinement method, transforming random noise into data-consistent samples through learned denoising steps. This process enables significant speed improvements by utilizing high parallelization capabilities, thus elevating computational efficiency and arithmetic intensity.
The training regimen involves trillions of tokens collected from web crawls and proprietary datasets, conducted on large clusters of NVIDIA H100 GPUs. The use of diffusion provides fine-grained control over token transformations and allows for novel alignment and tuning methods, enhancing functionality in diverse generative tasks.
Benchmark Comparisons
The Mercury models are evaluated on various standard code generation benchmarks, including HumanEval, MBPP, and MultiPL-E. These benchmarks assess code correctness, inference speed, and multi-language generation capabilities.
The Mercury Coder Mini, despite being a smaller model, achieves far superior throughput compared to open-weight models and even surpasses many established speed-optimized frontier models. This performance is coupled with maintaining competitive quality, as seen in numerous benchmarks across diverse programming languages.
Real World Implications
In practical applications, particularly those requiring rapid execution such as auto-completion and code snippets, Mercury models drastically improve latency and responsiveness. The advancement extends to scenarios such as Copilot Arena, where Mercury models are recognized for their low latency and user-preference in code completion tasks.
Adaptation and Inference
Mercury models support a range of generation modalities, such as zero-shot and few-shot prompting, and are fully adaptable to existing LLM use-cases with backward compatibility to existing APIs. This feature enables smooth transitions from traditional autoregressive models to Mercury's diffusion models, providing new opportunities for rapid iteration and deployment in latency-sensitive environments.
Implications and Future Directions
Mercury models embody significant advancements in diffusion-based LLMs, pushing the boundaries of what can be achieved in terms of speed without sacrificing quality. The diffusion approach allows for fine-tuned control and adaptability across different tasks, opening new research avenues in efficient, scalable AI implementations across diverse domains.
Conclusion
The Mercury models represent a significant step forward in LLM development by exploiting the strengths of diffusion processes. Their superior speed efficiency coupled with high-quality outputs in code-centric applications demonstrates their potential as robust and viable alternatives to current state-of-the-art autoregressive models. Future developments will likely focus on further scaling and adapting these models across more complex and diverse generative tasks.

