- The paper introduces AQI, an intrinsic diagnostic that leverages latent geometry to distinguish safe versus unsafe activations in LLMs.
- It employs layerwise pooled representations and cluster divergence metrics to reveal refined alignment changes beyond surface-level refusal rates.
- AQI demonstrates a causal correlation with behavioral flip rates and remains robust under adversarial perturbations, guiding safety-centric fine-tuning.
Intrinsic Alignment Diagnostics in LLMs: The Alignment Quality Index (AQI) Framework
Introduction
The paper "Alignment Quality Index (AQI): Beyond Refusals: AQI as an Intrinsic Alignment Diagnostic via Latent Geometry, Cluster Divergence, and Layerwise Pooled Representations" (2506.13901) introduces the Alignment Quality Index (AQI), a novel metric designed to intrinsically diagnose and quantify alignment in LLMs beyond mere refusal rates and surface-level toxic behaviors. Leveraging advances in representation analysis, AQI evaluates the geometric separation between safe and unsafe completions within layerwise latent manifolds, enabling robust, interpretable alignment auditing immune to surface-level adversarial manipulation. The authors position AQI as a unifying, model-agnostic approach for tracking latent drift, assessing alignment robustness, and guiding the fine-tuning of safety-centric interventions.
Layerwise Representation and Alignment Geometry
AQI is predicated on the idea that alignment emerges from intrinsic geometry within LLM latent spaces rather than solely observable textual outputs. Its methodology utilizes layerwise pooled activations and cluster divergence metrics to distinguish safe and unsafe completion manifolds. The paper details how parameter updates during task-specific and alignment-critical finetuning manifest in distinct layer regions: mid-layers (L12–20) are dominated by task-specific adaptations, while deeper layers (L25–30) concentrate alignment-driven refinements.

Figure 1: Layerwise distributions of parameter updates reveal a shift from general to alignment-specific representations at increasing depth.
Notably, AQI exposes latent separation across layers, with representational divergence between safe and unsafe prompts becoming more pronounced as models undergo safety-oriented instruction and DPO tuning. This layerwise stratification reflects the transition from generic semantic clustering to alignment-focused geometry.
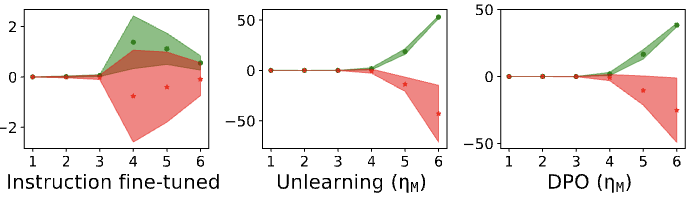
Figure 2: Safety fine-tuning induces stronger representational separation, increasing layerwise scores between safe and unsafe activations.
Cluster Divergence, Latent Separation, and Robustness
The authors demonstrate that AQI's geometric clustering is sensitive to adversarial prompting and surface-level perturbations, capturing latent collapse that conventional detox classifiers or simple refusal metrics miss. Early layers show overlap in activations, but deeper layers exhibit clear partitioning indicative of robust alignment.
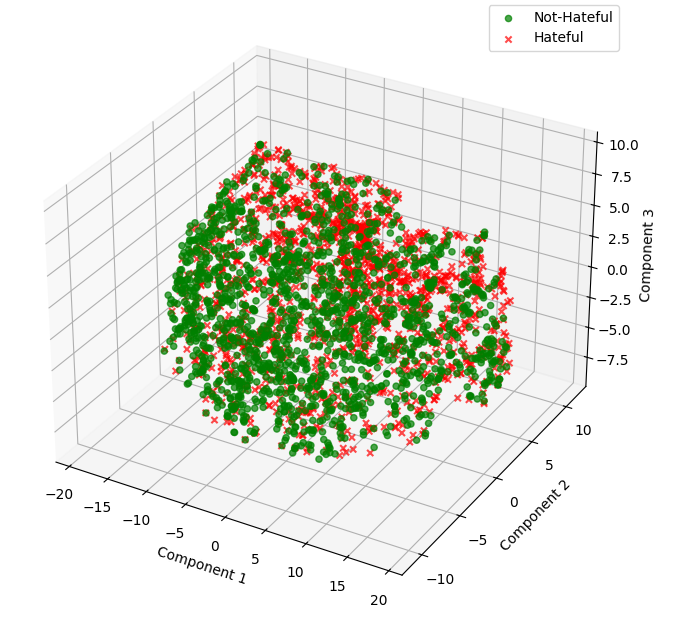
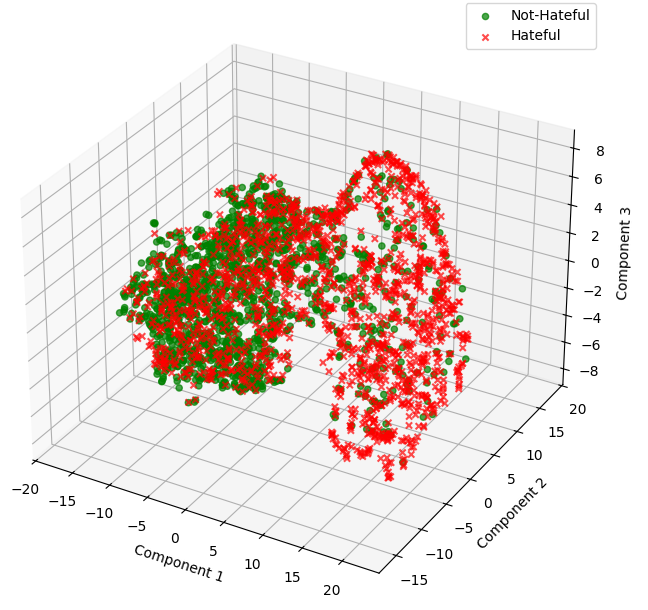
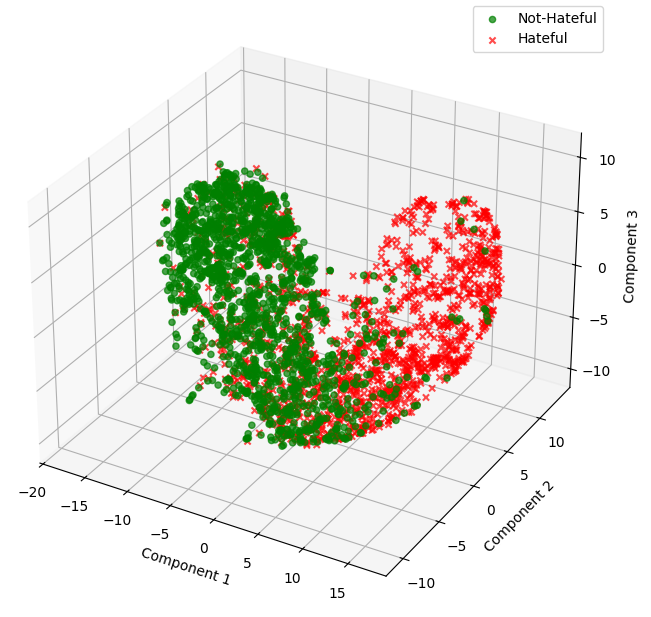
Figure 3: Deep layers form well-separated latent clusters for safe and unsafe completions, quantified by Xie-Beni Index.
AQI maintains a low variance in alignment quantification across stochastic generation conditions and prompt drift, outperforming traditional metrics such as Refusal Rate (RR) or Toxicity in adversarial evaluation contexts.
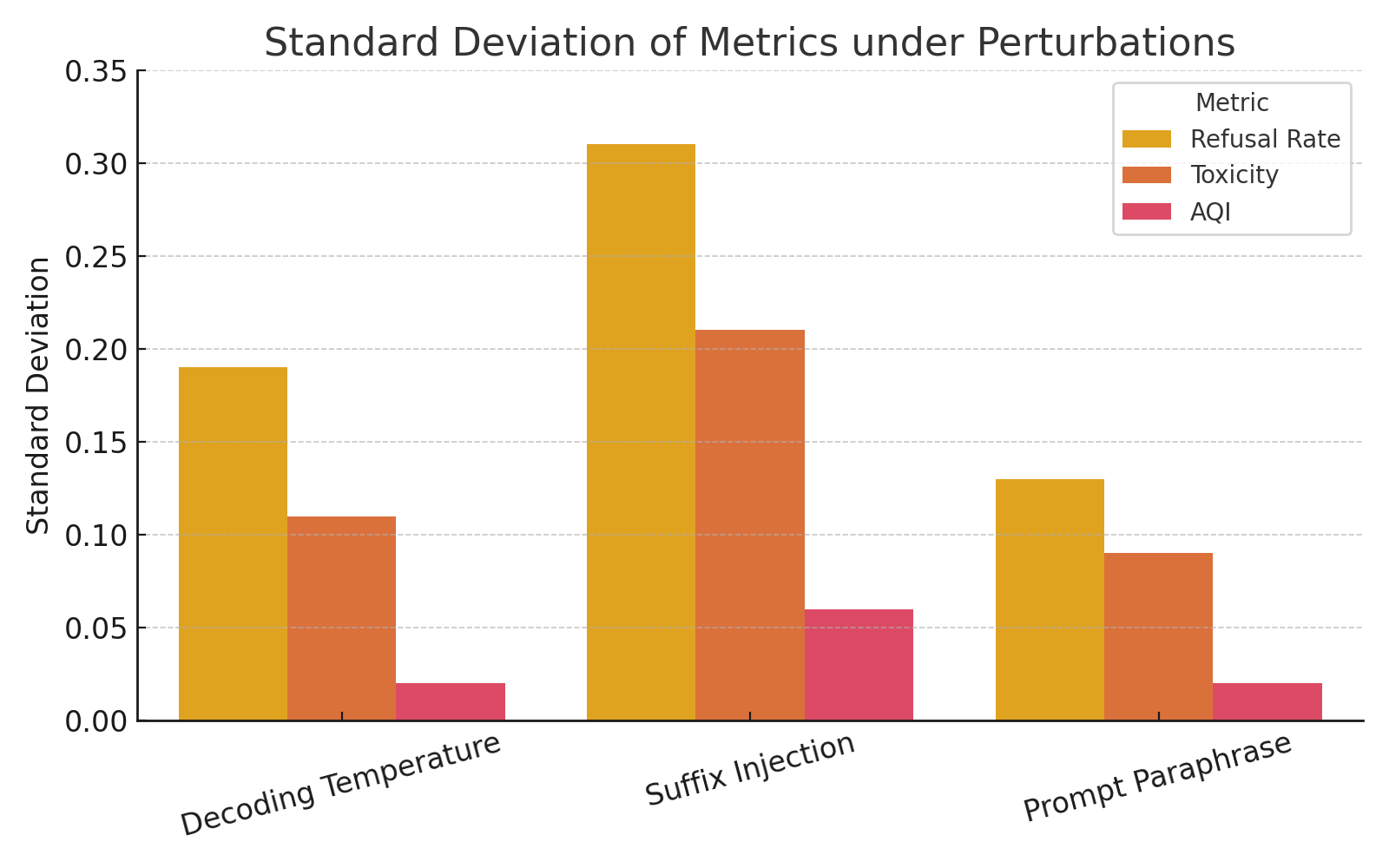
Figure 4: AQI variance under perturbations is consistently lower than RR and Detoxify-based metrics due to geometric robustness.
Moreover, AQI detects latent misalignment signals prior to overt behavioral violations, deflecting early under increasing jailbreak severity and semantic collapse.
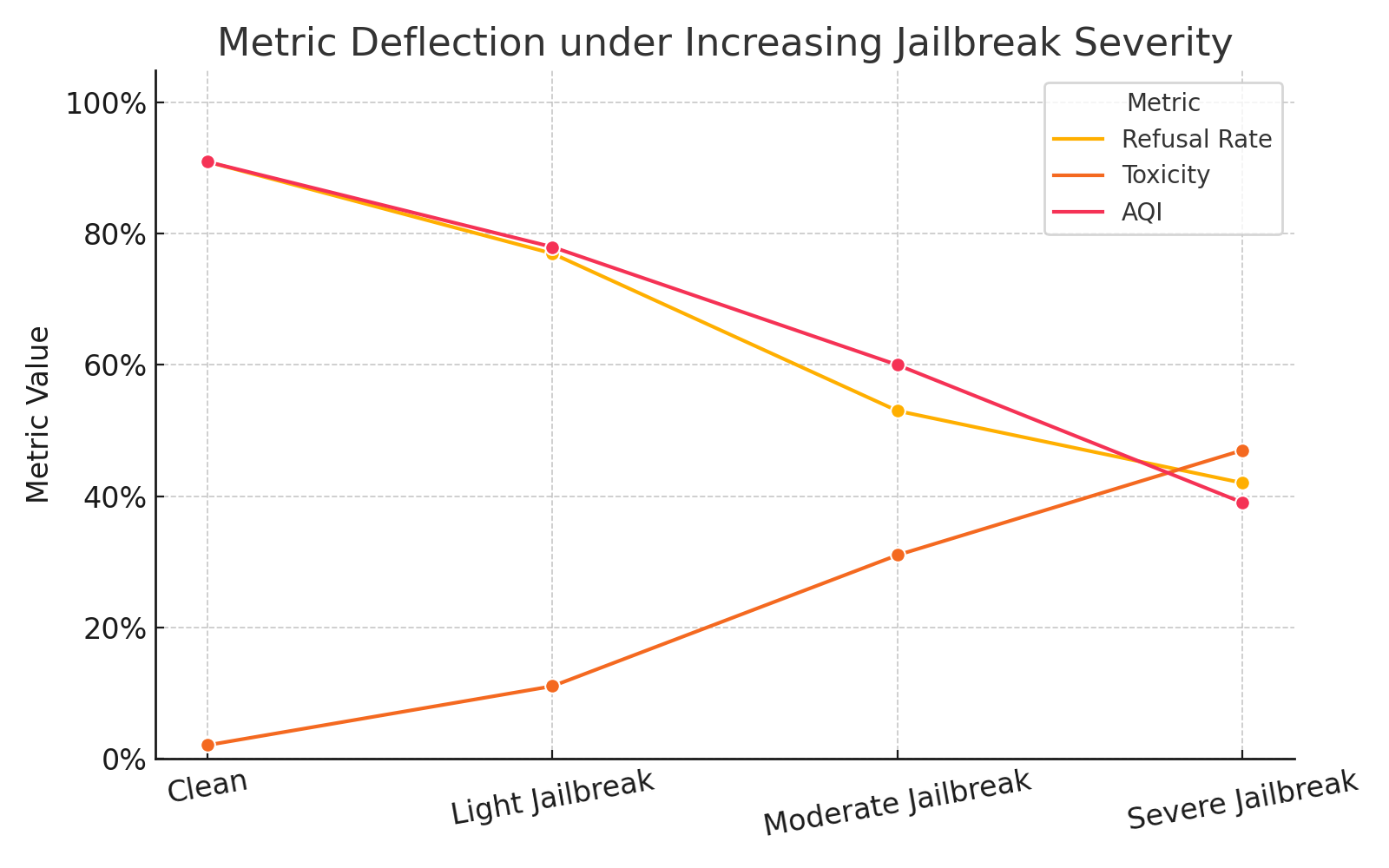
Figure 5: AQI sharply deflects under adversarial suffix conditions, exposing latent misalignment before surface output violations.
The AQI drops when unsafe completions collapse into the safe manifold, which remains undetected by other metrics, thereby revealing semantic entanglement and vulnerabilities.
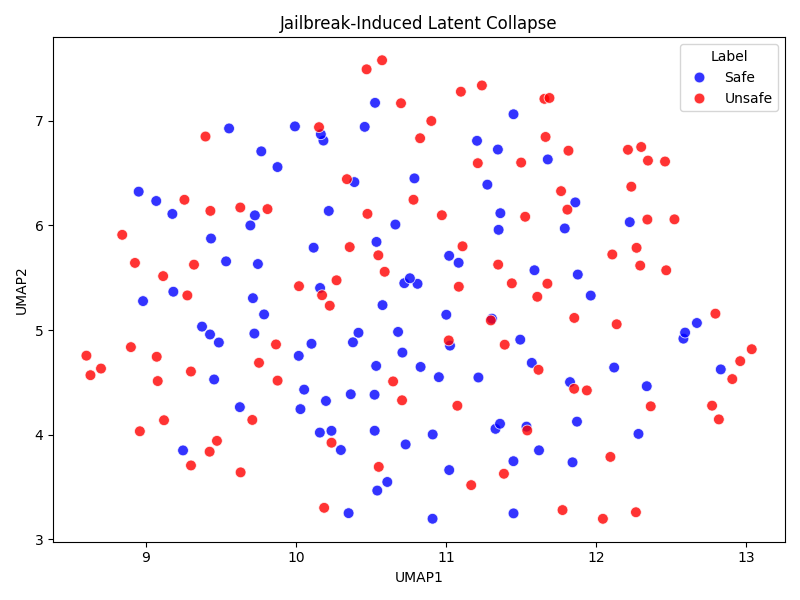
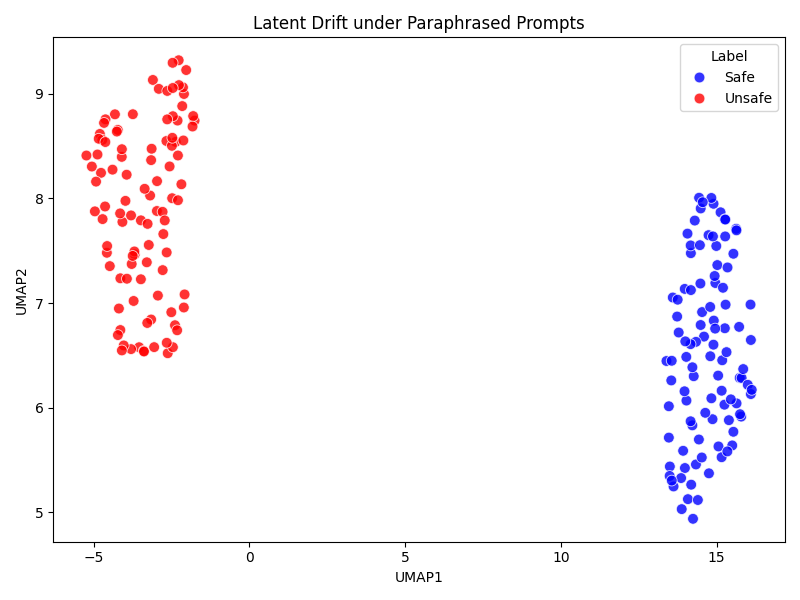
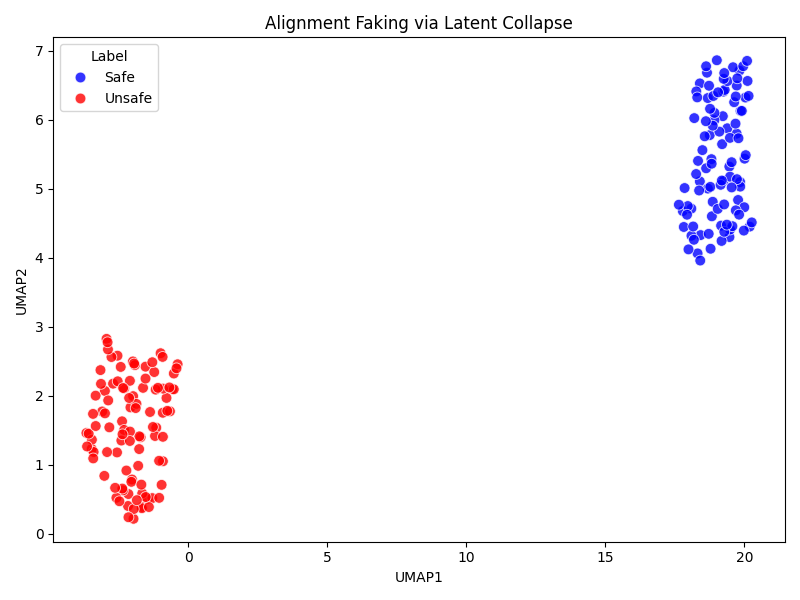
Figure 6: Unsafe completions collapse toward the safe latent manifold under adversarial suffixes, causing AQI decline.
Architectural, Fine-Tuning, and Batch Effects
AQI is further applied to analyze model-specific and architectural nuances. In mixture-of-experts models (e.g., Mixtral-8x7B), expert diversity causes intra-model alignment variance, with some experts maintaining cluster separation while others exhibit latent collapse.
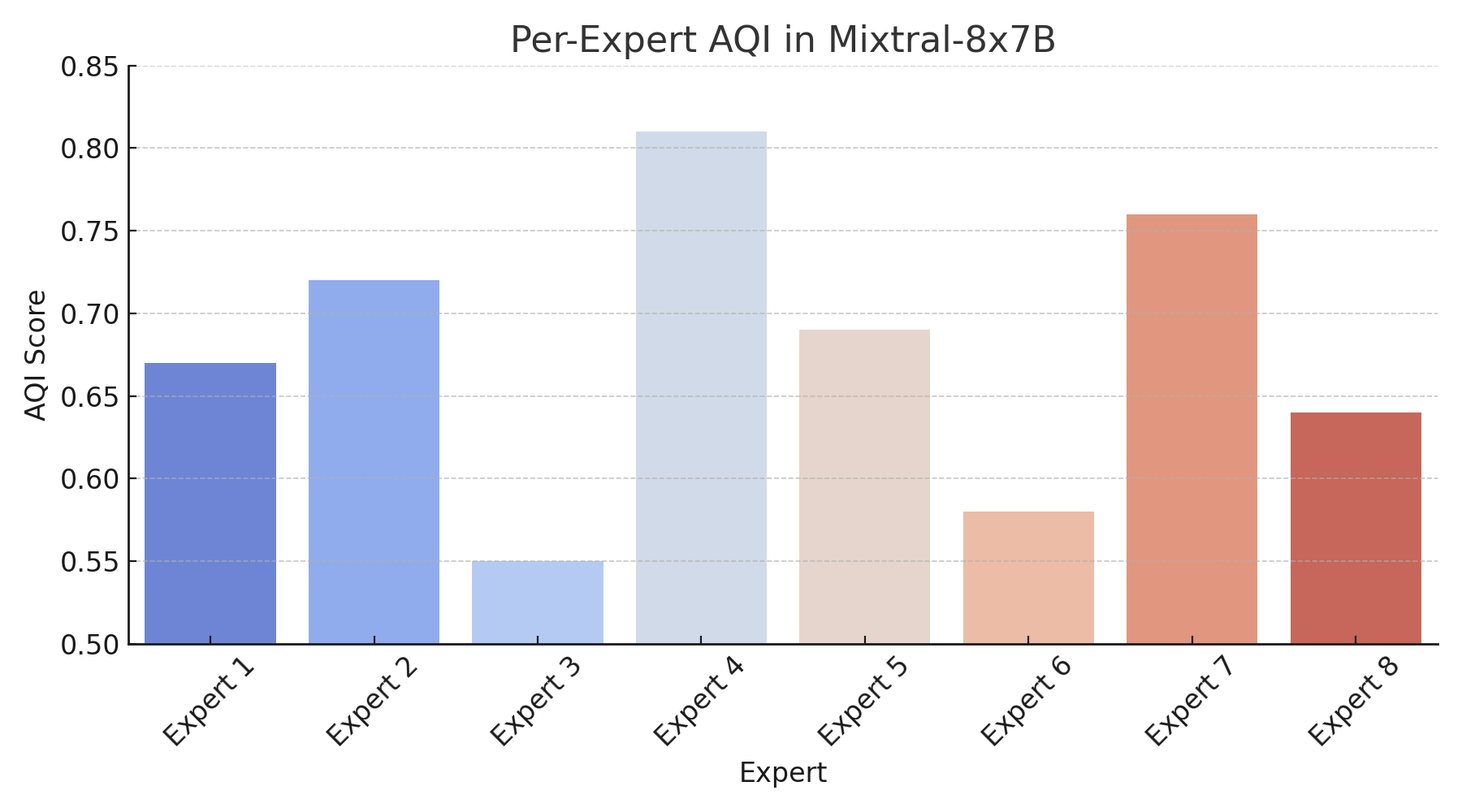
Figure 7: Expert-level AQI reveals intra-model alignment diversity and manifold collapse in mixture models.
Fine-tuning strategies such as LoRA-supervised constitutional tuning mitigate geometry distortion compared to rigid LoRA tuning, preserving alignment separation.
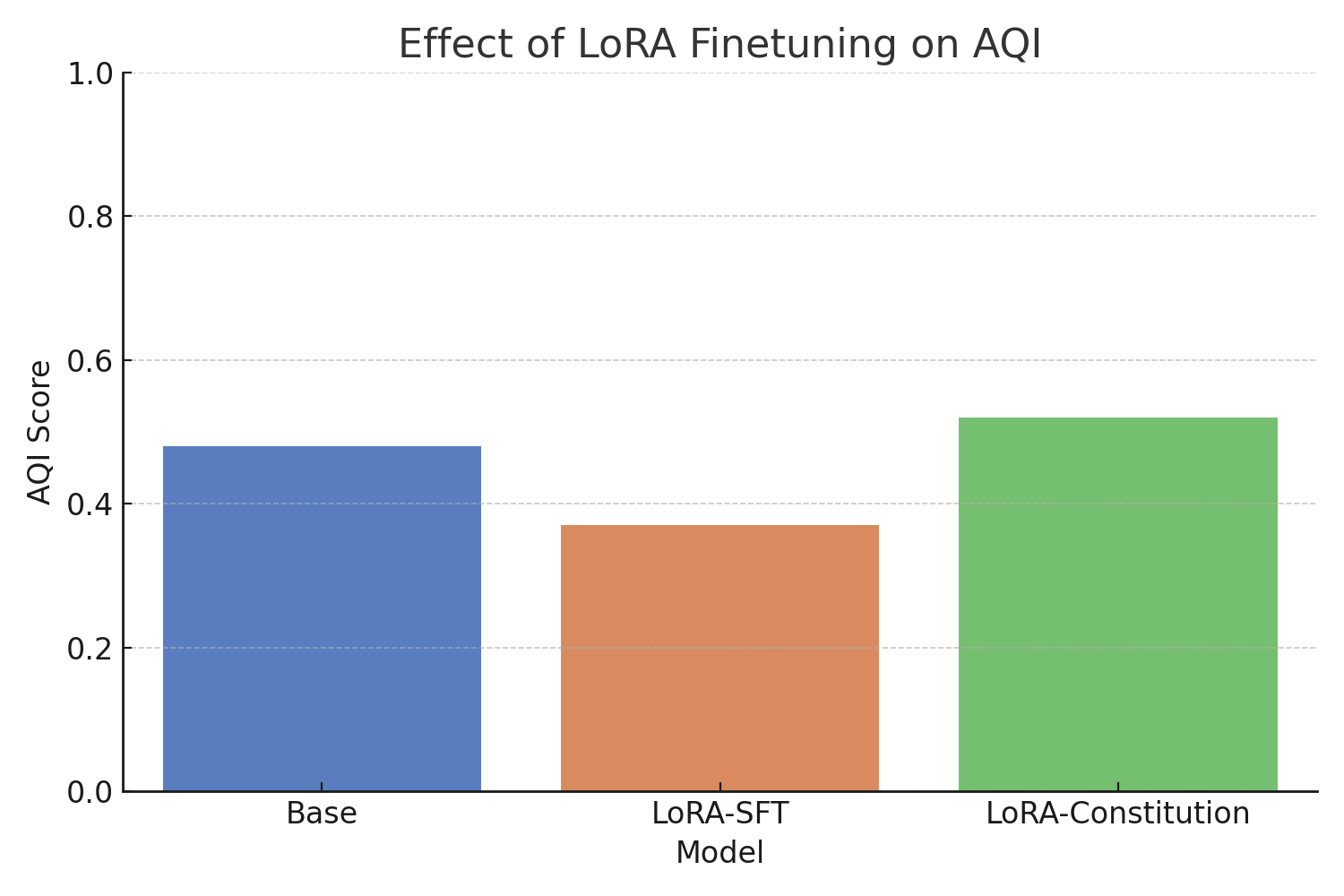
Figure 8: LoRA-constitutional tuning effectively preserves AQI and cluster separability.
Batch size exerts significant influence: smaller batches inflate metrics via sparse cluster coverage, whereas larger batches stabilize clustering, leading to robust metric convergence.
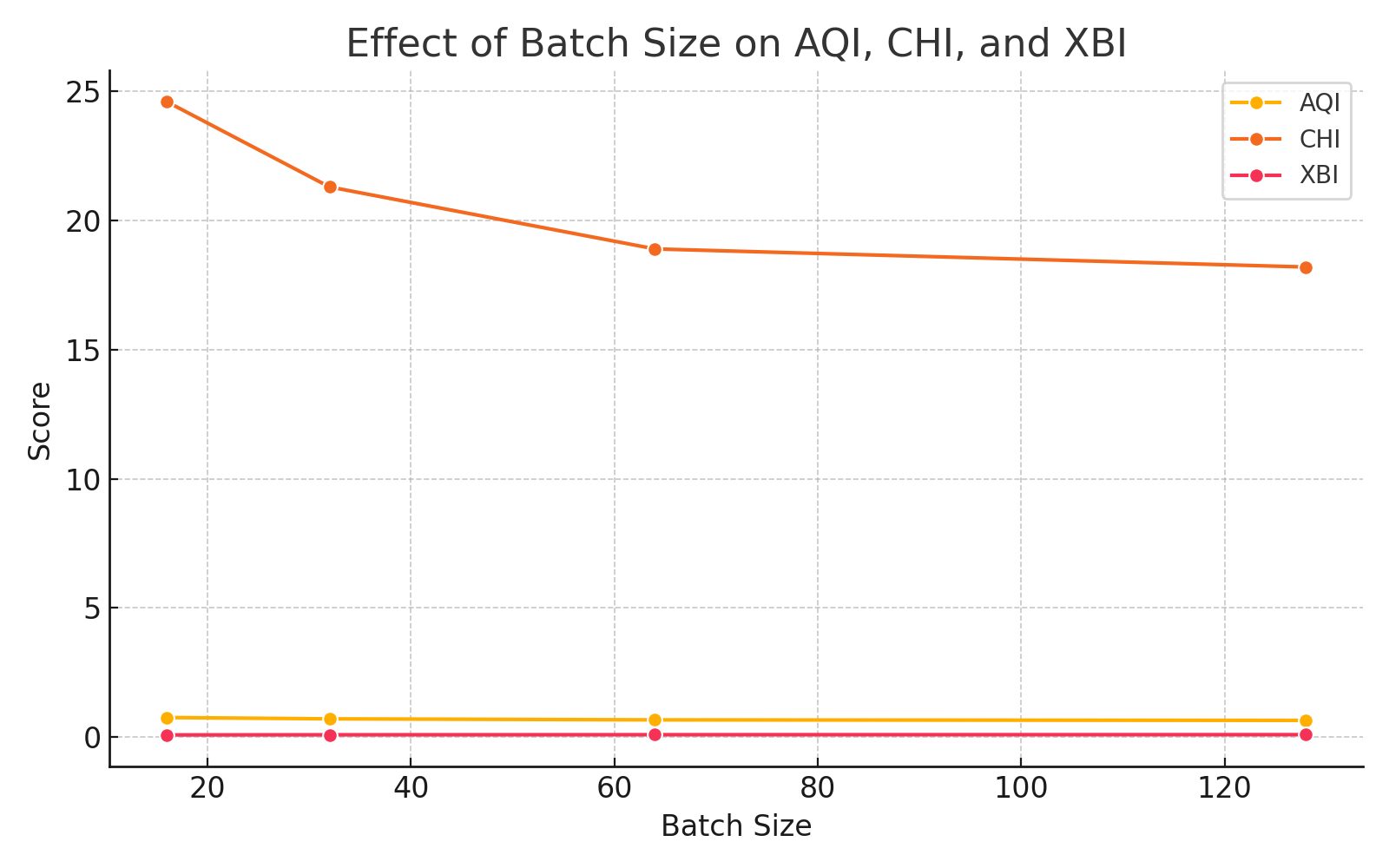
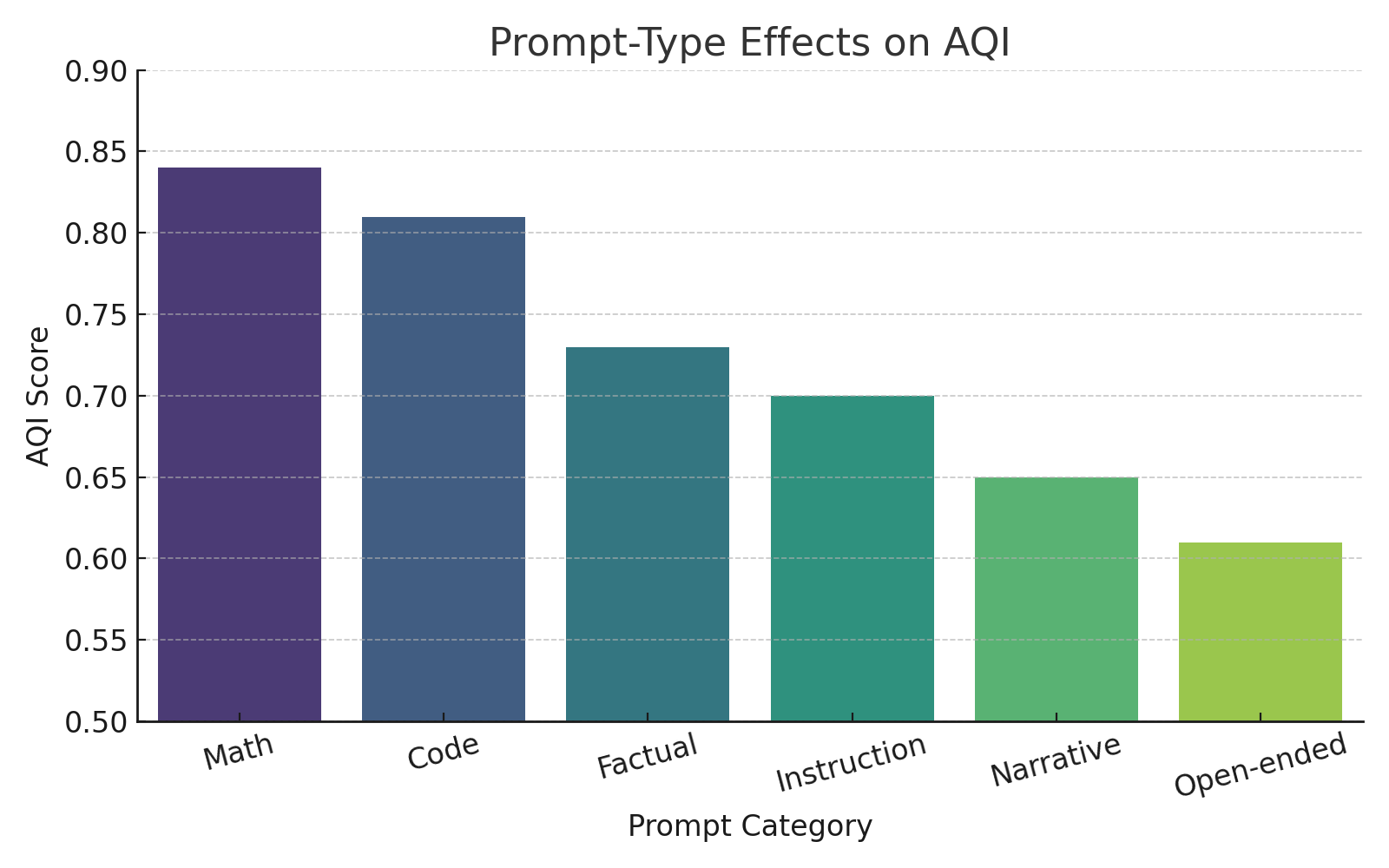
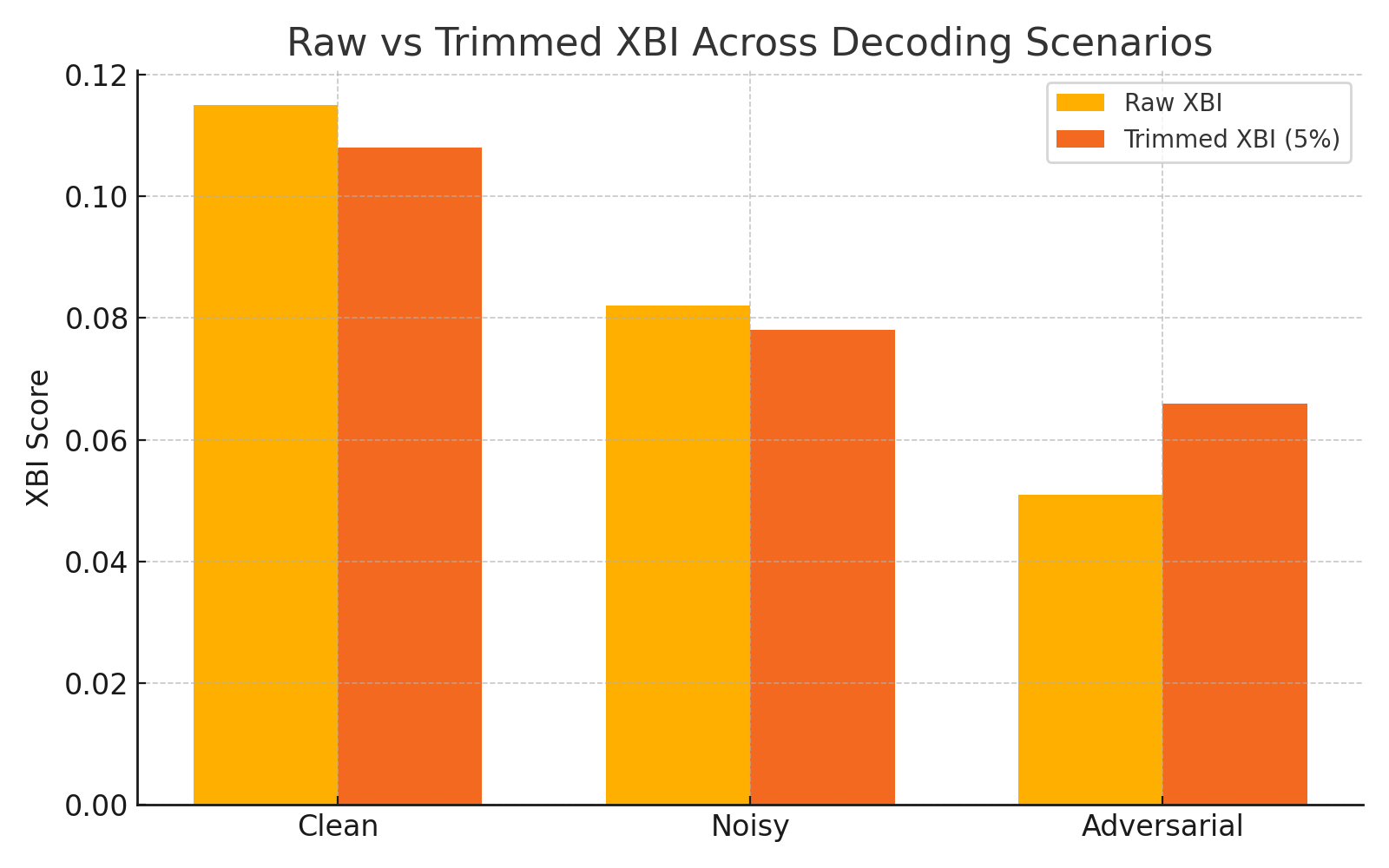
Figure 9: Increasing batch size reduces inflated alignment scores and stabilizes clustering metrics.
AQI computation remains computationally feasible, scaling sublinearly with batch size due to optimizations in activation pooling and clustering.
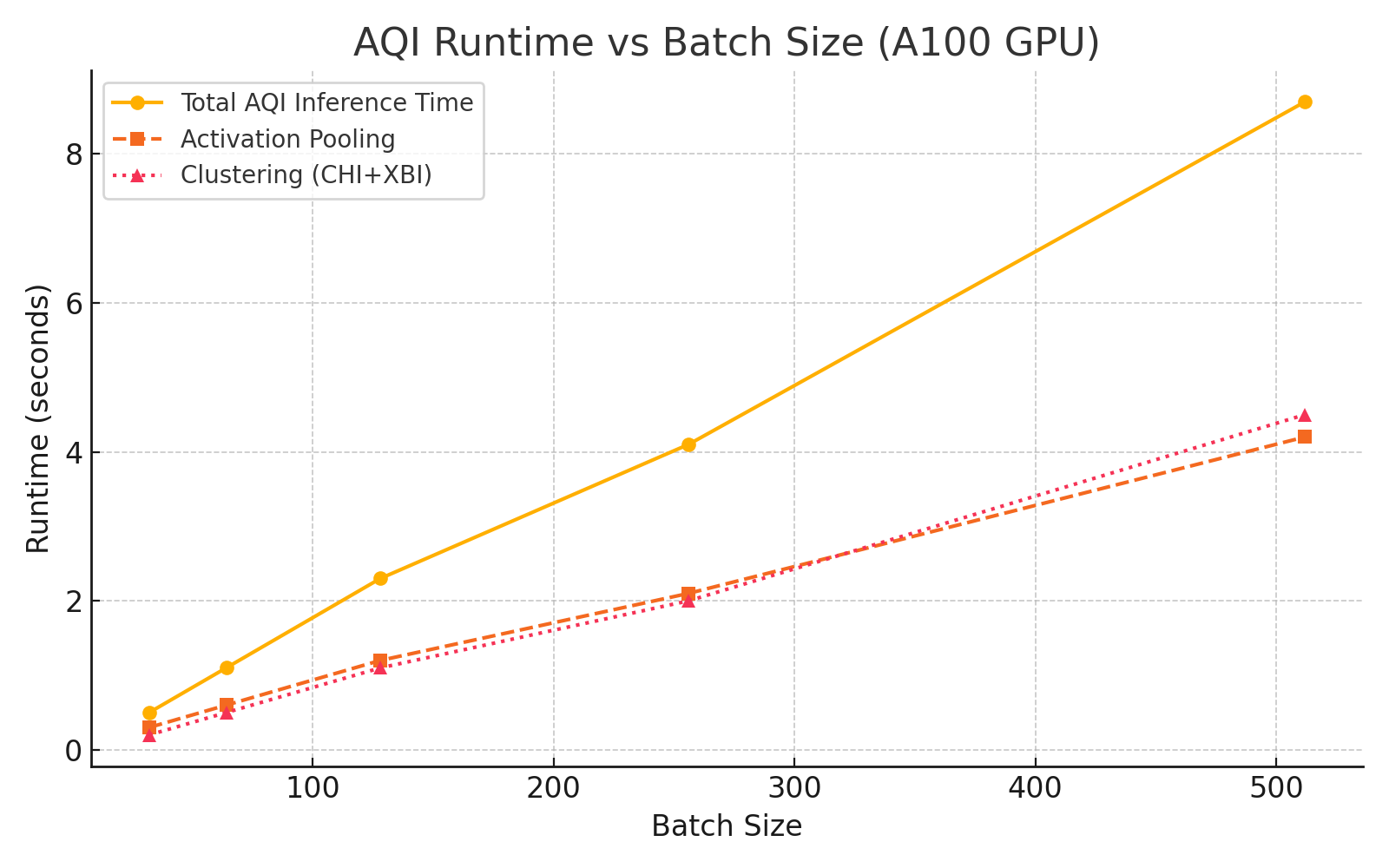
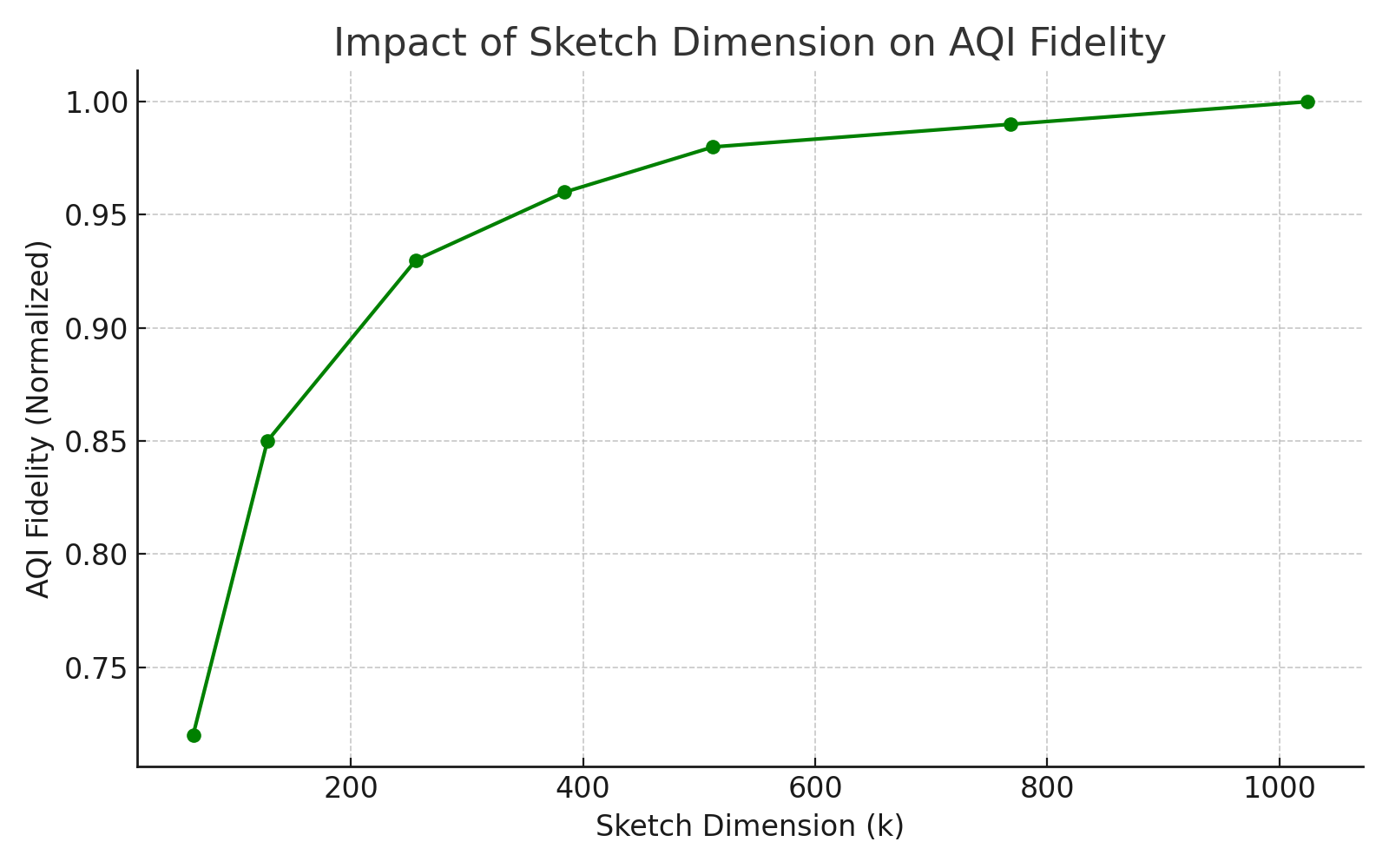
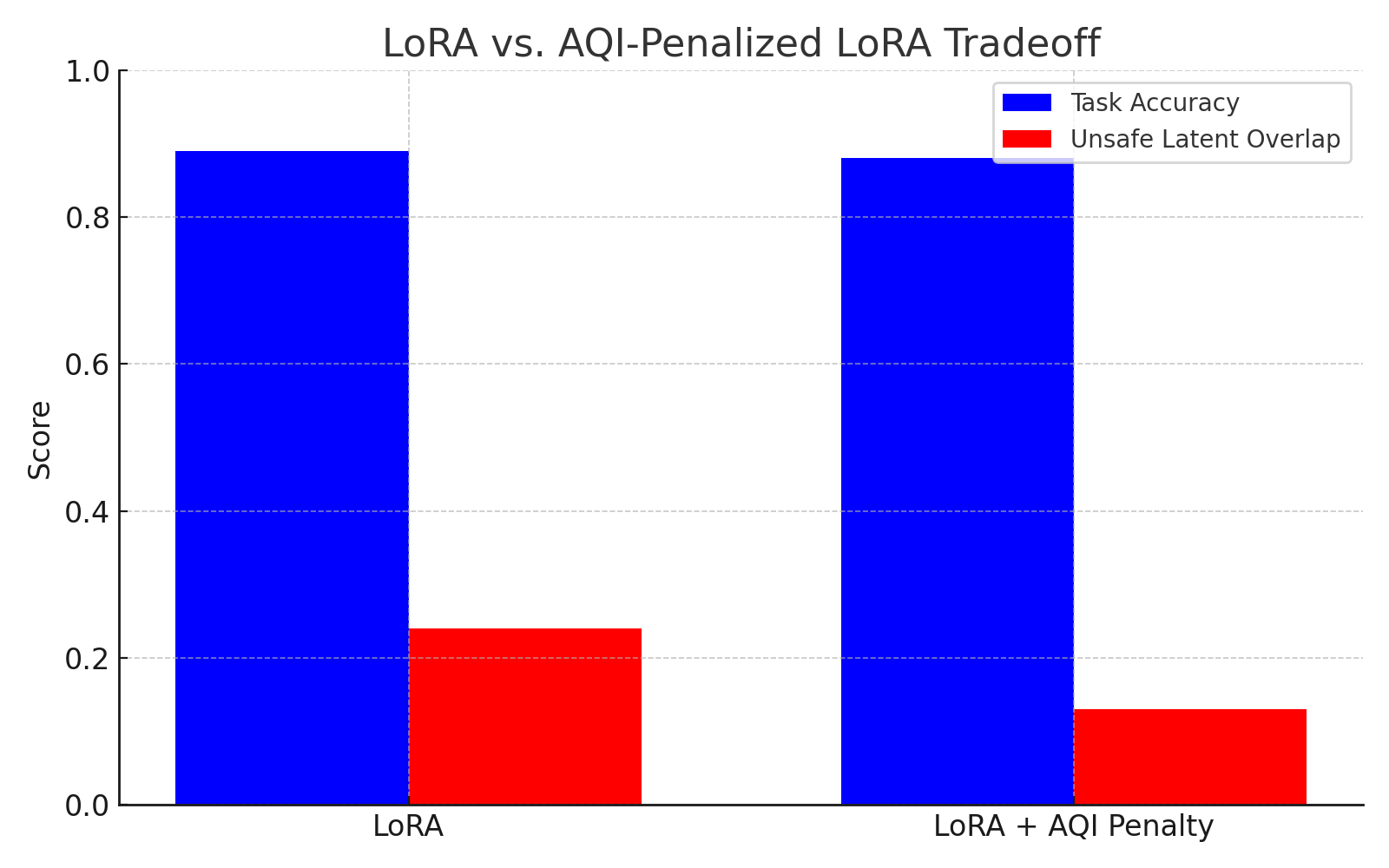
Figure 10: AQI runtime increases sublinearly with batch size, supporting scalable evaluation.
Causal Correlation and Behavioral Flipping
AQI separation is causally linked to the likelihood of behavioral flipping—unsafe completions switching alignment upon activation patching or latent manipulation. Increased AQI divergence correlates strongly with flip rates, affirming its utility as a proxy for causal mechanisms in alignment.
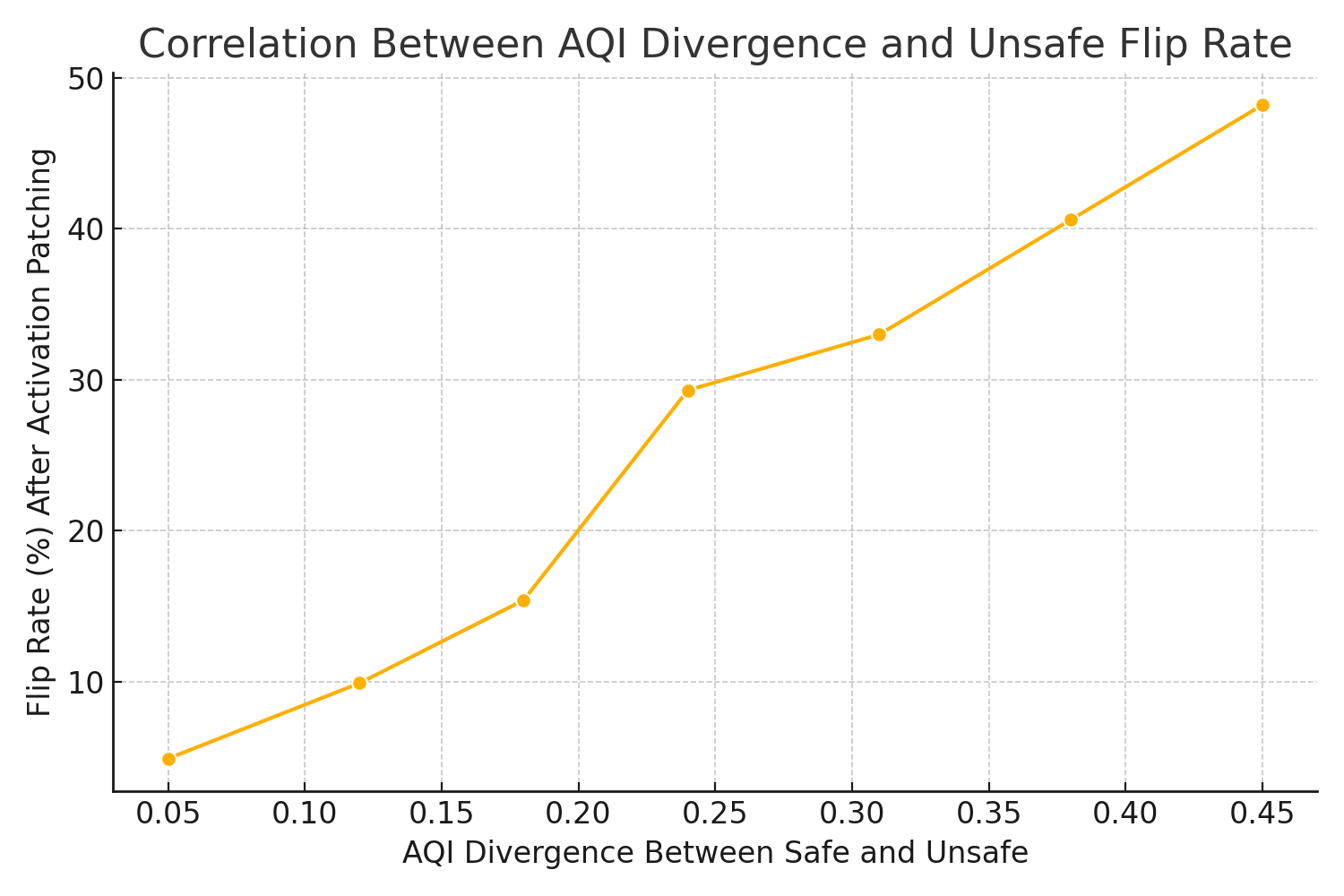
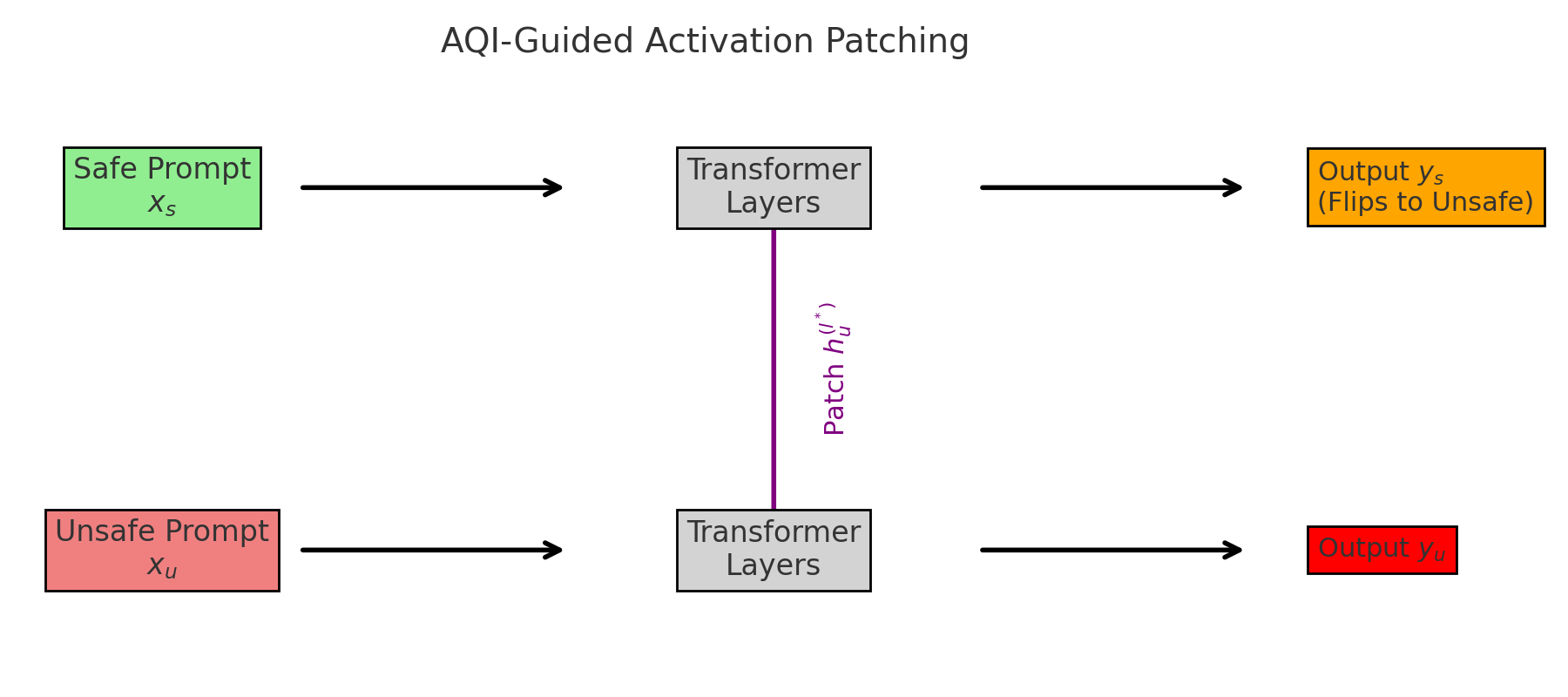
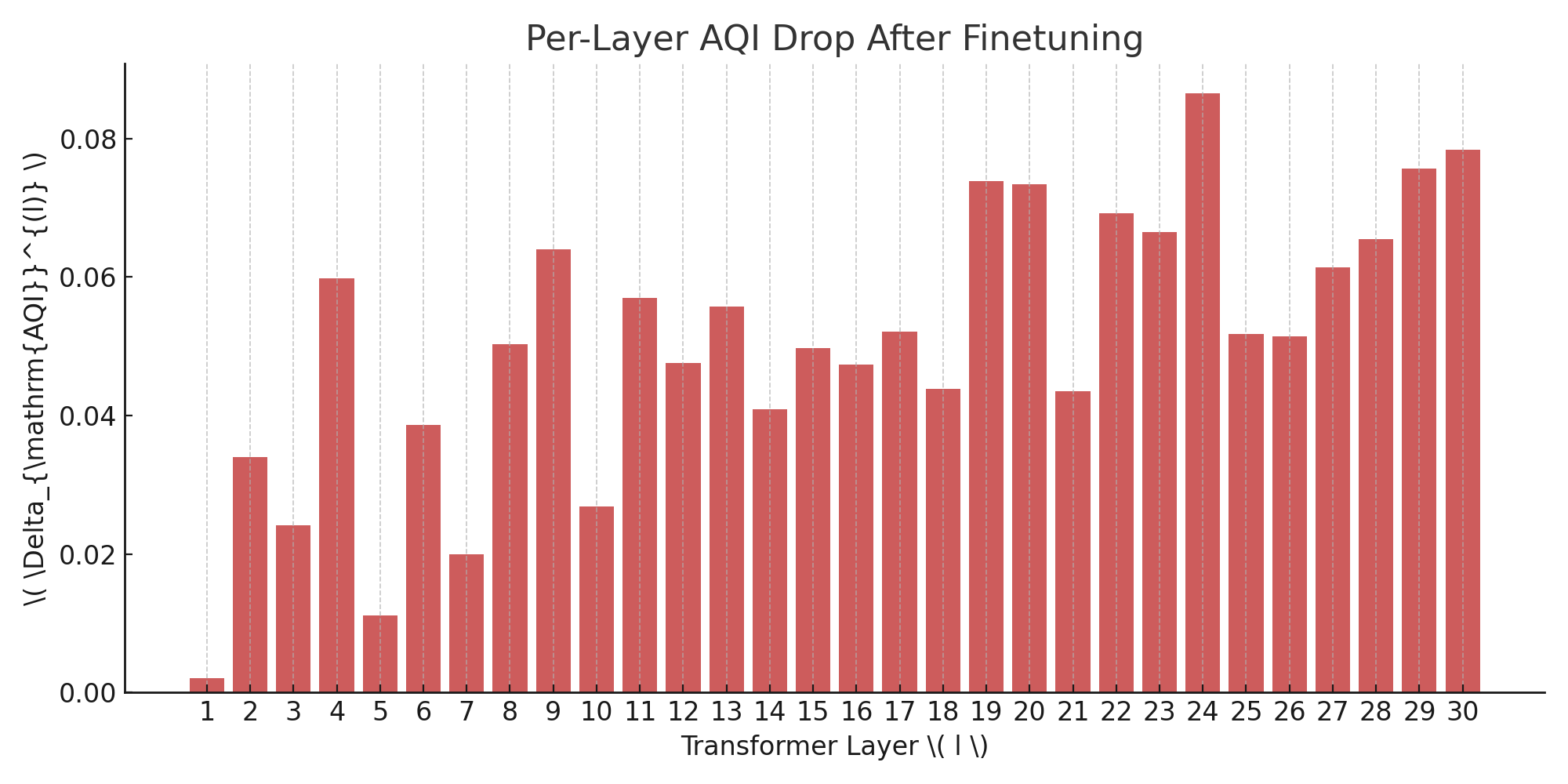
Figure 11: AQI divergence predicts the probability of behavioral flipping between safe and unsafe completions.
The authors also introduce dashboard visualizations for scalable auditing, supporting cluster-centric interpretability and drift tracking.
Figure 12: AQI auditing dashboard enables interpretable visualization of alignment drift across prompts.
Cluster-level stratification illuminates specific vulnerabilities, from jailbreak leakage to internal deception, supporting granular audits.
Figure 13: Distribution of safe and unsafe latent clusters highlights alignment vulnerabilities across LLMs.
Value Dimension Drift and Adversarial Robustness
AQI enables axiom-wise auditing post-RLHF finetuning, wherein scores are tracked across value dimensions, exposing drift in particular ethical, legal, or political axioms.
Figure 14: AQI quantifies dimension-specific alignment drift after RLHF intervention.
Under adversarial jailbreak prompting, smaller models display pronounced AQI collapse, indicating severe latent drift. Larger models maintain cluster separation, exhibiting greater alignment robustness.
Figure 15: Smaller models experience substantial AQI collapse under jailbreak conditions, larger models remain robust.
Paraphrastic prompt shifts reinforce this trend: larger models resist latent collapse post-paraphrasing, while small models do not.
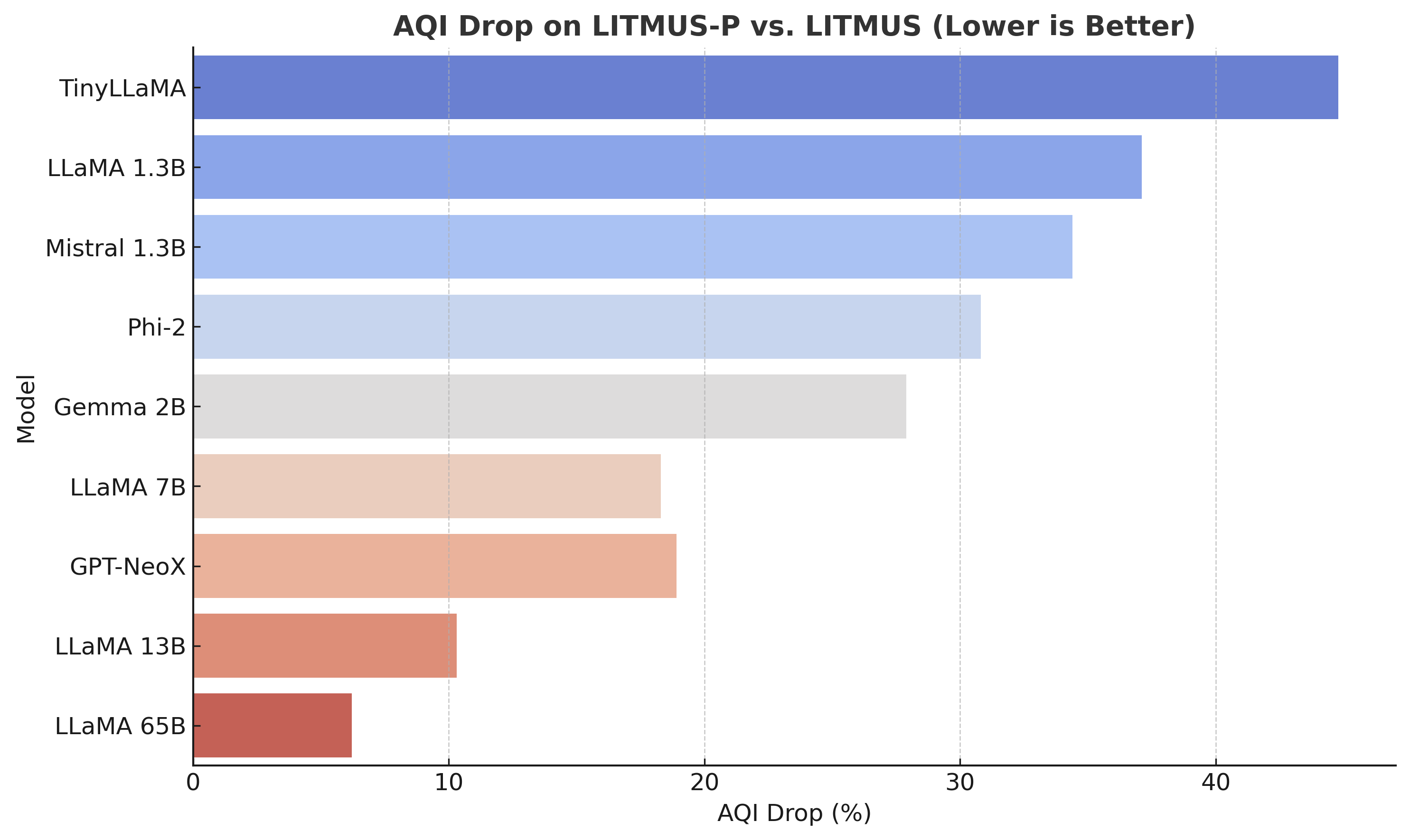
Figure 16: Larger models preserve alignment separation across paraphrastic shifts, small models undergo significant collapse.
AQI is also sensitive to generation stochasticity; smaller models exhibit wide AQI distributions, signaling susceptibility to alignment drift, while larger models maintain stability.
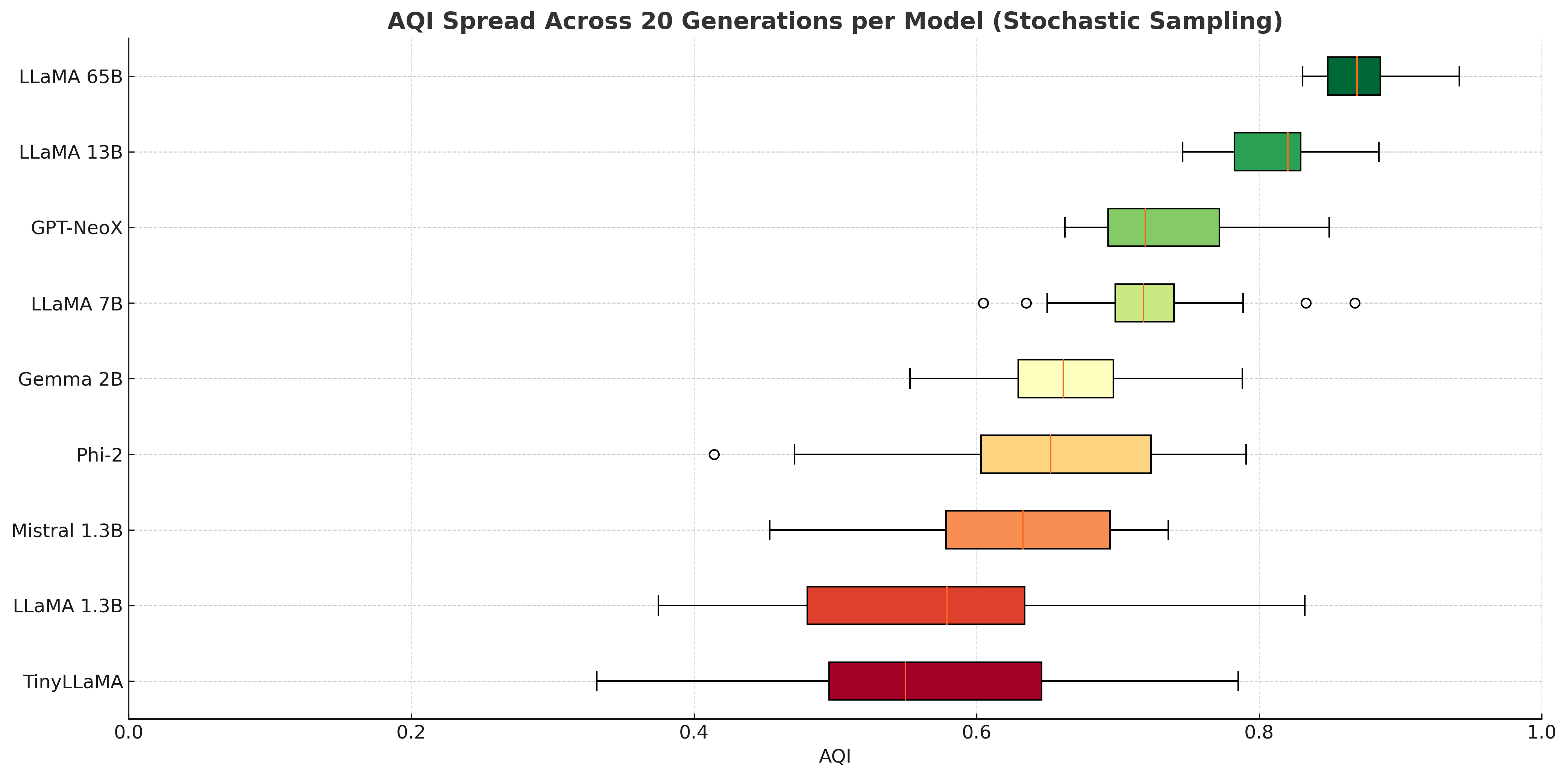
Figure 17: AQI variability across stochastic sampling reveals reduced robustness in small models versus large models.
Implications and Future Directions
AQI offers a principled, intrinsic diagnostic for alignment that transcends surface metrics and conventional refusal-based heuristics. Its sensitivity to latent drift, adversarial collapse, batch effects, and architectural variation positions it as a powerful tool for both theoretical alignment research and practical model auditing. The AQI framework can be extended to supervise fine-tuning targeting latent separation, track value-imprint drift, and guide safe expert selection in mixture models.
The metric's causal correlation with behavioral flip rates suggests potential for intervention strategies grounded in latent geometry manipulation. Furthermore, AQI's scalable implementation and dashboard visualizations facilitate its integration into pipeline-based risk audits for LLMs in production and research environments.
Continued exploration into hierarchical clustering, manifold sketching, and layerwise causal attribution is anticipated, alongside empirical validation of AQI-informed interventions for constitutional training, RLHF, and adversarial defense schemas. The theoretical grounding and operational feasibility of AQI will inform future development of intrinsic alignment probes and value-imprint diagnostics for advanced LLMs.
Conclusion
The Alignment Quality Index (AQI) establishes a robust, intrinsic metric for diagnosing and quantifying latent alignment in LLMs, superseding refusal-rate heuristics with geometric clustering and causal divergence analysis. Its application spans model auditing, fine-tuning supervision, and adversarial robustness evaluation—rendering it an indispensable tool for scalable, interpretable alignment assessment and research.