- The paper introduces DicFace, which reformulates discrete codebook representations as Dirichlet-distributed continuous variables to enable smooth temporal transitions.
- It integrates a spatio-temporal Transformer and Laplacian-constrained loss, yielding significant improvements in PSNR and LPIPS metrics.
- Experiments on benchmarks like VFHQ confirm DicFace’s effectiveness in mitigating flickers and enhancing spatial consistency in video face restoration.
DicFace: Dirichlet-Constrained Variational Codebook Learning for Temporally Coherent Video Face Restoration
Introduction
The paper "DicFace: Dirichlet-Constrained Variational Codebook Learning for Temporally Coherent Video Face Restoration" introduces a novel approach to video face restoration that emphasizes maintaining temporal consistency while enhancing fine facial details from degraded video inputs. This research extends the functionality of Vector-Quantized Variational Autoencoders (VQ-VAEs), pretrained on static high-quality images, to a video restoration setting using a variational latent space. The authors propose reformulating discrete codebook representations into Dirichlet-distributed continuous variables, empowering seamless transitions between frames and mitigating temporal flickers. This is achieved through a spatio-temporal Transformer architecture that models inter-frame dependencies and predicts latent distributions. This architecture is robustly regularized by a Laplacian-constrained reconstruction loss combined with perceptual LPIPS metrics enhancing quality and accuracy.
Framework Overview
The authors' framework efficiently processes a sequence of degraded video frames via three core components: a spatial feature extraction encoder, a spatio-temporal Transformer for dependency modeling, and a decoder that reconstructs high-quality frames from the composite mixture of learnable codebook entries.
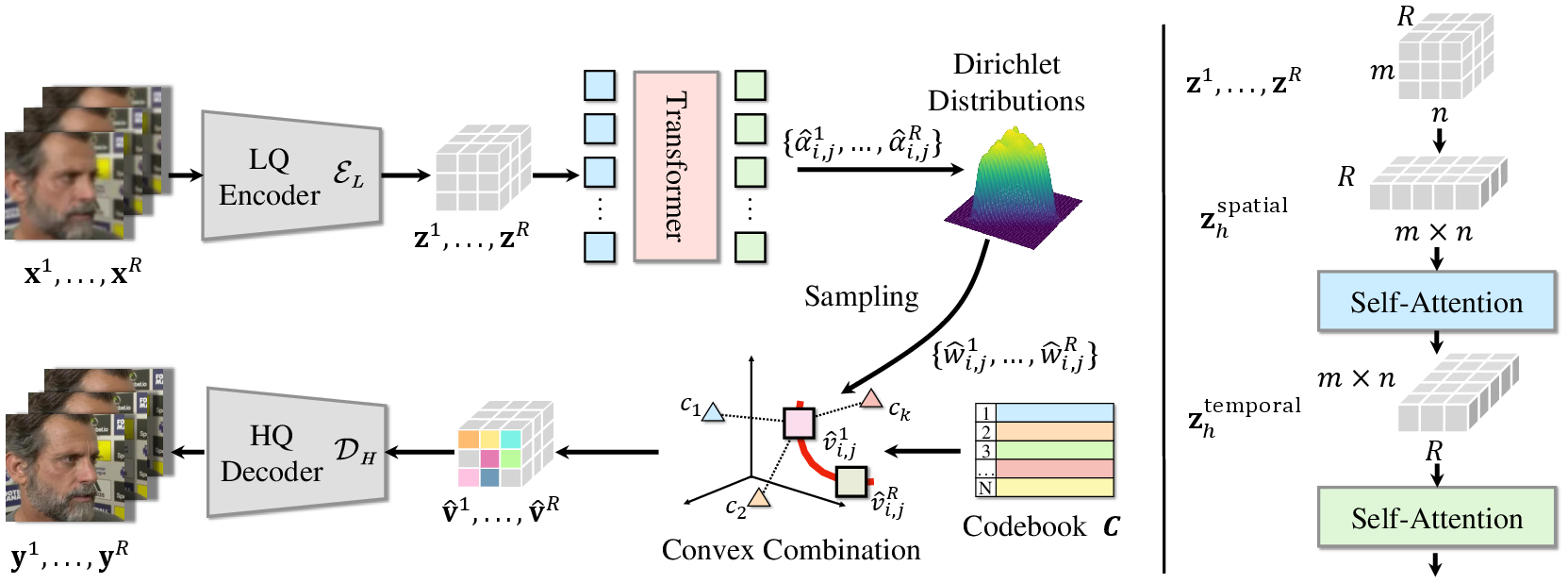
Figure 1: Overview of the DicFace framework with encoder, Transformer, and decoder components processing low-quality frames.
The Transformer architecture captures both spatial and temporal dependencies while predicting parameters for the Dirichlet distribution representing the mixture of latent codes, enhancing temporal coherence through smooth transitions over the Dirichlet manifold. The continuous formulation is regularized by an ELBO objective, balancing reconstruction fidelity with coherence.
Methodology
The authors elaborate on their innovative methodologies through various subsections, outlining the vector-quantized autoencoder framework that reconstructs images from latent feature maps, transitioning from discrete to continuous embeddings under a probabilistic paradigm enhanced by Dirichlet distribution properties.

Figure 2: Facial restoration model exhibits improved performance over state-of-the-art single-task solutions.
This reformulation allows for smoother transitions in video frame sequences, substantially reducing flickers associated with frame-to-frame variations by embedding discrete codebook representations within a variational framework.
Results and Comparisons
DicFace has been rigorously evaluated against contemporary benchmark datasets like VFHQ, proving its efficacy across tasks of blind face restoration, inpainting, and colorization. It exhibits significant performance improvements, showcased by higher PSNR and lower LPIPS scores, underscoring its ability to deliver high-quality restorations with superior temporal consistency.

Figure 3: Qualitative comparison with state-of-the-art methods, demonstrating superior detail recovery and temporal consistency across challenging conditions.
Temporary Stability and Invariance
A noteworthy advancement in this paper is the robust temporal stability achieved by DicFace, affirmed by enhanced TLME metrics and qualitative evaluations that illustrate its superior performance amid occlusions and dynamic poses.
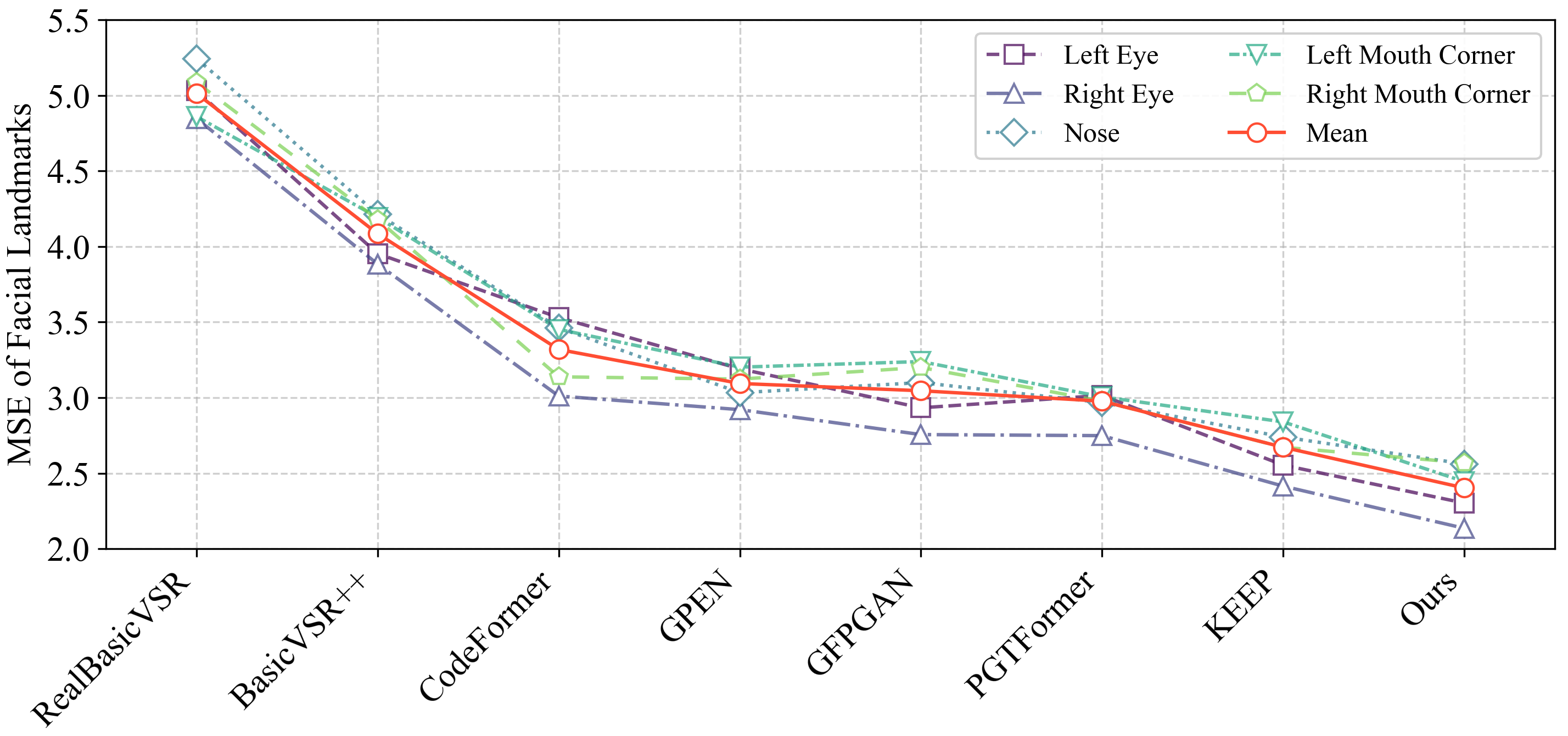
Figure 4: Comparison of temporal stability via MSE at facial landmarks, emphasizing improved consistency with DicFace.
Ablation Studies
Extensive ablation studies validate the efficacy of the central methodological innovations, emphasizing the importance of Dirichlet-based variational modeling in ensuring temporal coherence across video frames.
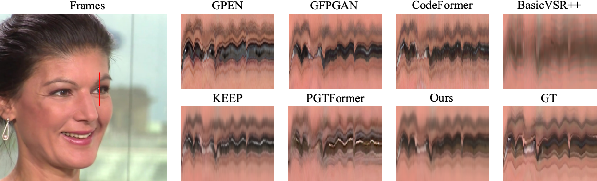
Figure 5: Mitigated temporal jitter in restoration, highlighting DicFace's enhancement of spatial consistency and temporal continuity.
Conclusion
The work establishes a formidable framework for leveraging pretrained image priors into video settings, addressing long-standing challenges of flicker artifact mitigation in video face restoration. By uniting discrete codebook principles with continuous video dynamics through a principled, probabilistic approach, DicFace sets a new benchmark for coherent and high-fidelity video enhancements, offering promising directions for further research in generative video models.