- The paper's main contribution is integrating supervised fine-tuning with reinforcement learning to enhance reasoning in math and coding tasks.
- The methodology leverages increased prompt diversity and temperature-tuned RL training to improve long chain-of-thought performance.
- Empirical results, including improved Pass@K metrics, validate the robust balance between exploration and exploitation in the model.
AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy
This essay explores the comprehensive approach employed in the development of the AceReason-Nemotron 1.1 model, which synergistically integrates Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to enhance the reasoning capabilities of LLMs in math and code domains.
Introduction to SFT and RL Synergy
The paper explores the dual strategies of SFT and RL to build robust reasoning models. Starting with SFT, the data is scaled by increasing both the number of unique prompts and the responses per prompt. This effort significantly amplifies the model's reasoning abilities, particularly in long chain-of-thought (CoT) scenarios, leading to consistent performance gains across several epochs of training.
For the RL aspect, the research investigates various approaches to integrate SFT models and fine-tune the synergy between exploration and exploitation, crucially determined by the sampling temperature. This strategic integration results in AceReason-Nemotron 1.1 achieving superior performance on established benchmarks.
Supervised Fine-Tuning Strategy
The SFT strategy involves curating a diverse dataset from high-quality sources for both math and code. As shown in the response length distributions (Figure 1), the datasets are carefully deduplicated and balanced across difficulty levels to prevent overfitting and enhance generalization.
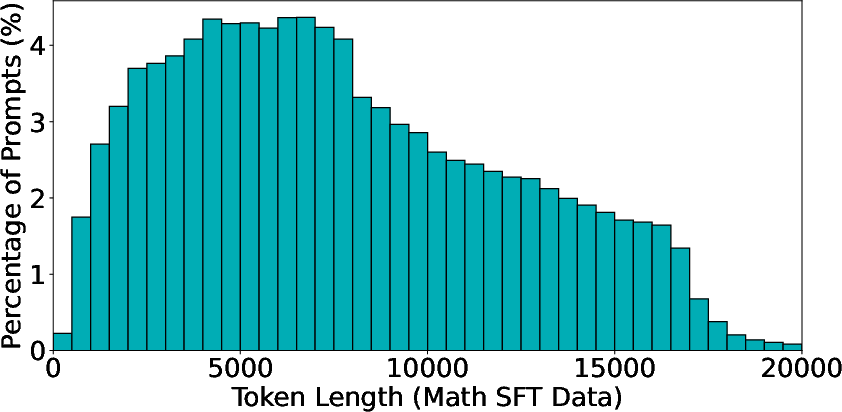
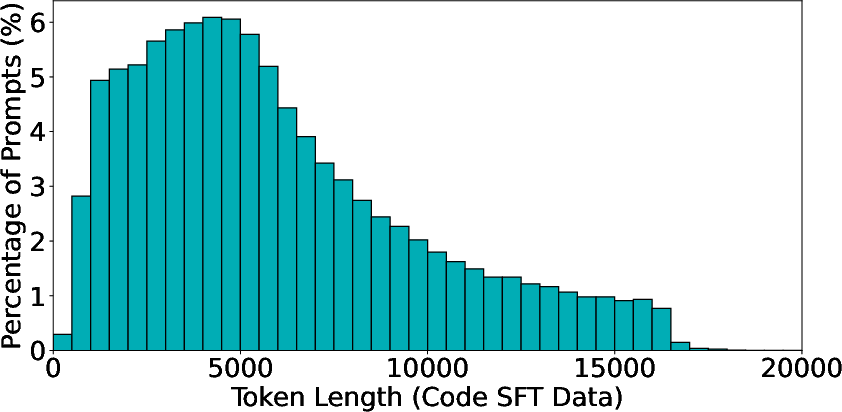
Figure 1: Response token length distributions for the math SFT dataset (left) and the code SFT dataset (right).
The scaling efficiency is depicted in Figure 2, which demonstrates substantial performance improvements on core benchmarks, achieved primarily by increasing the number of unique prompts and enhancing the responses per prompt.
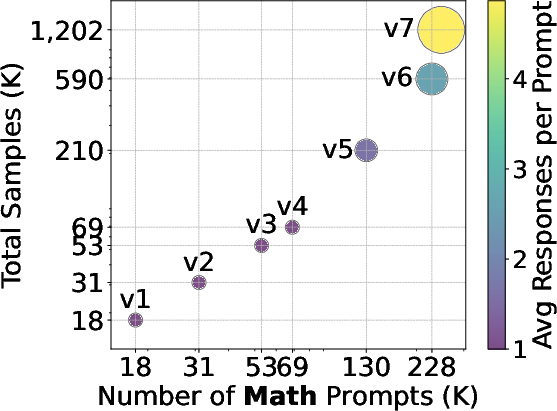
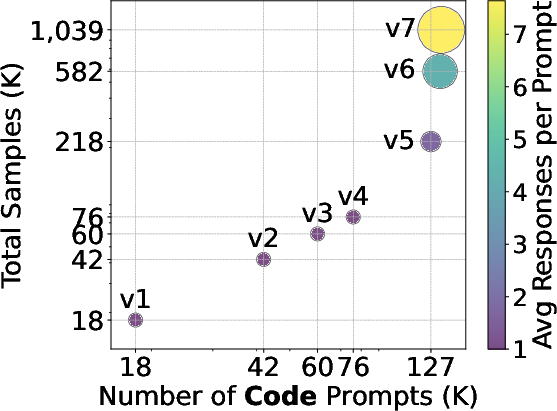
Figure 2: Log-scaled data statistics for the number of math and code prompts and the average number of responses per prompt.
The data scaling analysis concludes that enhancing prompt diversity yields larger performance gains than merely adding more responses per prompt. This is evidenced in Figure 3, where accuracies on various benchmarks improve as the dataset scales.
Reinforcement Learning Methodology
The RL strategy employs a stage-wise approach, depicted in Figure 4, training the model progressively with increasing response lengths. The policy LLM's temperature settings significantly impact RL training dynamics, as shown in Figure 5. Maintaining the temperature-adjusted entropy around 0.3 is essential for balancing exploration and exploitation effectively.
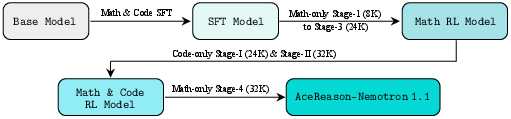
Figure 4: Training Pipeline of AceReason-Nemotron 1.1.
The research further investigates the necessity and effectiveness of initiating RL from strong SFT models. Figure 6 highlights that while the initial performance of SFT models varies significantly, these differences diminish across RL training stages.
Evaluation and Benchmarking Outcomes
AceReason-Nemotron 1.1's performance on benchmarks, as illustrated in Figure 7, surpasses other models based on similar architectures, showcasing advancements not just in math reasoning but also in coding capabilities, as shown in Figures 11 and 15.
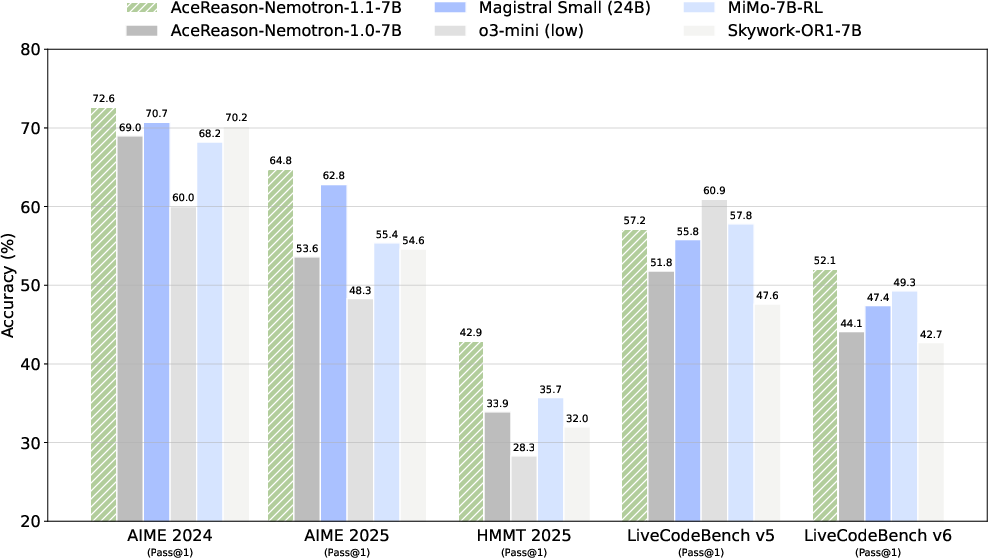
Figure 7: Benchmark accuracy of AceReason-Nemotron-1.1-7B on various tasks.
Pass@K metrics, seen in Figure 8, confirm that the RL-enhanced model consistently outperforms its SFT model across increasing values of K, underlining its robustness.
Conclusion
AceReason-Nemotron 1.1 exemplifies the efficacy of integrating SFT and RL to create high-performing reasoning models. By methodically combining data scaling in SFT with the strategic application of RL, this research lays groundwork for developing models that balance depth of reasoning with computational efficiency. Future research could explore extending these methods to more varied domains and model sizes.

