- The paper introduces Optimal Spiking Brain Compression (OSBC), a framework adapting one-shot pruning and quantization for spiking neural networks using membrane potential as a loss function.
- OSBC achieves up to 97% sparsity with a minor 1.74% accuracy drop on neuromorphic datasets like DVS128-Gesture, outperforming traditional methods.
- The module-wise strategy and one-shot approach significantly enhance energy efficiency, making OSBC highly applicable for edge computing and robotics.
Optimal Spiking Brain Compression: Improving One-Shot Post-Training Pruning and Quantization for Spiking Neural Networks
Introduction
The paper addresses the optimization of Spiking Neural Networks (SNNs) using a new framework called Optimal Spiking Brain Compression (OSBC). With the growing demand for energy-efficient SNNs suitable for neuromorphic hardware, the OSBC framework proposes a one-shot post-training approach to pruning and quantization. This approach is designed to improve efficiency without the extensive computational cost typically associated with iterative compression methods.
Framework Overview
OSBC adapts the Optimal Brain Compression (OBC) approach for Artificial Neural Networks (ANNs) to the domain of SNNs. Unlike OBC, which focuses on minimizing the loss on neuron input current, OSBC targets the spiking neuron membrane potential. This shift is critical for improving the fidelity of SNN compression, particularly in applications using neuromorphic datasets such as N-MNIST, CIFAR10-DVS, and DVS128-Gesture. The proposed method achieves up to 97% sparsity in pruning, maintaining a minimal accuracy loss.
Membrane Potential as an Objective Function
A core innovation in OSBC is using the surrogate membrane potential as a loss function. This method respects the unique properties of SNNs, where neuron spiking is influenced by accumulated membrane potential rather than just input current. The paper demonstrates that this approach has a higher correlation with output spike train fidelity than previous methods.
Visual Representation: Matrix Visualization
The correlation between the objective function's effectiveness and output spike train fidelity is depicted through a series of figures.
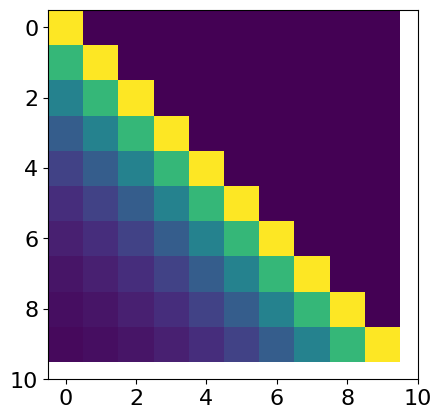
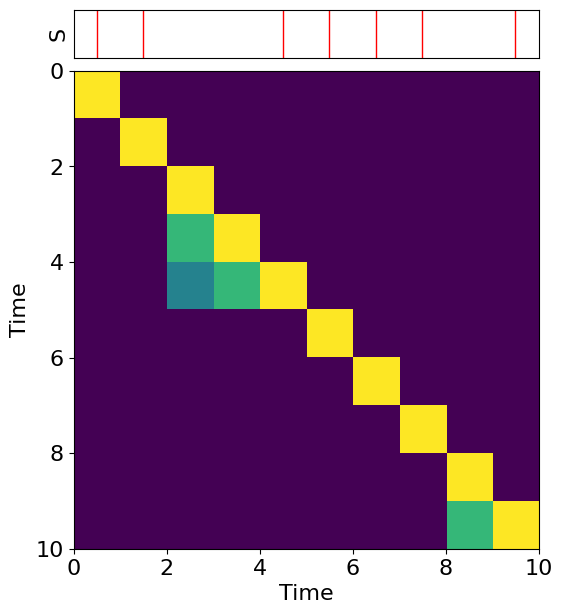
Figure 1: M_j matrix visualization. S represents the spike train with spikes at red lines, the bottom square image is the visualization of the corresponding matrix M_j with dtime=10,τm=3.
Module-Wise Compression
OSBC introduces a module-wise compression strategy, where each module includes linear or convolutional layers followed by a LIF neuron layer and associated operations. This method streamlines the process and reduces redundancy while preserving neuron dependencies.
Experimental Evaluation
Experiments confirm OSBC's superior performance over baseline methods such as naive Magnitude-Based Pruning (MBP) and ExactOBS. The frameworks were tested across multiple neuromorphic datasets, achieving high sparsity levels with minor accuracy losses.
Comparison of Pruning Methods
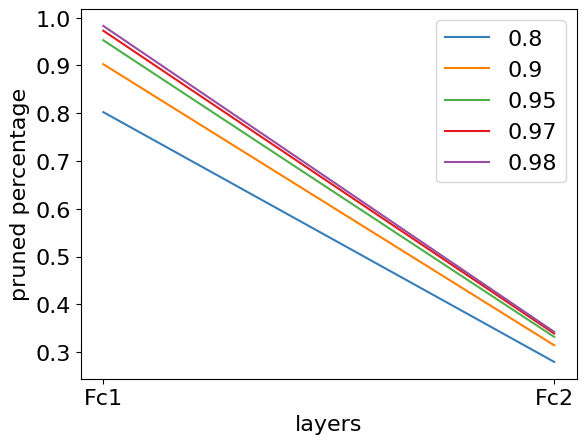
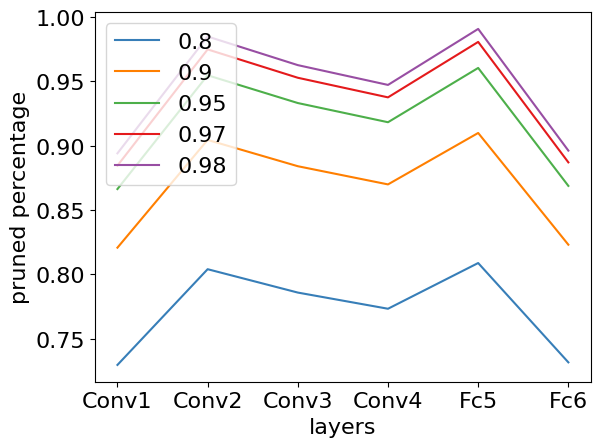
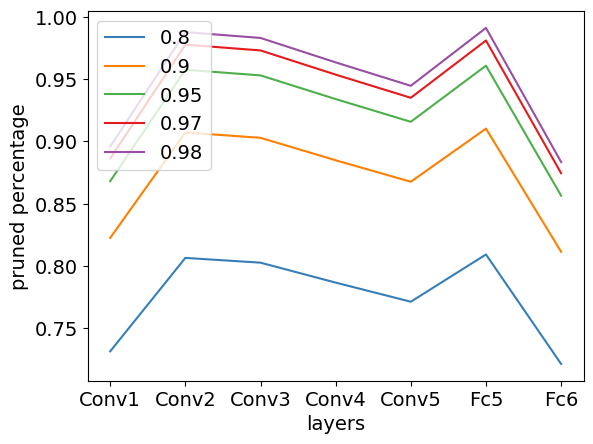
Figure 2: Per-layer pruning percentage breakdown at 80\%, 90\%, 95\%, 97\%, and 98\% sparsity for three commonly used neuromorphic datasets: a) N-MNIST, b) CIFAR10-DVS, c) DVS128-Gesture.
In pruning, OSBC retained high accuracy at 97% sparsity for datasets like DVS128-Gesture, demonstrating a 1.74% accuracy drop, outperforming existing methods. Quantization results were also favorable, especially at lower bit-widths, where OSBC outshone approaches like GPTQ.
Implications and Future Directions
The advancements in OSBC are promising for the deployment of SNNs in real-time environments such as edge computing and robotics, where power efficiency is critical. Future work could explore temporal compression and enhanced quantization grids, which would further optimize SNN performance.
Conclusion
The OSBC framework presents a streamlined, efficient approach for one-shot pruning and quantization of SNNs. It exhibits notable improvements over state-of-the-art methods, particularly in maintaining accuracy at high sparsity levels. This research paves the way for the scalable deployment of SNNs in energy-constrained scenarios, expanding their applicability and practicality.