- The paper introduces a two-stage predictive framework leveraging Zipf-based intrinsic metrics to assess tokenizer impact on multilingual and English tasks.
- It demonstrates that tokenizer choice significantly affects multilingual performance, reducing computational costs by up to 85% compared to full-scale evaluations.
- It details a rigorous experimental setup comparing six tokenizers across various language model sizes, highlighting the importance of aligning token distributions with natural language patterns.
Beyond Text Compression: Evaluating Tokenizers Across Scales
Introduction to Tokenizer Impact
In the field of NLP, tokenizers play a crucial role in transforming text into a form that machine learning models can interpret, typically through the segmentation of text into subword units. The design and evaluation of tokenizers are paramount, as they can significantly influence the performance efficiency and downstream application success of LLMs. Updating tokenizers post-training can be complex, necessitating a thorough understanding of their impact before large-scale training commences. This paper explores these challenges by evaluating the impact of tokenizer choice beyond mere text compression, particularly in multilingual settings.
Evaluation Framework and Experimental Setup
The authors propose a framework leveraging smaller LLMs to predict the downstream effects of tokenizer choices on larger models. This approach significantly reduces computational costs—by as much as 85%. The evaluations cover English and multilingual tasks, revealing that tokenizer selection has minor effects in monolingual English tasks but marked performance differences in multilingual contexts.
Model and Tokenizer Selection
Six tokenizers from various established models, such as Llama and GPT-2, are evaluated under consistent architecture configurations of 350-million and 2.7-billion parameters. This setup allows the authors to strictly isolate the effects attributable to tokenization. Models are pretrained using a dataset subset focusing on the practical application of English-centric and multilingual tokenizers.
Intrinsic and Extrinsic Evaluations
The study includes developing four intrinsic metrics based on Zipf's law to assess how token distributions align with natural language statistics. These metrics—cardinality, rank-frequency AUC, slope, and deviation from a power-law distribution—were found to correlate more robustly with downstream performance than traditional text compression measures in multilingual settings.
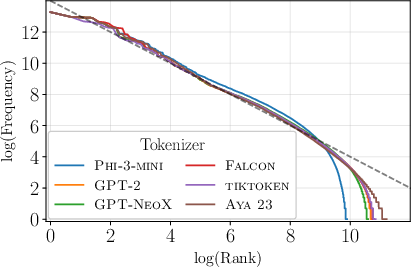
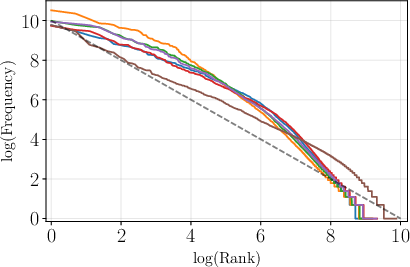
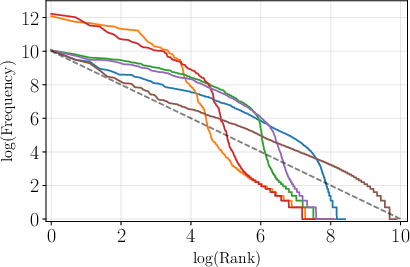
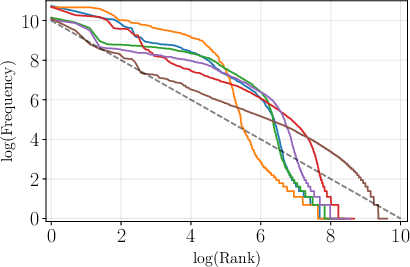
Figure 1: Token frequency plotted against frequency rank in log-log scale for English, showcasing alignment with Zipfian distribution.
Results on Diverse Task Sets
Evaluation across multiple-choice benchmarks, summarization, and machine translation tasks illustrates that while tokenizers show negligible impact on English-centric tasks, their choice decisively affects multilingual scenarios, especially machine translation tasks. Notably, a 350M-parameter model using a carefully chosen multilingual tokenizer outperformed much larger models using English-centric tokenizers in several language translation tasks.
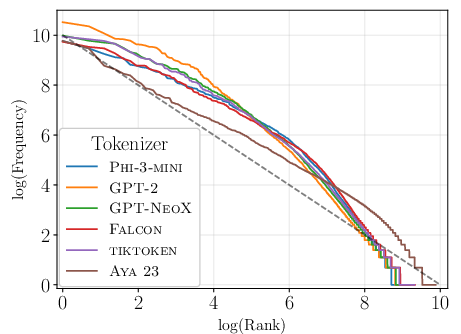
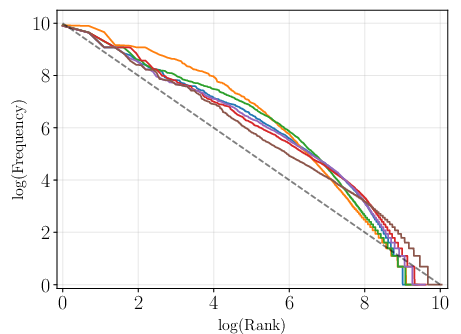
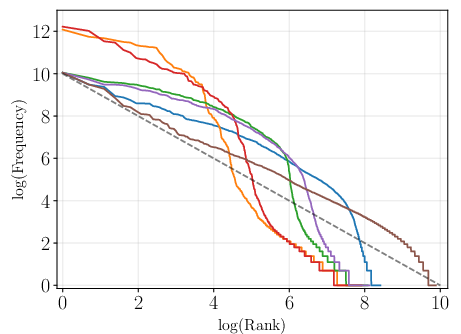
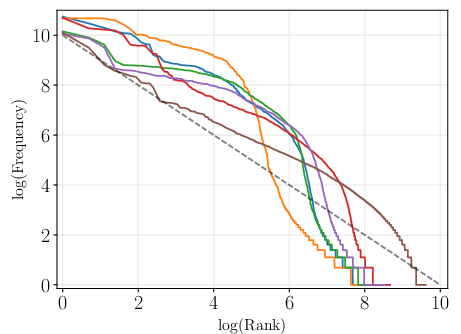
Figure 2: Token frequency plotted against frequency rank for a range of languages including Czech, illustrating the variability in distribution alignment with Zipf's law.
Predictive Framework for Tokenizer Selection
The authors propose a two-stage predictive framework utilizing the identified intrinsic metrics. This model efficiently ranks tokenizers based on their likely performance, thereby optimizing the selection process for specific NLP applications without the computational overhead of full-scale model training.
Discussion on Practical Implications
The research provides a nuanced understanding that, beyond compression, multiple aspects of tokenization need careful consideration in multilingual applications. Proper alignment of token distributions with natural statistics ensures effective model learning. For practitioners, the framework offers a method to preemptively assess tokenizer suitability, potentially leading to improved performance and computational efficiency in future model development.
Conclusion
This paper delivers a systematic evaluation of tokenizers, advocating for a multifaceted approach beyond traditional text compression metrics. The findings underscore the importance of selecting tokenizers that produce token distributions closely mirroring natural language patterns, which is especially crucial in multilingual model applications. The proposed evaluative framework and metrics offer a significant contribution to developing more efficient and effective LLMs.