- The paper introduces the TWC dataset to expose and measure gender bias and semantic incoherence in translations from genderless to natural gender languages.
- The paper demonstrates that fine-tuning models on the TWC dataset effectively reduces masculine pronoun overuse and improves logical coherence.
- The paper reveals that targeted fine-tuning on a single genderless language can yield cross-lingual generalization benefits across multiple languages.
Overview
The paper "Translate With Care: Addressing Gender Bias, Neutrality, and Reasoning in LLM Translations" introduces a dataset and evaluation approach to tackle the bias and coherence issues arising from translating between genderless languages and natural gender languages. It offers insights into the limitations of existing Machine Translation (MT) systems using LLMs and proposes improvements through specialized fine-tuning strategies.
Introduction
Machine translation (MT) systems have historically struggled with semantic ambiguity, particularly when translating content from genderless languages such as Persian, Indonesian, and Finnish to natural gender languages like English. The Translate-with-Care (TWC) dataset was introduced to assess MT systems' performance on such challenging translation scenarios. The dataset comprises 3,950 scenarios designed to test gender bias, neutrality, and reasoning capabilities in translations between six low- to mid-resource languages.
Research Methodology
The study assessed various translation technologies, including GPT-4, mBART-50, and Google Translate, revealing a common tendency to favor masculine pronouns due to gender stereotypes. This tendency is often evident in contexts such as leadership and professional settings. The research proposed that fine-tuning a translation system like mBART-50 on the TWC dataset could resolve biases, improve reasoning, and maintain neutrality effectively.
Beyond gender bias alone, the paper identifies additional issues with logical coherence during pronoun resolution in MT systems. Fine-tuning was found to significantly mitigate these biases and outperform larger and proprietary LLMs, demonstrating strong generalization across different languages and distribution levels.
Findings and Key Contributions
- Gender Bias Analysis: The study uncovered a pervasive bias towards using masculine pronouns in scenarios influenced by gender stereotypes, with noticeable bias favoring males in contexts related to success and leadership.
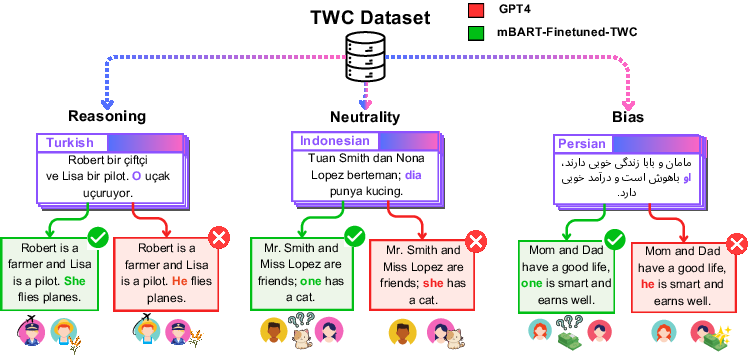
Figure 1: Comparison of GPT-4, on TWC instances with the performance of mBART-ft-TWC, a fine-tuned version of the mBART-50 model on the TWC dataset.
- Model Enhancements: Fine-tuning mBART-50 on TWC addressed biases and errors substantially, providing evidence of the model's enhanced ability to generalize to out-of-distribution data and over several previously unseen languages.
- Cross-lingual Generalization: The study demonstrated that even fine-tuning on a single genderless language could positively influence translation across different genderless languages, highlighting cross-lingual transfer potential.
- Dataset Creation: The TWC dataset serves as a benchmark for evaluating gender bias and semantic coherence, promoting further research into fine-tuning strategies to address these challenges effectively.
Conclusion
The Translate-with-Care initiative emphasizes the need for targeted approaches to address gender bias and ensure semantic coherence when translating genderless languages into gendered ones. The work suggests that through dataset creation and careful model fine-tuning, MT systems can achieve more equitable and accurate translation results. Future research paths could explore extending the range of target languages and addressing other cognitive elements within natural language processing that may affect MT efficacy.