- The paper introduces LPASS, which leverages linear probes to estimate compressed LLM performance for vulnerability detection before fine-tuning.
- It details a methodology using MLP-based linear probes across model layers to determine optimal pruning thresholds and predict precision metrics.
- Results on BERT and Gemma models demonstrate state-of-the-art performance, reducing training and inference times with minimal accuracy loss.
LPASS: Linear Probes as Stepping Stones for Vulnerability Detection Using Compressed LLMs
Introduction
The paper presents LPASS, an innovative approach that leverages Linear Probes (LPs) for estimating the performance of compressed LLMs in vulnerability detection tasks before fine-tuning. This approach aims to optimize model compression techniques effectively, such as quantization and layer pruning, and ensure these operations do not degrade the model's precision.
LPASS Overview
LPs are employed as a diagnostic tool to assess the capacity of LLMs to detect vulnerabilities before extensive computational resources are expended on fine-tuning. The process is depicted graphically in the provided LPASS overview (Figure 1). The key flows illustrated demonstrate different stages of LLM evaluation, contrasting baseline models with various compressed counterparts through techniques like quantization and layer pruning.
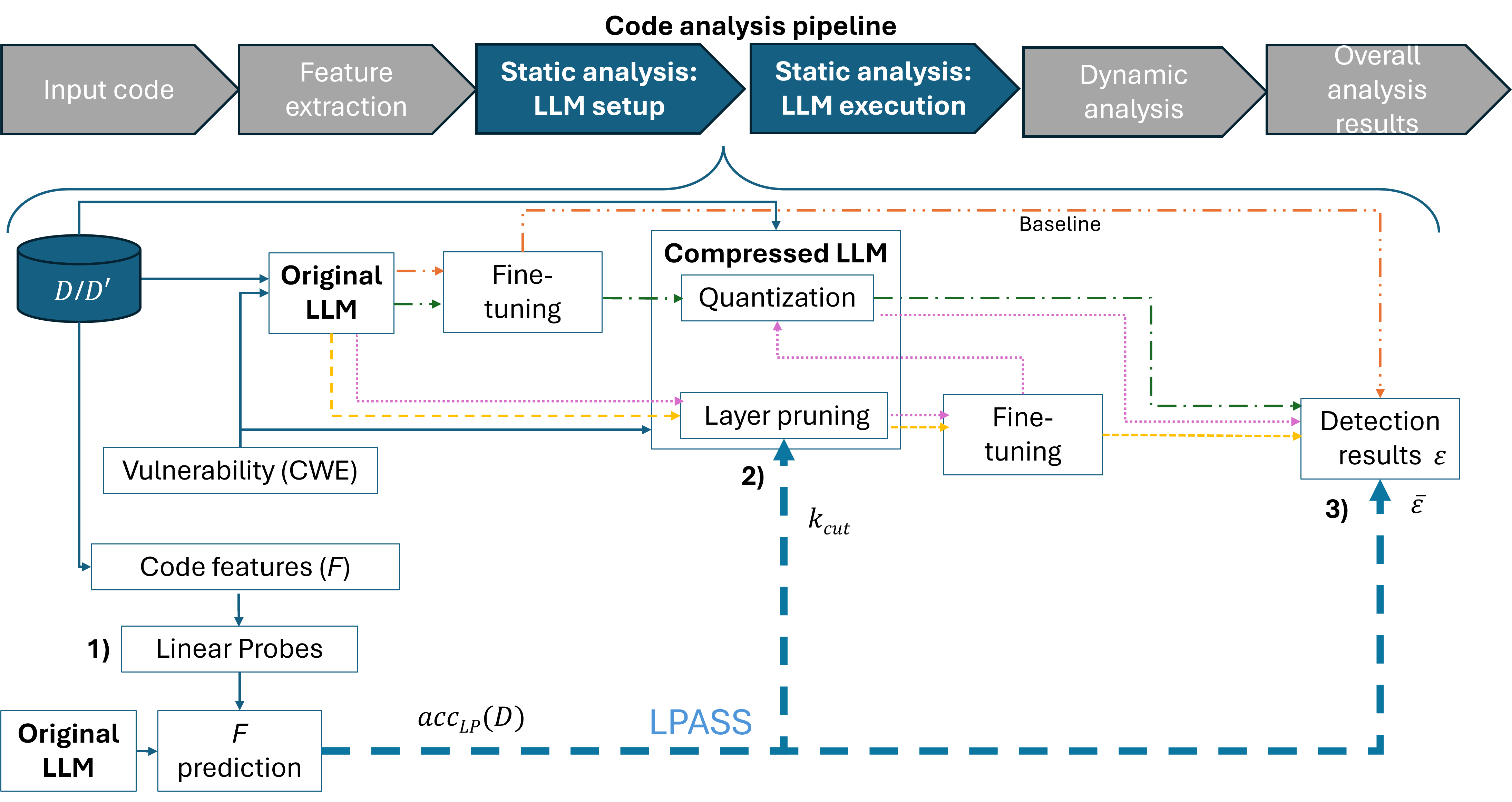
Figure 1: LPASS overview. Steps of LPASS are numbered and colored flows are used to assess the approach when using LLMs to detect vulnerabilities. The orange flow (dot-dot-dash) computes the baseline results, whereas the green (dot-dash), yellow (dashes) and pink (dots) flows refer to compressed LLMs, that is after applying quantization, layer pruning or both techniques at the same time, respectively.
Methodology
Linear Probes for Layer Pruning
LPASS implements LPs via Multi-Layer Perceptrons (MLPs) applied sequentially across layers of the LLMs, using intermediate activations to predict code features relevant to vulnerability detection, such as Cyclomatic Complexity (CC) and Halstead Difficulty (HD). The LPs' performance helps identify the optimal cut-off layer (k_{cut}) for pruning, effectively reducing the model size without significant loss in precision.
LPs also serve to preliminarily estimate the effectiveness of models post-compression and fine-tuning. The estimation leverages LP accuracy metrics as well as a residual factor, β, derived from prior assessments across datasets. This allows the prediction of precision and recall metrics with modest estimation errors, effectively guiding further training decisions.
Evaluation and Results
The LPASS framework was implemented on BERT and Gemma models, tested across datasets including DiverseVul, Big-Vul, and PrimeVul. The models aimed to detect 12 high-risk vulnerabilities, achieving state-of-the-art results. Notably, LP-based file size reductions and acceleration in inference speeds were demonstrated, with BERT showing consistent reductions in training and inference times alongside a substantial decrease in computational resources required for model deployment.
Discussion
LPASS highlights potential advancements in applying LPs to real-world applications beyond vulnerability detection. It showcases how LPs can provide insight into internal activations for a range of model configurations, suggesting a framework for lighter, faster, and equally robust models tailored specifically to complex tasks such as vulnerability detection. The results point to broader implications for accelerating LLM those could not only apply to other tasks beyond cybersecurity but extend to varied domains where similar efficiency is sought.
Conclusion
This work introduces a practical and efficacious method for utilizing LPs to support LLM compression through informed pruning and quantization choices. LPASS demonstrates that these insights can be harnessed to preserve and even enhance model accuracy post-compression, offering a vital tool for developing efficient AI systems. Future investigations could consider broader applications across other domains and LLM architectures, potentially expanding the utility of linear probes within diverse AI workloads.

