- The paper introduces NFT as a novel approach that integrates negative feedback within supervised learning to enhance math reasoning.
- The paper demonstrates that NFT, using both positive and negative data, attains performance comparable to state-of-the-art RL techniques in experimental evaluations.
- The paper highlights practical benefits like efficient federated training and balanced entropy management, paving the way for broader applications in self-reflective AI training.
Bridging Supervised Learning and Reinforcement Learning in Math Reasoning
Introduction
The paper "Bridging Supervised Learning and Reinforcement Learning in Math Reasoning" introduces Negative-aware Fine-Tuning (NFT), an approach that challenges the conventional notion that self-improvement in math reasoning for LLMs is exclusive to Reinforcement Learning (RL). The method integrates RL's self-reflective learning abilities into the Supervised Learning (SL) paradigm by enabling LLMs to learn from their generation mistakes without external supervision.
Methodology
NFT leverages self-generated negative answers by constructing an implicit negative policy model. This model allows the positive LLM, which is to be optimized, to process negative feedback alongside positive data. The implicit policy is parametrized identically to the positive policy, promoting optimization across all generated data.
The method involves:
- Data Collection: Generating answers and classifying them into positive or negative based on correctness.
- Implicit Policy Construction: Using both positive and negative data within a likelihood maximization framework, optimizing the implicit negative policy to influence the positive LLM directly.
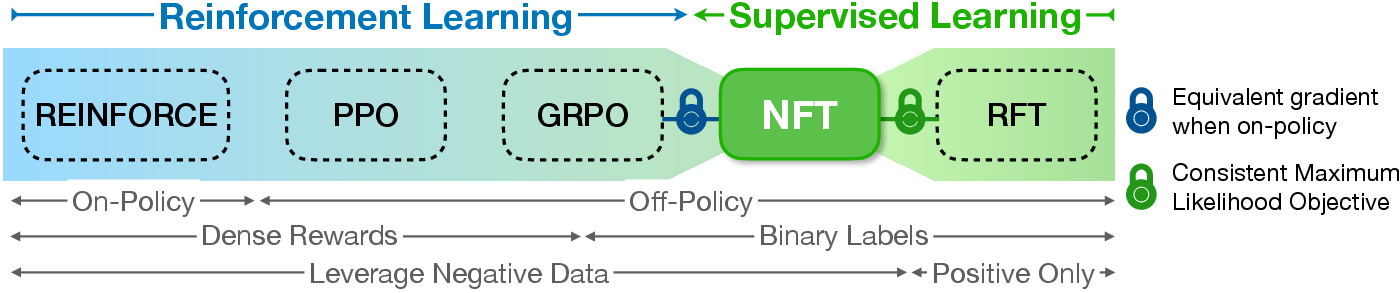
Figure 1: Spectrum of online algorithms for LLM fine-tuning with negative-aware supervision bridging SL and RL methods.
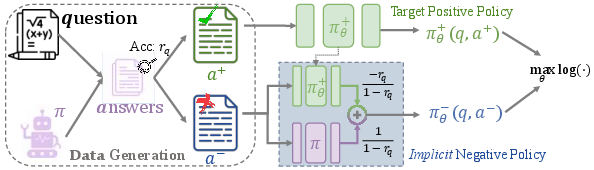
Figure 2: NFT algorithm illustration showing the usage of both positive and negative data for implicit policy modeling.
Theoretical Foundations
The authors establish a theoretical connection between NFT and Gradient Reinforcement Policy Optimization (GRPO). Despite NFT originating from SL foundations and GRPO from RL, they demonstrate equivalence under strict on-policy conditions, highlighting that NFT naturally embeds advantage normalization—a key GRPO feature.
The NFT optimizer respects Eq.~\ref{eq:main_relation}, leveraging both positive (r=1) and negative data (r=0) through a specially constructed loss function that maintains stability and ensures efficacy using techniques like token-level loss calculation and prompt weighting.
Experimental Evaluation
The study evaluates NFT on Qwen models (7B and 32B parameters) using the DAPO-Math-17k dataset and various math reasoning benchmarks, comparing against RL algorithms such as GRPO and Dr. GRPO. Key findings include:
- Performance: NFT outperforms traditional SL methods like RFT, achieving comparable results to GRPO and DAPO, which are state-of-the-art RL techniques for math reasoning tasks (Table 1).
- Benefits of Negative Data: NFT leverages negative data effectively, highlighting its role in achieving better exploration and mitigating entropy decrease, contrary to RFT, which fails to harness negative feedback.
(Table 1: NFT and algorithm performance comparison)
Practical Considerations
- Federated Training: NFT is efficient, requiring only a single model instance in memory, aligning well with large-scale distributed training environments.
- Entropy Management: By fostering conditions under which the model can learn from undesired states, NFT encourages a learning and exploration balance optimal for dataset diversity.
Conclusion
NFT illustrates that SL can be adapted for self-reflective training by integrating implicit policy learning, offering a competitive alternative to RL approaches in math-based tasks. This work not only bridges the conceptual gap between SL and RL but also shows SL methods can achieve performance parity with state-of-the-art RL algorithms without losing their inherent simplicity and efficiency.
Future Work: The results encourage exploration into integrating NFT-like SL adaptations in other domains requiring verifiable feedback, considering the broader implications for general AI systems capable of self-improvement using minimal supervision.