- The paper presents SGFNet, a network that fuses high-frequency RGB and thermal features using spectral-aware modules to enhance semantic segmentation performance.
- It introduces spectral-aware feature enhancement and channel attention to capture modality-specific details and improve segmentation accuracy.
- Experiments on MFNet and PST900 demonstrate that SGFNet outperforms state-of-the-art methods with notable gains in mAcc and mIoU metrics.
Spectral-Aware Global Fusion Network for Semantic Segmentation
This paper introduces the Spectral-aware Global Fusion Network (SGFNet) for RGB-Thermal (RGB-T) semantic segmentation, addressing the challenge of effectively fusing multi-modal features from RGB and thermal images. The core idea is to leverage the spectral characteristics of these modalities, explicitly enhancing and fusing high-frequency components that capture modality-specific details. The authors demonstrate that SGFNet outperforms existing state-of-the-art methods on the MFNet and PST900 datasets.
Introduction and Motivation
Semantic segmentation is critical for autonomous systems to understand their environment. RGB data alone is often insufficient in challenging conditions, such as low illumination or occlusions. Integrating thermal data, which captures thermal radiation, enhances robustness. However, effectively fusing RGB and thermal features is challenging due to modality discrepancies. The paper addresses this challenge by analyzing the spectral perspective of multi-modal features.
The authors observe that RGB and thermal features share similarities in their low-frequency components, representing broad scene context. Conversely, high-frequency components, capturing detailed textures and edges, are unique to each modality. As shown in (Figure 1), the high-frequency components of each modality capture different aspects of the scene. The authors propose prioritizing the fusion of high-frequency components to improve segmentation accuracy.

Figure 1: Interpreting an image pair from a spectral perspective through high-pass filtering (HPF) of the image's Fourier spectrum, highlighting modality-specific details.
SGFNet Architecture
SGFNet is designed to enhance and integrate multi-modal features by explicitly modeling interactions between high-frequency, modality-specific features. The overall framework (Figure 2) consists of RGB and thermal encoders, a spectral-aware global fusion (SGF) module, and a deep supervision mechanism.
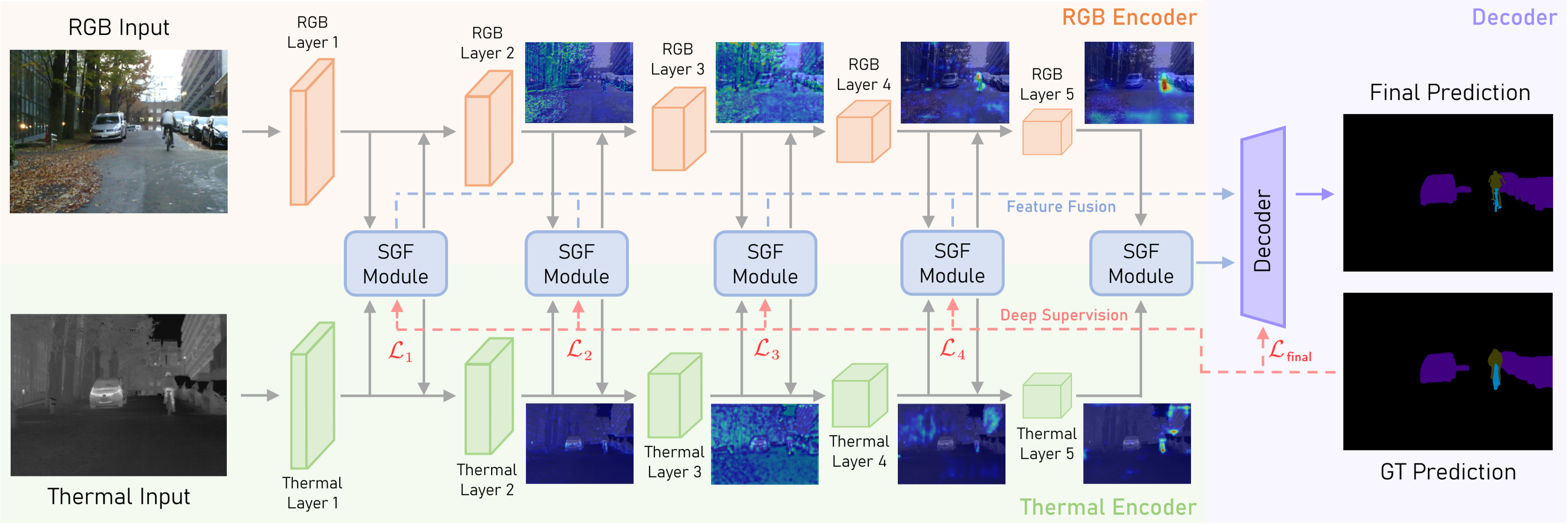
Figure 2: The overall framework of SGFNet, illustrating the multi-scale feature fusion and deep supervision mechanisms.
The SGF module (Figure 3) comprises three sequential parts: spectral-aware feature enhancement, spectral-aware channel attention, and global cross-modal attention. This module effectively fuses multi-scale features from both RGB and thermal encoders.
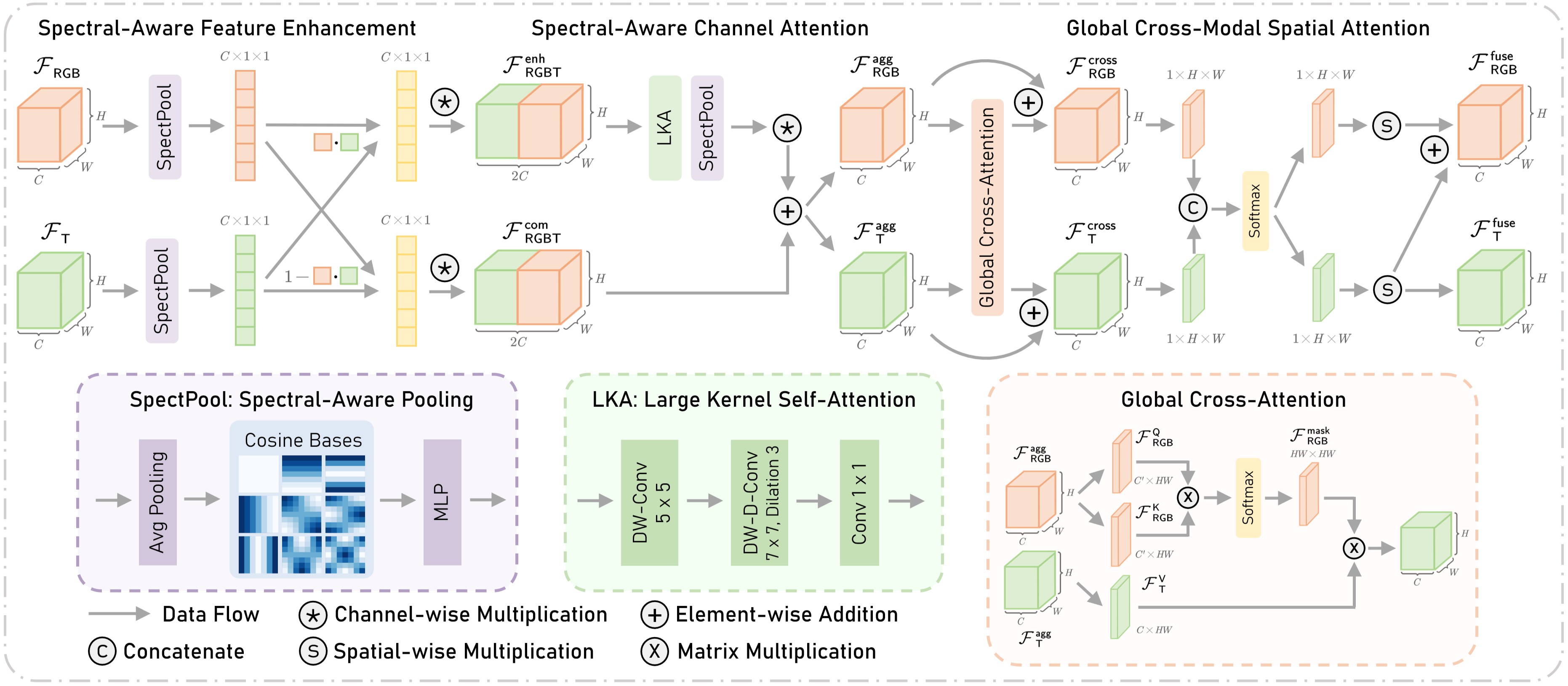
Figure 3: Architecture of the spectral-aware global fusion (SGF) module, detailing the spectral-aware feature enhancement, channel attention, and global cross-modal attention components.
Spectral-Aware Feature Enhancement
The spectral-aware feature enhancement module assigns weights to each channel of both modalities based on a spectral-aware channel-wise process. It captures high-frequency components using two-dimensional Discrete Cosine Transforms (DCT) and enriches channel representations. A set of cosine bases is defined as:
Bfh,fwhw=cos((h+21)πH′fh)⋅cos((w+21)πW′fw),
where H′ and W′ denote the size of the cosine basis, and fh and fw denote the frequency along two axes. The DCT is calculated by element-wise multiplication:
SRGB/Ti=h=0∑H′−1w=0∑W′−1FRGB/Ti,hwBfhi,fwihw,
where S denotes a scalar representation of a particular channel corresponding to a specific DCT frequency component. The channel activation score is derived by inputting these vectors into a multi-layer perceptron (MLP):
QRGB/T=fMLP([SRGB/T0,SRGB/T1,⋯,SRGB/TN−1]).
The features are jointly enhanced using the activation scores:
$\mathcal{F}_\mathsf{RGB/T}^{\mathsf{enh} = \mathcal{F}_\mathsf{RGB/T} \otimes\mathsf{Sigmoid}(\mathcal{Q}).$
A complementary branch retains features diminished by the enhancement:
$\mathcal{F}_\mathsf{RGB/T}^{\mathsf{com} = \mathcal{F}_\mathsf{RGB/T} \otimes \mathsf{Sigmoid}(1 - \mathcal{Q}).$
Spectral-Aware Channel Attention
This module explicitly considers interactions of enhanced multi-modal features by assigning different weights across all channels from both modalities. A large kernel attention (LKA) module extracts global self-attention. The process is formally written as:
$\mathcal{F}_\mathsf{RGBT}^{\mathsf{LKA} = f_{\mathsf{conv}^{1\times1}\!\left(f_{\mathsf{dwconv}^{7\times7, \,\mathsf{d}3}\!\left(f_{\mathsf{dwconv}^{5\times5}\!\left(\mathcal{F}_\mathsf{RGBT}^{\mathsf{enh}\right)\right)\right).$
The spectral-aware channel activation score QRGBTenh of each channel is calculated, and the resulting multi-modal features are obtained by weighting the original features with the channel-wise activation score:
$\mathcal{F}_\mathsf{RGBT}^{\mathsf{enh'} = \mathcal{F}_\mathsf{RGBT}^{\mathsf{enh} \otimes \mathsf{Sigmoid}(\mathcal{Q}_{\mathsf{RGBT}^\mathsf{enh}}).$
The cross-modal features in both the complementary and enhancement branches are then aggregated:
$\mathcal{F}_\mathsf{RGBT}^{\mathsf{agg} = \mathcal{F}_\mathsf{RGBT}^{\mathsf{enh'} + \mathcal{F}_\mathsf{RGBT}^{\mathsf{com}}.$
Global Cross-Modal Spatial Attention
This module merges cross-modal features for pixels at varied locations. It uses a global cross-attention mechanism to account for interactions between every pair of pixels, extending attention to encompass global spatial relationships. Three matrices are produced given the aggregated RGB/thermal feature map, functioning as query (Q), key (K), and value (V) components:
$\mathcal{F}_\mathsf{RGB/T}^{\mathsf{Q/K/V} = \mathsf{Reshape} \left(f_{\mathsf{conv}^{1\times1}\left(\mathcal{F}_\mathsf{RGB/T}^{\mathsf{agg}\right)\right).$
The enhanced thermal feature map is computed by cross-attention:
$\mathcal{F}_\mathsf{RGB}^\mathsf{mask} = \mathsf{Softmax}\left({\mathcal{F}_\mathsf{RGB}^\mathsf{Q}^{\top} \mathcal{F}_\mathsf{RGB}^\mathsf{K}\right), \
\mathcal{F}_\mathsf{T}^\mathsf{cross} = {\mathcal{F}_\mathsf{T}^\mathsf{V}^{\top} \mathcal{F}_\mathsf{RGB}^\mathsf{mask} + \mathcal{F}_\mathsf{T}^{\mathsf{agg}}.$
The global cross-modal spatial attention integrates the multi-modal features:
$\mathcal{F}_\mathsf{RGB/T}^{\mathsf{att} = \mathcal{F}_\mathsf{RGB/T}^{\mathsf{agg} \odot\mathsf{Softmax}\left(f_{\mathsf{conv}^{1\times1}\left(\mathcal{F}_\mathsf{RGB/T}^{\mathsf{cross}\right)\right),$
where ⊙ denotes element-wise spatial multiplication. The ultimate fused feature map is obtained by adding the thermal feature map to the RGB stream:
${
\mathcal{F}_\mathsf{RGB}^{\mathsf{fuse} = \mathcal{F}_\mathsf{RGB}^{\mathsf{att} + \mathcal{F}_\mathsf{T}^{\mathsf{att}, \, \mathcal{F}_\mathsf{T}^{\mathsf{fuse} = \mathcal{F}_\mathsf{T}^{\mathsf{att}}.$
Deep Supervision
The cascaded decoder integrates multi-level features and delivers the final prediction Mfinal. The loss function for evaluating this final prediction is:
$\mathcal{L}_{\mathsf{final} = \mathsf{Loss}\left(\mathcal{M}_{\mathsf{final}, \mathcal{M}_{\mathsf{GT}\right),$
where $\mathcal{M}_{\mathsf{GT}$ is the ground-truth segmentation map. An additional loss function supervises early-layer feature generation after the initial four layers:
$\mathcal{L}_i = \mathsf{Loss}\left(\mathcal{M}_{\mathsf{pred}^i, \mathcal{M}_{\mathsf{GT}\right), i\in \{1, 2, 3, 4\}.$
The total loss function is the sum of these individual loss components.
Experimental Results
The authors conducted experiments on the MFNet and PST900 datasets. The MFNet dataset contains 1,569 pairs of RGB and thermal images, while the PST900 dataset consists of 894 matched RGB-T image pairs. The evaluation metrics are mean accuracy (mAcc) and mean intersection over union (mIoU).
Quantitative Analysis
Table 1 shows performance comparisons on the MFNet dataset, demonstrating that SGFNet surpasses existing methods in mAcc and mIoU metrics. SGFNet achieves a 1.1\% performance gain in mAcc and 1.2\% in mIoU compared to EAEFNet. SGFNet outperforms CMX and CMNeXt, which use the SegFormer backbone, in the mIoU metric while using only a ResNet-152 backbone.
Table 2 presents performance comparisons on the PST900 dataset, where SGFNet achieves competitive performance, surpassing LASNet by 0.97\% in mIoU.
Qualitative Analysis
(Figure 4) shows a visual comparison of segmentation maps generated by SGFNet and five state-of-the-art methods. SGFNet accurately locates and segments small target objects in both daytime and nighttime scenes.

Figure 4: Qualitative comparisons on the MFNet dataset, illustrating SGFNet's superior segmentation accuracy under various illumination conditions.
Ablation Studies
Ablation studies on the MFNet dataset (Table 3) systematically analyze the impact of different components in SGFNet. The inclusion of spectral-aware feature enhancement and channel attention provides a notable 3.3\% improvement in mIoU. Incorporating global cross-modal spatial attention and deep supervision further enhances performance.
Complexity Analysis
Table 4 compares the efficiency of SGFNet with existing methods in terms of FLOPs and parameter count, demonstrating that SGFNet achieves superior performance with competitive computational efficiency. Table 5 analyzes the computational complexity and MFNet accuracy using various ResNet backbones, showing a trade-off between efficiency and performance.
Conclusion
The paper presents SGFNet, a spectral-aware global fusion network for RGB-T semantic segmentation. SGFNet refines the fusion process of multi-modal features by amplifying interactions among high-frequency features. The design includes spectral-aware feature enhancement and channel attention to facilitate cross-modal feature interaction in the spectral domain, along with a global cross-modal spatial attention module. Empirical results demonstrate that SGFNet outperforms state-of-the-art methods on the MFNet and PST900 datasets.

