- The paper demonstrates that bilevel meta-learning with MetaSPO significantly enhances prompt generalization across 14 unseen tasks.
- The paper employs a dual-loop method with an inner loop for user prompt refinement and an outer loop for system prompt optimization.
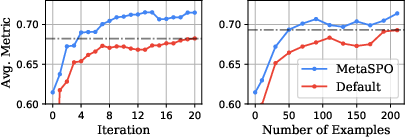
- The paper shows improved efficiency by reducing test-time adaptation iterations and lowering computational requirements.
The paper "System Prompt Optimization with Meta-Learning" introduces a novel approach for optimizing system prompts in LLMs to enhance generalization and adaptability across diverse tasks and domains. This method addresses the often overlooked component of system prompts, which are the task-agnostic instructions guiding the LLM's foundational behavior.
Introduction to Bilevel System Prompt Optimization
The research highlights the sensitivity of LLM performance to both system and user prompts. While prior work primarily focused on optimizing user prompts for specific tasks, this study emphasizes the importance of optimizing system prompts. The goal is to create prompts that are robust and capable of transferring across various tasks, including those not encountered during the optimization phase.
Traditional prompt optimization methods focus on single-task user prompts, limiting their generalization to tasks outside the training distribution. By contrast, bilevel system prompt optimization aims to enhance the flexibility and transferability of system prompts. The process is framed as a bilevel optimization problem, where the higher-level objective is the system prompt's generalization across tasks, and the lower-level objective involves optimizing user prompts for task-specific performance.
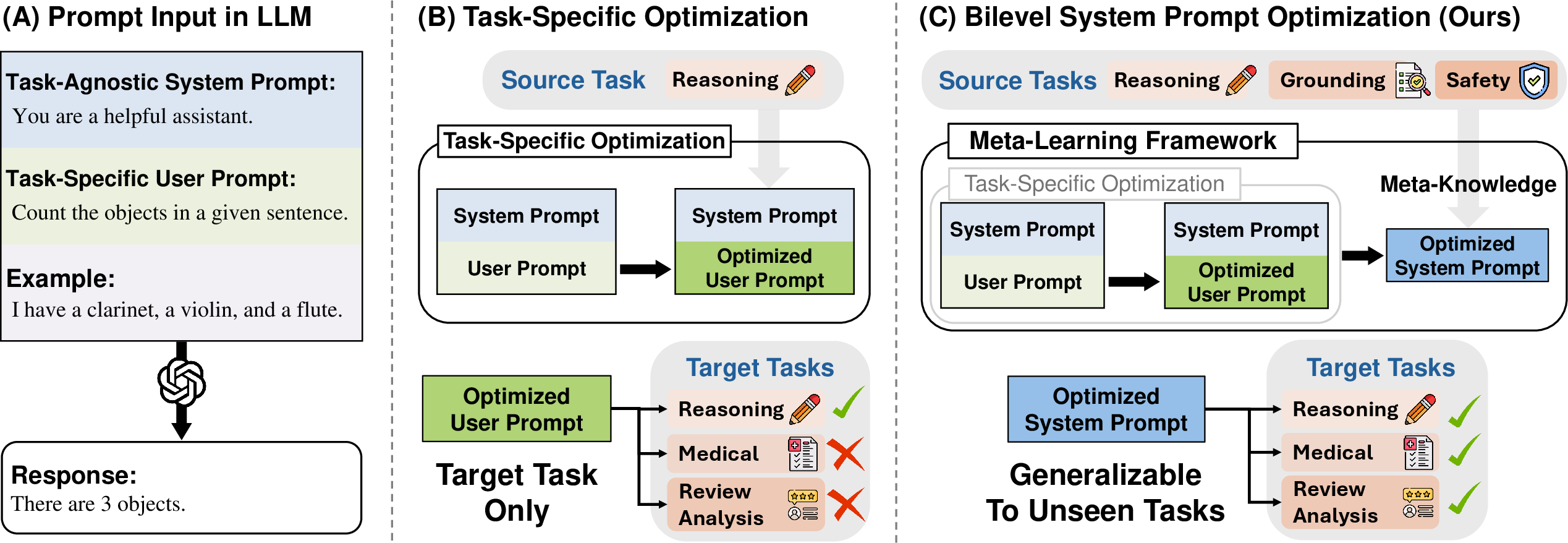
Figure 1: Concept Figure illustrating the distinction between conventional task-specific optimization and bilevel system prompt optimization.
The proposed method, Meta-level System Prompt Optimizer (MetaSPO), utilizes a meta-learning framework to optimize system prompts. This framework consists of two hierarchical loops: an inner loop for user prompt optimization and an outer loop for system prompt optimization (Figure 2).
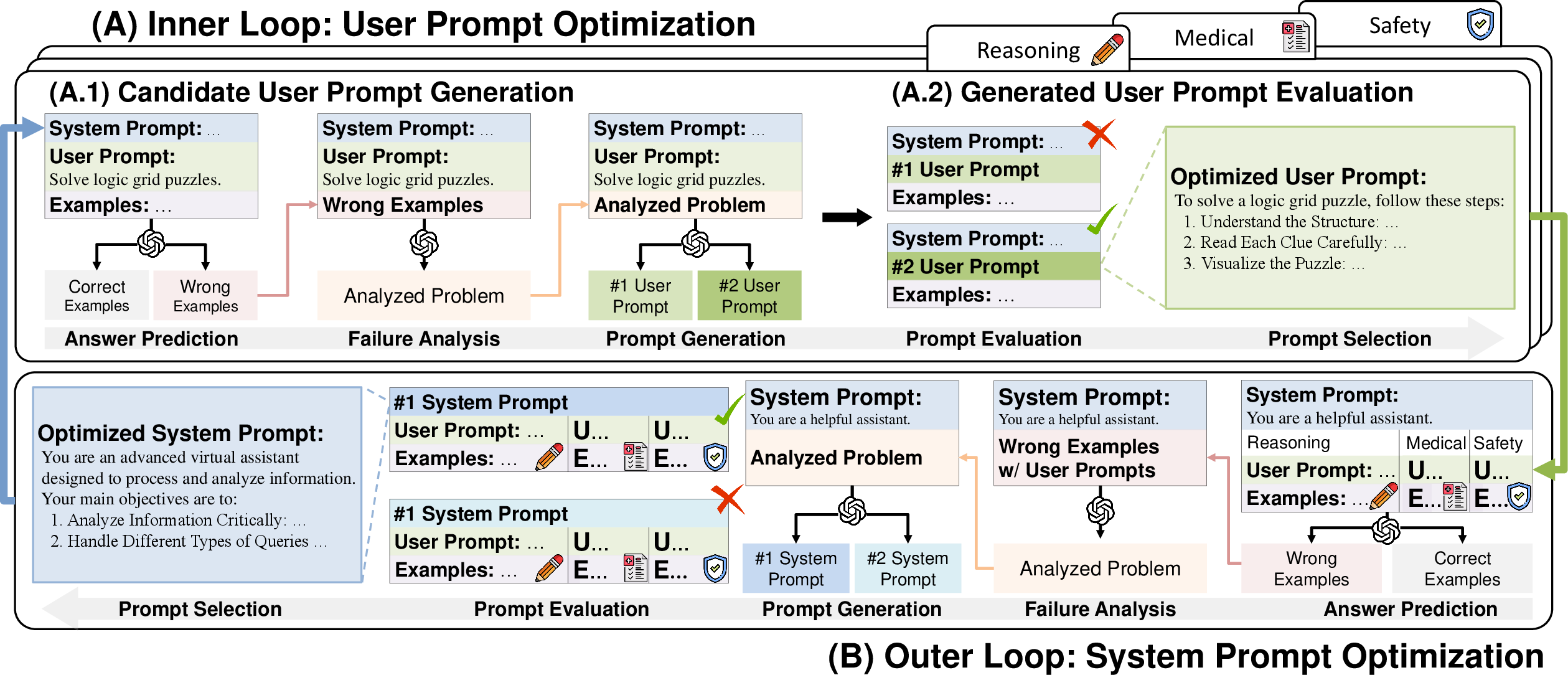
Figure 2: Overview of MetaSPO's inner and outer loops for prompt optimization.
Inner Loop
In the inner loop, user prompts are iteratively refined to maximize task-specific performance. This involves analyzing incorrectly predicted examples to generate and evaluate candidate user prompts.
Outer Loop
In the outer loop, the system prompt is optimized across a distribution of tasks. This involves evaluating potential system prompts to ensure generality and compatibility with a variety of user prompts and tasks.
Experimental Results
The paper's experiments demonstrate significant improvements in generalization performance using MetaSPO across 14 unseen tasks from five domains. The optimization enables the system prompt to improve task performance without further user prompt adaptation:
- Unseen Generalization: MetaSPO outperforms conventional baselines by better generalizing across diverse tasks (Figure 3).
- Test-Time Adaptation: The approach also enhances the efficiency of user prompt optimization, achieving faster convergence with fewer examples.
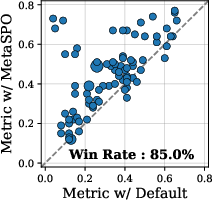
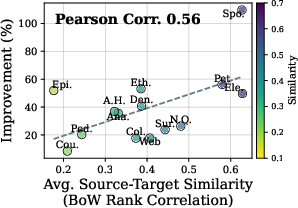
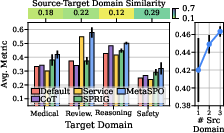
Figure 3: Performance comparison showing the superiority of MetaSPO-optimized user prompts.
Detailed Analyses
Detailed analyses in the paper highlight several key insights:
Conclusion
The introduction of bilevel system prompt optimization marks a significant advancement in enhancing the adaptability and robustness of LLMs across diverse tasks. MetaSPO's meta-learning approach effectively leverages task distributions to produce system prompts that can adapt to a wide range of scenarios with minimal additional tuning. Future work could explore further scalability of this approach, potentially extending it to other types of model adaptations and optimizations.