- The paper introduces ELIS, a novel LLM serving system that employs a BGE-based response length predictor and ISRTF scheduling to mitigate head-of-line blocking.
- The paper demonstrates a reduction in job completion time by up to 19.58% and improved GPU utilization through dynamic, prediction-driven priority adjustments.
- The paper validates ELIS in production-scale environments using Kubernetes, achieving near-linear scaling and efficient handling of bursty workloads.
Summary of "ELIS: Efficient LLM Iterative Scheduling System with Response Length Predictor" (2505.09142)
Introduction
The paper presents ELIS, an innovative serving system for LLMs, featuring the Iterative Shortest Remaining Time First (ISRTF) scheduler, designed to efficiently manage inference tasks with minimal remaining token lengths. Traditional LLM serving systems often use a first-come-first-served (FCFS) scheduling strategy, leading to the "head-of-line blocking" problem. ELIS addresses this limitation by predicting LLM inference times using a novel response length predictor trained on the BGE model. The system aims to optimize shortest job first scheduling by predicting the length of LLM-generated tokens due to challenges inherent in the auto-regressive architecture of LLMs.
Response Length Prediction
A key component of ELIS is the response length predictor designed to overcome the difficulties in predicting output lengths in auto-regressive LLMs. The predictor uses the BGE model, leveraging semantic understanding capabilities to estimate token output. The prediction process involves evaluating the immediate prompt context and subsequent generated tokens, thus improving the accuracy iteratively with each rendered token.
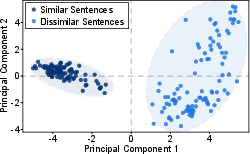
Figure 1: BGE CLS vector distance with different groups.
Experimental results demonstrate that a fine-tuned BGE model, with significant context comprehension ability, can predict response lengths with a high degree of accuracy, exhibiting an R2 of 0.852 after iterative refinement. This contrasts with prior approaches, such as instruction-tuning for LLMs, which potentially degrade the model's original accuracy.

Figure 2: (a) Illustration of prediction procedure where each step (iteration) comprises of 50 tokens and (b) MAE of predictor for each step.
Scheduling Strategy: ISRTF
ELIS introduces the ISRTF scheduling strategy as an iteration-level batching method, allowing preemptive priority adjustments based on real-time token predictions. This dynamic scheduling mitigates head-of-line blocking by prioritizing tasks with fewer remaining predicted tokens, enhancing throughput and reducing the average job completion time (JCT) by up to 19.58% compared to FCFS, verified on NVIDIA A100 GPUs.
Industrial Implementation
ELIS has been implemented at the production scale using Kubernetes, accommodating cloud-native features like auto-scalability and reliability. Evaluations based on actual LLM serving environments, such as Samsung FabriX, demonstrate near-linear scaling performance with the capability to handle bursty and high-intensity request rates effectively.
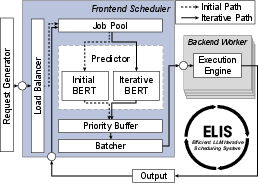
Figure 3: Overall architecture of ELIS.
Preemption and Efficiency
From the perspective of cloud service providers, ELIS supports preemption strategies that prioritize high-importance tasks, increasing GPU utilization efficiency. By analyzing real-world operational data from FabriX, ELIS can dynamically adjust and counteract resource saturation issues, ensuring high throughput without excessive latencies.
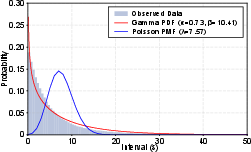
Figure 4: Request interval distribution of LLM serving. The Gamma PDF and Poisson PMF distributions were fitted based on the observed data.
Evaluation and Results
In comprehensive evaluations, ISRTF demonstrated superior performance over conventional FCFS and SJF scheduling strategies across different workloads and configurations. Its ability to dynamically adjust priorities based on continuously refined predictions led to substantial reductions in queuing times and improved overall system responsiveness.
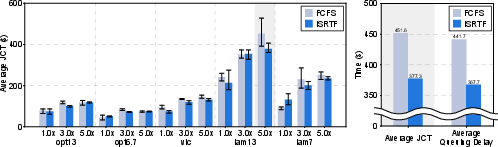
Figure 5: JCT comparison between FCFS and ISRTF where each experiment uses a multiple of average throughput. Bar represents the average value and each tick represents the minimum and the maximum value of each experiment.
Additionally, scalability tests confirmed that ELIS can manage increased worker nodes efficiently, maintaining performance improvements across various backend configurations without significant scheduling overhead.
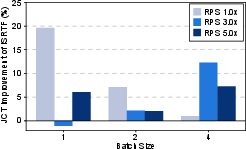
Figure 6: JCT improvement of ISRTF over FCFS.
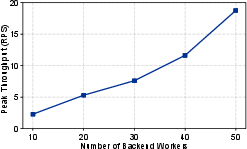
Figure 7: Peak request rate where the average queuing delay of each worker does not exceed 0.5 s with different number of backend workers.
Conclusion
ELIS represents a significant enhancement in LLM serving systems, offering robust prediction-driven scheduling with production viability. Its modular design allows for flexible adaptation in various cloud environments, potentially setting new standards for efficient LLM deployment. Moving forward, ELIS paves the way for further research into predictive scheduling algorithms and real-world deployments, highlighting the potential for integrating semantic understanding capabilities into practical inference scheduling tasks.

