- The paper introduces Approximate Feature Activation (AFA) to dynamically adapt feature sparsity, eliminating the fixed-k hyperparameter.
- It employs ZF plots and ε-quasi-orthogonality constraints to diagnose over- and under-activation with provable error bounds.
- Empirical results demonstrate that the top-AFA approach outperforms fixed-k methods in reconstructing GPT-2 embeddings for enhanced interpretability.
Evaluating and Designing Sparse Autoencoders by Approximating Quasi-Orthogonality
Sparse autoencoders (SAEs) have been integral in enhancing the interpretability of LLMs, primarily by decomposing dense embeddings into sparse, interpretable feature vectors. Despite their utility, the state-of-the-art k-sparse autoencoders (SAEs) lack theoretical grounding in selecting the hyperparameter k, representing the number of nonzero activations. This paper introduces a theoretically grounded approach to address this issue by approximating the ℓ2-norm of sparse feature vectors using the dense input vector’s norm, thus eliminating the need for manually setting k. The authors explore applications of this theoretical link in evaluating and designing SAEs.
Theoretical Contributions
The primary theoretical contribution is the Approximate Feature Activation (AFA), which provides a closed-form approximation of the ℓ2-norm of sparse feature vectors. This approximation comes with provable error bounds. The authors also introduce a method for diagnosing over- or under-activation of features through ZF plots. Additionally, the paper formalizes ε-quasi-orthogonality as a constraint related to the superposition hypothesis, forming a basis for evaluating SAEs using a novel metric, εLBO, representing the lower bound of quasi-orthogonality.
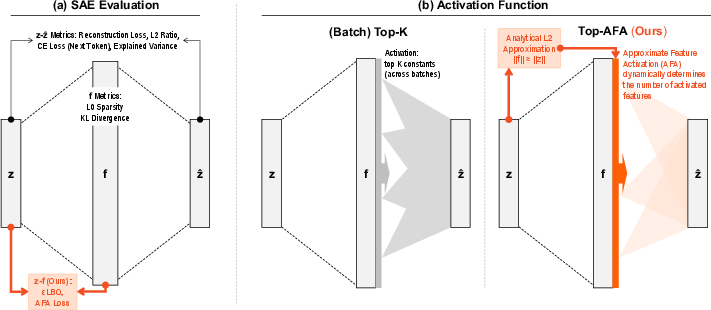
Figure 1: Comparison of SAE evaluation approaches and activation selection.
Methodological Advancements
The novel activation function, top-AFA, is a significant methodological advancement. It dynamically selects the number of active features by aligning activation norms with input norms, removing the dependency on a fixed hyperparameter k. This adaptive approach contrasts with fixed-k methodologies, enabling SAEs to better match their feature activations with input embeddings.
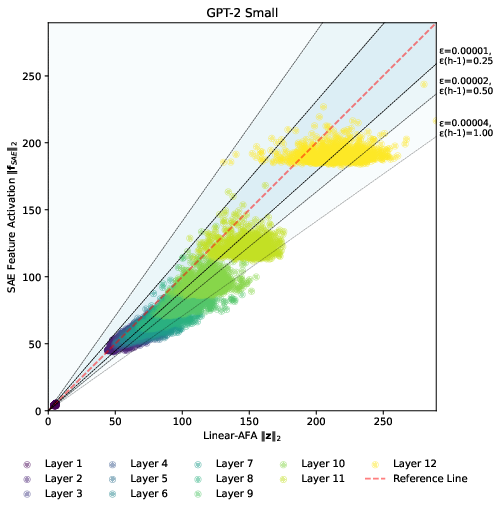
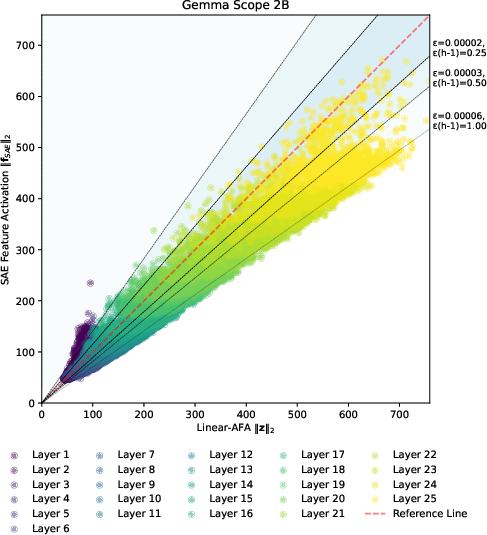
Figure 2: Relationship between dense embedding vector norm and learned feature activation norm in ZF plots.
The paper validates these concepts by training SAEs on intermediate layers to reconstruct hidden embeddings from GPT-2, achieving superior performance over k-sparse autoencoders. This empirical validation showcases the practical applicability of the theoretical framework.
Empirical Evaluation
Empirical results demonstrate that top-AFA outperforms top-k and batch top-k activation functions across multiple layers in the GPT-2 architecture. The paper presents compelling evidence that adaptively selecting the number of activations based on input norms can exceed the performance boundaries inherent in fixed-k methods.
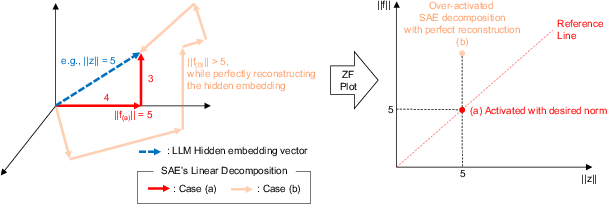
Figure 3: Geometrical intuition behind ZF plots and activation norm mismatch.
Implications and Future Directions
The implications of this research are significant for both the theoretical and practical application of SAEs in LLM interpretability. By providing a theoretically justified method to determine sparsity without a fixed hyperparameter, this work opens pathways for more adaptive architectures in other neural network applications focused on sparse representations.
Future research could explore extending the AFA framework to more complex network structures, such as multi-layer models or those incorporating non-linear transformation layers, potentially enhancing the adaptability and performance of SAEs in increasingly complex tasks.
Conclusion
The paper delivers a significant theoretical and practical contribution to the field of sparse autoencoders by introducing a framework that does not rely on a fixed sparsity level but instead adapts dynamically to input characteristics. This advancement addresses core limitations in current models and sets the stage for more robust, theoretically grounded autoencoders that can be leveraged across a variety of applications within the field of LLM interpretability and beyond.
In summary, the introduction of the Approximate Feature Activation and its empirical validation represent a notable step forward in the design and evaluation of Sparse Autoencoders, enhancing their interpretability, adaptability, and potential application range.