- The paper presents a two-level memory allocator using an LCM approach to reduce memory fragmentation for diverse LLM embeddings and caching methods.
- It leverages customizable caching and request-aware allocation, achieving 1.26× to 4.91× throughput improvements and up to 79.6% better GPU memory utilization.
- Empirical evaluations on NVIDIA H100 and L4 GPUs validate Jenga’s enhanced inference serving efficiency without increasing latency.
Jenga: Effective Memory Management for Serving LLMs with Heterogeneity
This essay provides a detailed analysis of the paper titled "Jenga: Effective Memory Management for Serving LLM with Heterogeneity" (2503.18292). The paper introduces a novel memory management framework designed to enhance the serving efficiency of LLMs with diverse architectures and computational patterns, focusing on reducing memory fragmentation and optimizing GPU resource utilization.
Introduction
Recent advancements in LLMs, such as those used in applications like ChatGPT and GitHub Copilot, have significantly increased the demand for high-performance GPUs for LLM serving. The inference stage of LLM deployment requires handling many expensive GPUs to maintain service latency, particularly when dealing with the sequential token generation characteristic of autoregressive models. However, modern GPUs are often underutilized due to the limited processing of batched requests, constrained by GPU memory capacity.
Traditionally, memory management solutions like PagedAttention have been used to address memory fragmentation issues in KV caches. This method, designed in the era of monolithic Transformer architectures, uses a single level of memory management to reduce fragmentation by mapping virtual to physical memory pages. However, contemporary LLM architecture, characterized by varied embedding sizes and token dependencies, challenges traditional assumptions about fixed-size pages and full-prefix token dependencies.
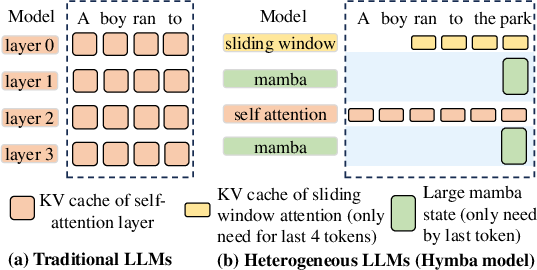
Figure 1: Traditional LLMs (left) v.s. Latest LLMs (right). LLMs are becoming more and more heterogeneous and produce KV caches with different sizes and dependencies, which demands a new GPU memory manager design.
Heterogeneous LLMs and Memory Allocation Challenges
LLMs are increasingly composed of heterogeneous elements that introduce variability in embedding dimensions, attention mechanisms, and access patterns. As shown in Figure 2, new challenges emerge with memory allocation due to:
- Heterogeneous Embeddings: Modern LLMs like LLaVA and InternVL maintain distinct vision and text embeddings of different sizes. This leads to a need for memory management systems to efficiently handle these varying dimensions without incurring substantial memory fragmentation.
- Token-Dependency Patterns: The adoption of architectures that incorporate constructs like the sliding window or Mamba, where memory dependencies vary among layers, contradicts the full-prefix token-dependency assumption.
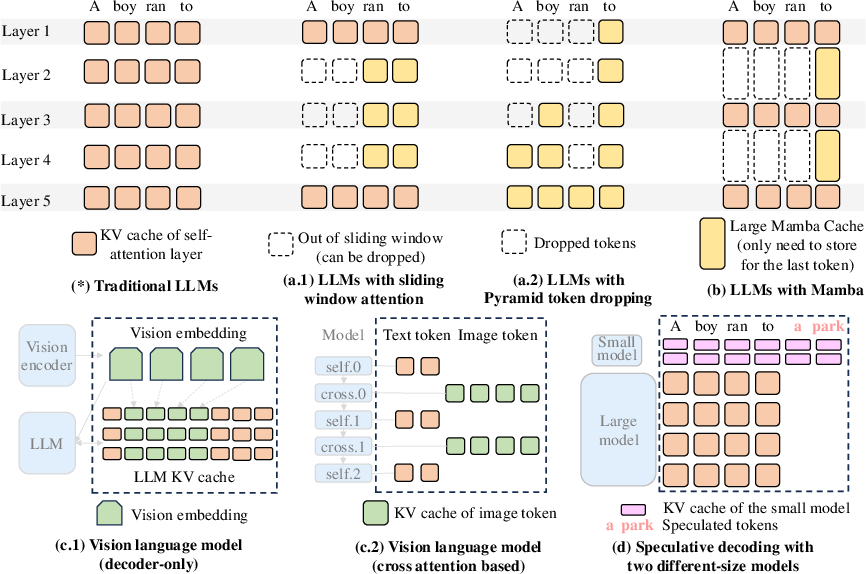
Figure 2: Contrasting traditional LLMs (top left) and latest LLMs. LLMs are becoming more heterogeneous: the KV cache sizes may differ, the KV cache dependencies are different, and the LLM architecture can also diverge.
In practice, this diversity leads to a higher likelihood of memory allocation inefficiencies and increased GPU memory footprint as demonstrated in specific architectures like LLaVA and InternVL, which have diverging KV cache and embedding dimensions.
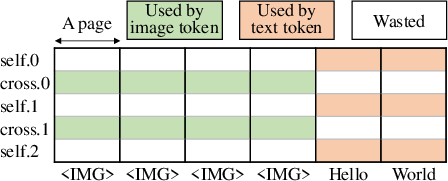
Figure 3: Visualizing the memory waste of Llama 3.2 vision model with 2 cross-attention layers (image tokens) and 3 self-attention layers (text tokens).
Proposed Framework: Jenga
Jenga addresses the inefficiencies found within PagedAttention by introducing a two-level memory allocator aimed at optimizing memory usage and effective cache management.
- Two-level Memory Allocator: The study proposes a Least Common Multiple (LCM) allocator. The fundamental theory is to allocate fixed-size large pages compatible with multiple types of embeddings by using the LCM of the sizes of different embeddings as a shared page size. This approach aims to minimize internal fragmentation while preserving the efficiency of GPU kernel operations.
- Customizable Caching and Eviction Policies: One of Jenga's key innovations is its allowance for layer-specific caching logic that can adapt to new LLM architectures which include sliding windows, Mamba or cross-attention layers, each requiring unique caching and eviction rules.
- Request-aware Allocation: A unique feature of Jenga is its ability to minimize internal fragmentation through request-aware allocation strategies.
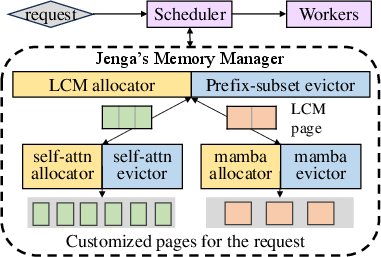
Figure 4: A two-level memory management system for different types of layers, composed of the LCM allocator for first-level page allocation and the prefix subset evictor for page deallocation.
Figure 4: Overview of : a two-level memory management system for different types of layers. is composed of the LCM allocator for first-level page allocation and the prefix subset evictor for page deallocation. Within the page, a customized allocator and evictor manage the memory for the specific layer type.
Implementations and Case Studies
The implementation of Jenga leveraged approximately 4000 lines of Python code on top of the production-level vLLM inference engine. The system is designed to be compatible with the CUDA-based attention kernels introduced by PagedAttention, such as FlashAttention.
Two-level Allocation Strategy
Jenga's two-level approach addresses the critical issue of internal fragmentation by first dividing memory into pages compatible with all layer types and then into smaller pages optimized for specific layer types.
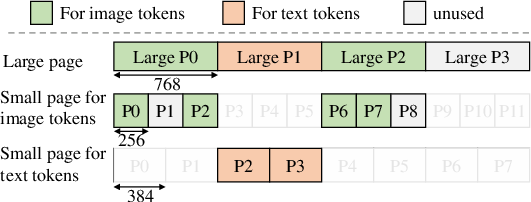
Figure 5: Two-level allocation for Llama 3.2 vision model.
This strategy allows for fine-grained cache hits and minimal fragmentation accommodating different embedding sizes, while simultaneously hosting multiple memory types efficiently.
Balanced and Aligned Cache Eviction Policy
Jenga's cache eviction mechanism is model-awareness and can align eviction policies among layers, such as self-attention and sliding window layers. This ensures that memory hits, which are dependent on the un-evicted items in the cached memory, are optimized.
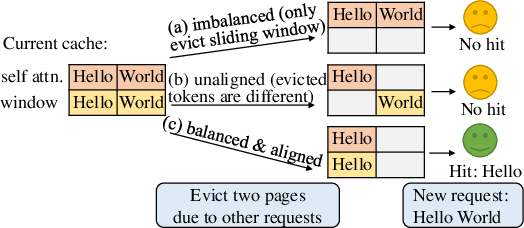
Figure 6: Balanced and aligned cache eviction policy can improve hit rate.
Case Study: Vision Embedding Cache of VLMs
The handling of vision-LLMs involves managing both the KV caches of text tokens and vision embeddings for image inputs. Jenga's adaptable cache management significantly mitigates redundant computations and minimizes peak memory consumption.
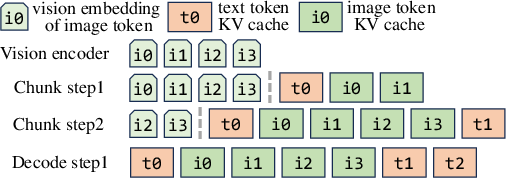

Figure 7: Vision embedding cache for allocate-on-demand KV cache.
The integration of customized memory eviction policies make Jenga suitable for speculative decoding and multi-model serving. The Jenga framework's ability to dynamically manage memory ensures no additional memory is consumed whilst allowing optimal reuse of resources.
Jenga was rigorously evaluated on a variety of LLM architectures and GPU configurations, including NVIDIA H100 and L4 GPUs.
Throughput
In comparison to state-of-the-art solutions, Jenga demonstrated significant improvements in throughput, ranging from 1.26× to 4.91×. The improvements illustrate the reduction in memory fragmentation and enhanced prefix caching leading to more efficient batch processing.
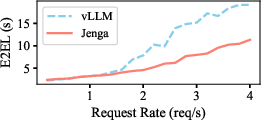
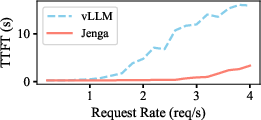
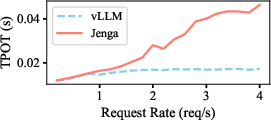
Figure 8: Averaged Latency for the Llama Vision Model (mllama) with changing request rates. E2EL denotes end-to-end latency, TTFT denotes time to first token, and TPOT denotes time per output token.
Memory Utilization
The improved memory management resulted in up to a 79.6% increase in GPU memory utilization compared to leading frameworks like vLLM. Notably, Jenga was shown to significantly reduce memory waste (Figure 3; Figure 9).
Figure 3: Visualizing the memory waste of Llama 3.2 vision model with 2 cross-attention layers (image tokens) and 3 self-attention layers (text tokens).
Conclusion
"Jenga: Effective Memory Management for Serving LLM with Heterogeneity" (2503.18292) presents an innovative approach to memory management for heterogeneous LLMs. By employing a unique two-level memory allocation system, Jenga optimizes GPU memory usage and enables refined cache management strategies. The framework exhibits substantial improvements in GPU memory utilization and inference serving throughput without degrading latency, paving the way for efficient deployment of complex LLM architectures. Future work includes further integration with a wider range of current LLMs and potentially refining its application in serving multiple models concurrently. As LLM architectures continue to evolve and diversify, approaches like Jenga will be indispensable in meeting the dynamic demands of modern AI applications.