- The paper introduces the SPPO framework to enhance long-sequence LLM training by reducing memory bottlenecks and computational imbalances.
- It employs a dual strategy of sequence-aware offloading and adaptive pipeline scheduling to efficiently partition and manage subsequences.
- Experimental results demonstrate up to 3.38× throughput improvement and near-linear scalability on models like GPT-65B using extensive GPU resources.
SPPO: Efficient Long-sequence LLM Training via Adaptive Sequence Pipeline Parallel Offloading
The paper "SPPO: Efficient Long-sequence LLM Training via Adaptive Sequence Pipeline Parallel Offloading" presents a novel framework aimed at enhancing the efficiency of training LLMs on long sequences. The proposed framework, SPPO, introduces an innovative combination of adaptive sequence pipeline parallel offloading to address the memory and computational challenges inherent in long-sequence LLM training.
Motivation and Challenges
Training LLMs on long sequences poses substantial challenges related to high GPU memory and computational demands. Existing solutions often compromise on training efficiency due to the limitations of memory reduction techniques like activation recomputation and CPU offloading, alongside the excessive GPU resource consumption of distributed parallelism strategies.
Key Challenges
- Memory Inefficiency: Activation recomputation and CPU offloading introduce significant overhead, limiting their effectiveness in long-sequence training.
- Excessive GPU Resource Consumption: Models with massive parameters and long sequences demand large GPU resources, significantly hindering scalability.
SPPO Framework
SPPO seeks to optimize both memory and computational efficiency. It builds upon previous partitioning methods by employing CPU offloading and pipeline scheduling at the subsequence level. This strategy aims to solve computation imbalances across subsequences and minimize memory allocation discrepancies.
Adaptive Offloading
SPPO employs a two-pronged strategy for adaptive offloading:
- Sequence-Aware Offloading: This strategy dynamically adjusts the offloading ratio to enhance overlap between computation and offloading, thus reducing idle GPU times. It mitigates imbalances by aligning the offloading with the computation of subsequent subsequences.

Figure 1: Performance comparisons of SPPO and SOTA training systems on extremely long sequences of total 1B tokens, using 32, 64, and 128 GPUs, respectively.
Adaptive Pipeline
The adaptive pipeline strategy of SPPO integrates a heuristic solver to determine optimal subsequence partitioning. SPPO also applies multiplexing sequence partitioning to improve pipeline efficiency by further dividing subsequences, reducing resource bubbles, and enhancing memory efficiency.
Figure 2: Illustration of the pipeline parallelism scheduling with the increasing sequence length and our sequence pipeline parallel offloading scheduling.
Implementation and Evaluation
SPPO was evaluated using various LLM architectures and sequence lengths. It showcases superior performance with up to 3.38× throughput improvement over existing frameworks like Megatron-LM and DeepSpeed. SPPO effectively reduces GPU resource requirements and supports longer sequence lengths without out-of-memory errors.
Experimental Results
SPPO demonstrates near-linear scalability in sequence length, significantly outperforming baseline systems. For example, for GPT-65B, it scaled efficiently to sequence lengths of 4M tokens using 128 NVIDIA A100 GPUs.
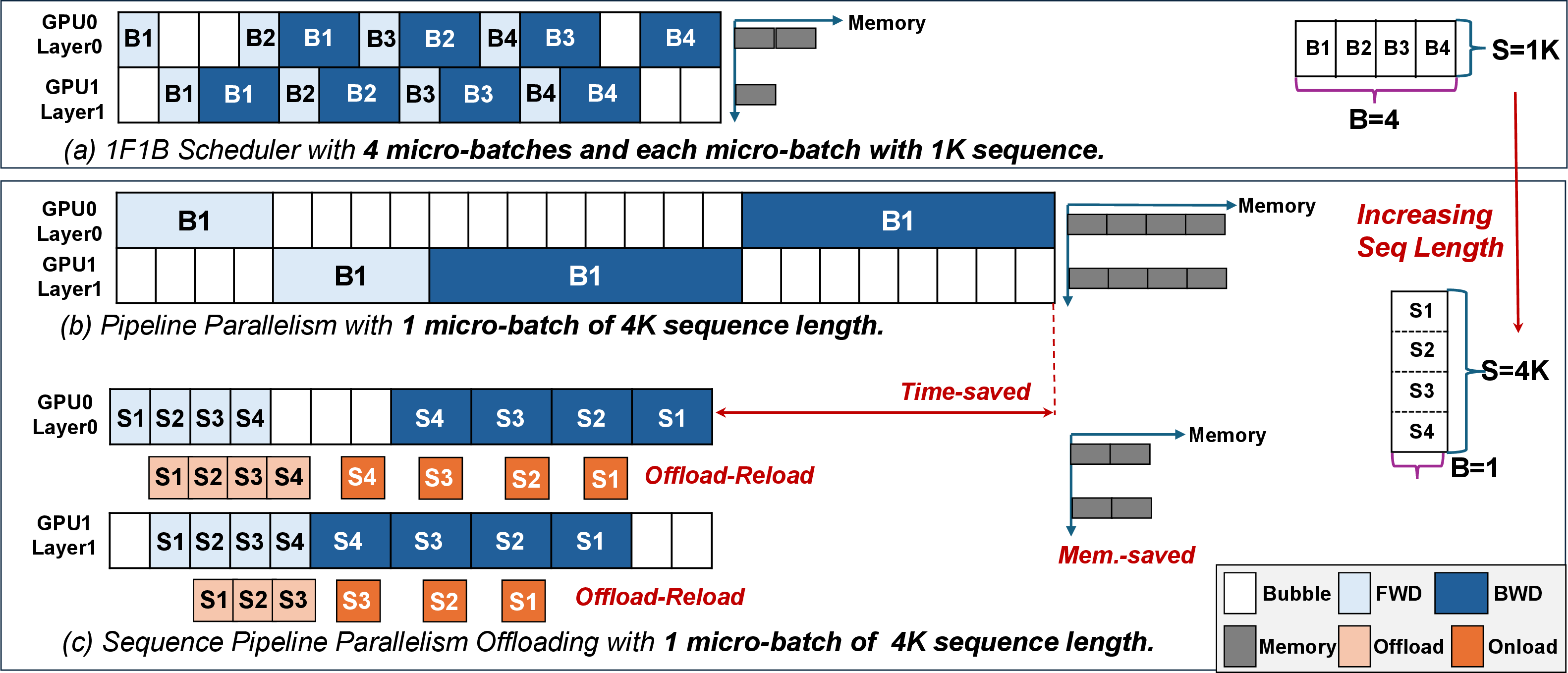
Figure 3: The relationship between subsequence length and overall forward propagation and bubble time for one transformer layer with a hidden dimension of 4096 and a fixed sequence length of 128K.
Conclusion
SPPO represents a significant advancement in LLM training on long sequences. By optimizing subsequence-level offloading and sequence partitioning, it addresses crucial efficiency bottlenecks in memory usage and computational resource allocation, enhancing both the scalability and speed of LLM training. These innovations could pave the way for broader LLM applications in various AI domains.

