- The paper introduces a novel Linear-MoE architecture that integrates linear sequence modeling with mixture-of-experts to achieve efficient and scalable training.
- It details a hybrid approach combining LSM and Transformer-MoE layers to balance performance and recall for long-context tasks.
- Extensive benchmarking confirms improved inference speed, stable GPU memory usage, and robust performance across various model sizes and sequence lengths.
Linear-MoE: Linear Sequence Modeling Meets Mixture-of-Experts
Introduction
The paper "Linear-MoE: Linear Sequence Modeling Meets Mixture-of-Experts" presents the Linear-MoE architecture that integrates Linear Sequence Modeling (LSM) with Mixture-of-Experts (MoE) to address efficiency and scalability challenges in large-scale model training. The authors introduce a production-level system featuring two subsystems: Modeling and Training. The system is designed to leverage the linear complexity of LSMs and the sparse activation of MoE layers, offering high performance with efficient training on large datasets.
Linear-MoE Architecture
The Linear-MoE architecture consists of stacked Linear-MoE blocks, each incorporating an LSM layer followed by an MoE layer, with normalization layers preceding each component.
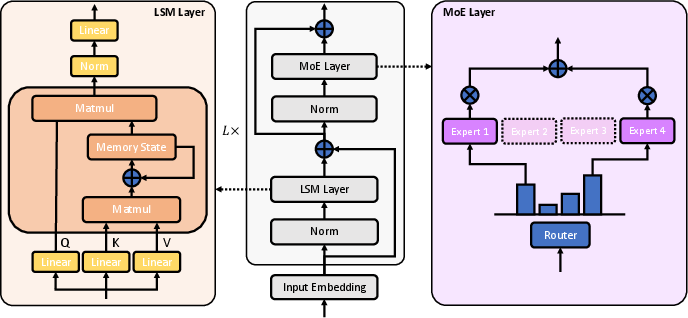
Figure 1: Linear-MoE Architecture. In each Linear-MoE block, there is both an LSM layer and an MoE layer, with each layer preceded by its own normalization layer. The LSM layer is designed as a flexible abstraction of LSM methods, including: linear attention, SSM, and linear RNN, which follows a unified recurrence framework.
The architecture design allows support for various LSM methods—linear attention, state space models (SSM), and linear RNN—all unified under a common recurrence framework. Pure Linear-MoE models, composed entirely of Linear-MoE layers, achieve high efficiency in training and inference. However, due to the challenges of tasks requiring strong recall capabilities, the authors also investigate hybrid models that interleave Linear-MoE layers with standard Transformer-MoE layers, offering a balanced approach to model flexibility and performance.
Sequence Parallelism
To efficiently handle extremely long input sequences in large-scale distributed clusters, the paper extends existing sequence parallelism methods to the Linear-MoE system. Specifically, the authors introduce a refined approach for sequence parallelism (SP) that significantly enhances scalability and efficiency of training Linear-MoE models on long-context tasks.
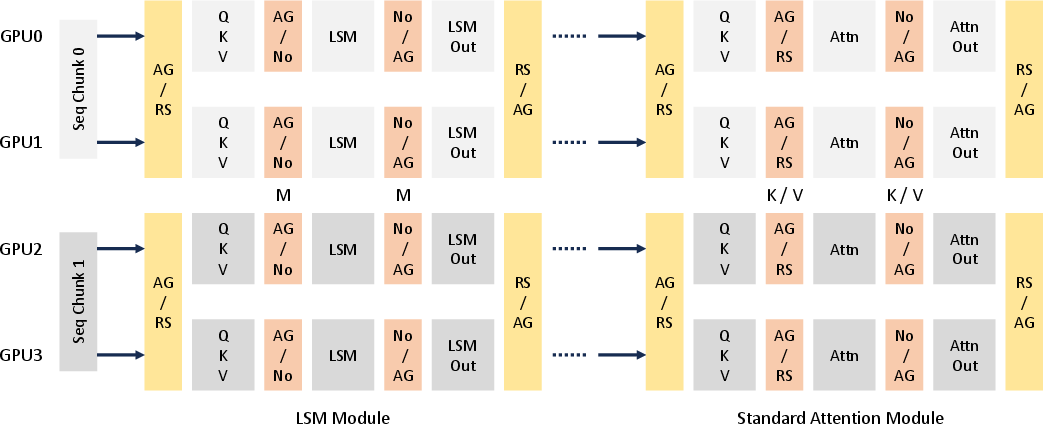
Figure 2: Sequence Parallelism Approach on Hybrid Linear-MoE models. We exemplify the parallelism on the hybrid layers of LSM and standard attention with both TP and SP.
The implementation involves synchronized incremental state updates across devices, utilizing advanced communication strategies to minimize data transfer and dependency management overheads.
Training Efficiency
The Training subsystem of the Linear-MoE system incorporates a spectrum of parallelism techniques, including Tensor Parallelism (TP), Sequence Parallelism (SP), Pipeline Parallelism (PP), and Expert Parallelism (EP). These techniques are seamlessly integrated into the system, allowing for scalable and efficient training across diverse hardware configurations.
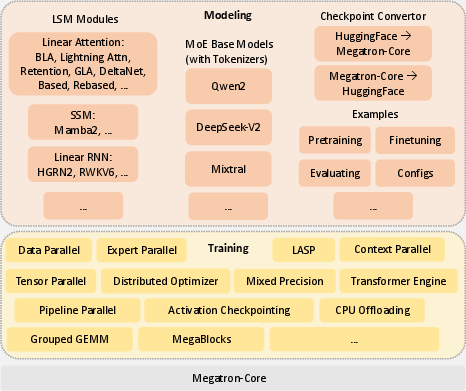
Figure 3: Linear-MoE System Implementation. The Linear-MoE system is composed of two main subsystems: Modeling and Training.
The subsystem is built upon Megatron-Core, providing compatibility with NVIDIA's Tensor Core-equipped GPUs, thereby supporting mixed and low precision, such as FP8, to optimize memory usage and performance.
Empirical Evaluation
The authors conduct extensive benchmarking of the Linear-MoE system on two model series: A0.3B-2B and A1B-7B. The results demonstrate strong training efficiency with stable GPU memory consumption and consistent throughput across varying sequence lengths. Additionally, inference evaluations reveal that Linear-MoE system significantly reduces memory usage and increases processing speeds, particularly with long decoding lengths.
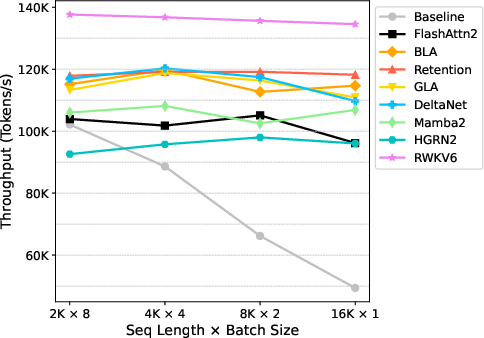
Figure 4: Training Throughput (Tokens/s). As sequence length increases, the throughput of Baseline declines significantly, whereas LSM models maintain stable training efficiency.
The benchmarking results further confirm that hybrid Linear-MoE models offer improved accuracy and performance stability on complex language modeling tasks compared to pure Linear-MoE configurations.
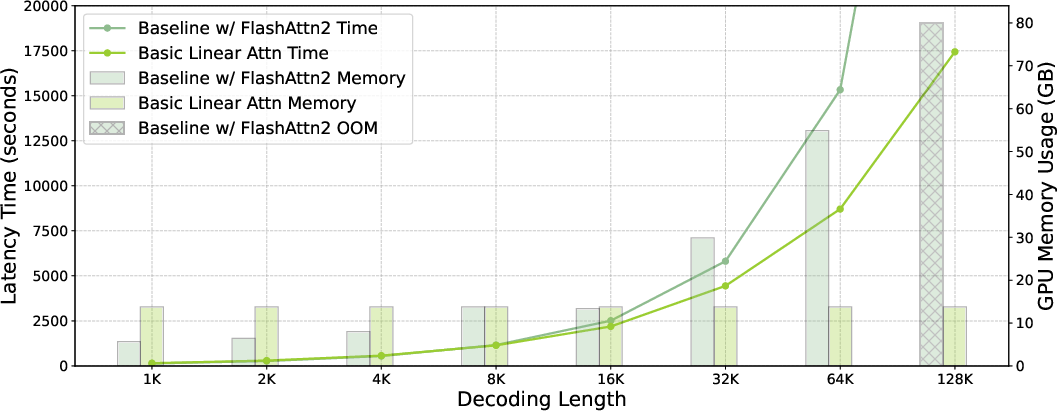
Figure 5: Inference Efficiency of A0.3B-2B Model Instances.
Conclusion
Linear-MoE represents an advancement in large-scale model architectures by effectively combining LSM's linear complexity sequence modeling with MoE's sparsity. The presented system framework demonstrates significant efficiency benefits and maintains robust performance on diverse evaluation tasks and metrics. The architectural innovations and results position Linear-MoE as a potential foundation for future developments in LLMs.
In conclusion, while Linear-MoE provides a promising framework for efficient training and inference of large models, further exploration into dynamic hyperparameter settings and scalability on larger setups presents opportunities for future research.

