- The paper introduces CrowdSelect, which leverages Multi-LLM Wisdom and three novel metrics—Difficulty, Separability, and Stability—to enhance synthetic instruction data selection.
- It demonstrates significant gains in model performance, with improvements of 11.1% on MT-bench and 4.81% on Arena-Hard benchmarks using smaller datasets.
- The clustering-based strategy and integrated metrics optimize high-quality data selection, balancing computational cost with enhanced efficiency in model training.
CrowdSelect: Advancements in Synthetic Instruction Data Selection
The paper "CrowdSelect: Synthetic Instruction Data Selection with Multi-LLM Wisdom" presents an innovative approach to instruction data selection aimed at distilling the instruction-following capabilities of advanced LLMs into smaller models. By leveraging the collective responses from multiple LLMs (referred to as Multi-LLM Wisdom), the paper introduces a multi-faceted data selection method that enriches model training processes.
Introduction and Motivation
The computational demands and vast parameter sizes of LLMs pose substantial challenges for widespread application. In response, distilling large models into smaller, efficient models through instruction tuning with synthetic responses has emerged as a viable solution. Traditional data selection methods often rely on single-dimensional metrics, like reward scores or perplexity, which fail to capture the nuanced complexities of instruction-following across various domains.
Methodology
CrowdSelect introduces three innovative metrics for data selection: Difficulty, Separability, and Stability. These metrics are calculated based on the responses from multiple LLMs and their corresponding reward model scores.
- Difficulty assesses the challenge an instruction poses by measuring the average performance across LLMs, prioritizing complex instructions critical for learning improvements.
- Separability evaluates the variance in model responses, identifying instructions that differentiate between high and low-performing models, beneficial for distinguishing model capabilities.
- Stability measures the consistency of model performance rankings relative to their size, helping to establish solid alignment signals.
These metrics are integrated into CrowdSelect with a clustering-based strategy to maintain response diversity, optimizing the creation of a compact yet impactful subset of instruction-response data.
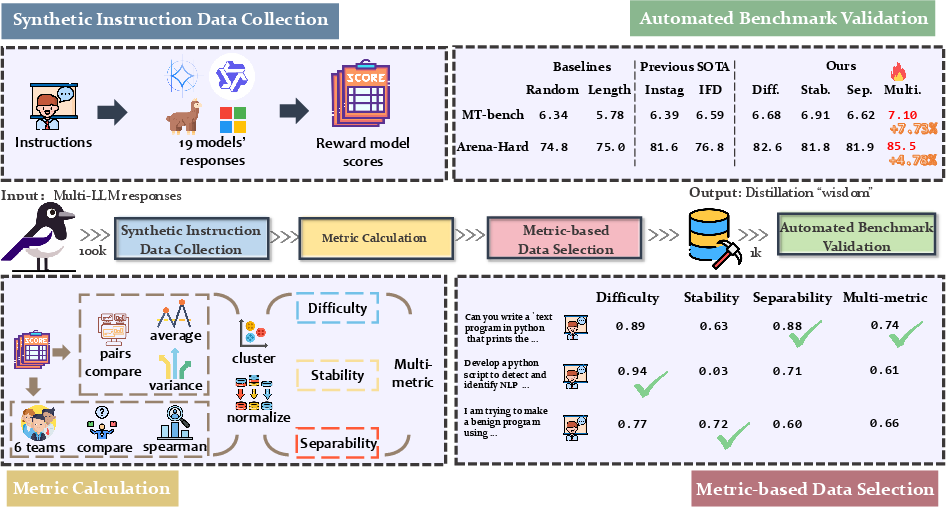
Figure 1: The overall pipeline of CrowdSelect, innovatively leveraging metrics from various instruction facets using synthesized responses from LLMs.
Experimental Results
The experiments demonstrate that CrowdSelect excels in selecting high-quality data subsets that significantly enhance model performance. Applying CrowdSelect to Llama-3.2-3b-instruct showcased improvements of 11.1% on MT-bench and 4.81% on Arena-Hard benchmarks. Across different fine-tuning methods such as FFT and LoRA, CrowdSelect consistently surpasses existing state-of-the-art data selection methodologies.
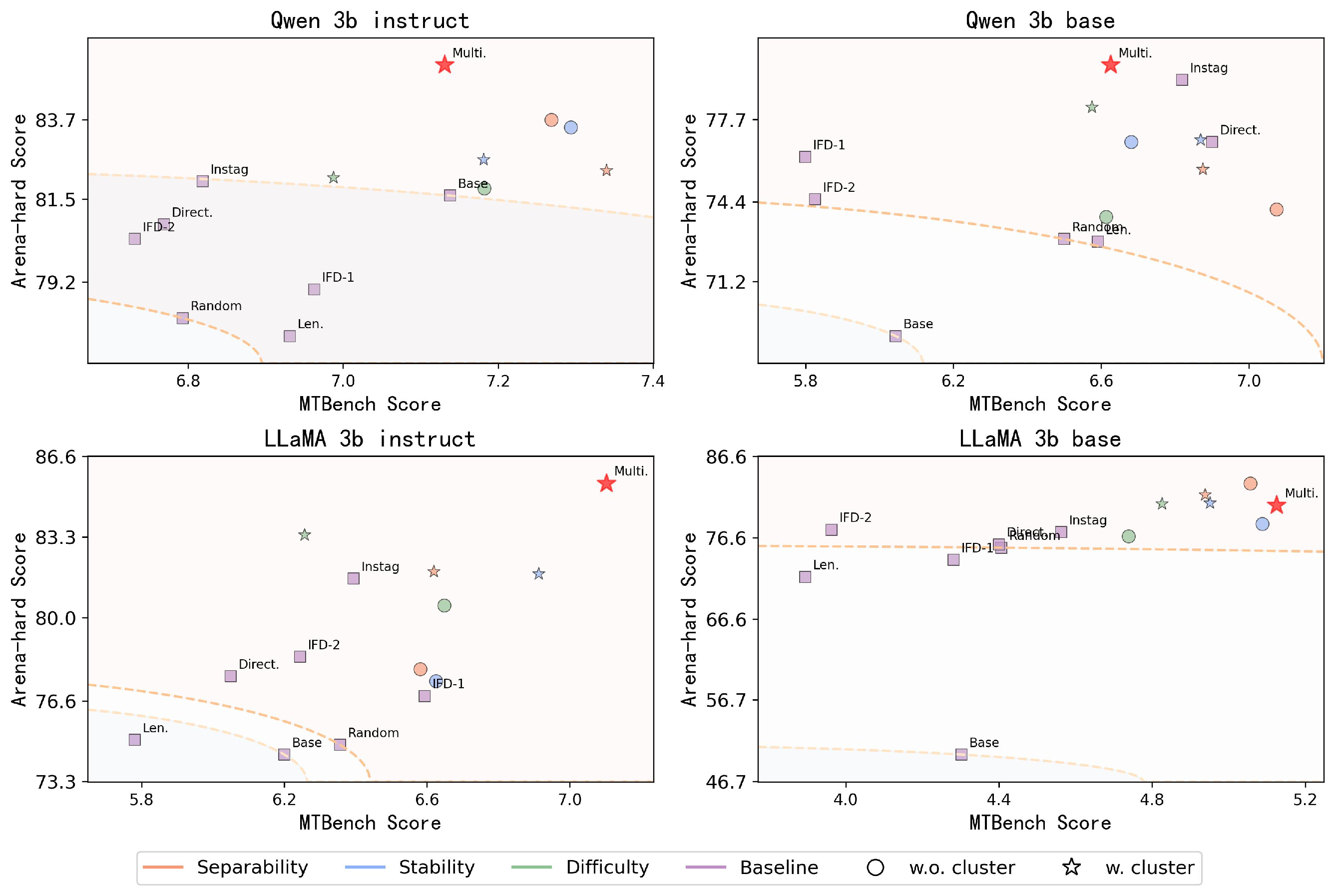
Figure 2: Overall results demonstrate that our foundation metrics and CrowdSelect consistently outperform baseline methods by a significant margin across FFT settings of four models.
Additionally, experiments confirmed that smaller, high-quality datasets selected through CrowdSelect could achieve performance levels on par with larger datasets, emphasizing the importance of data quality in instruction tuning processes.
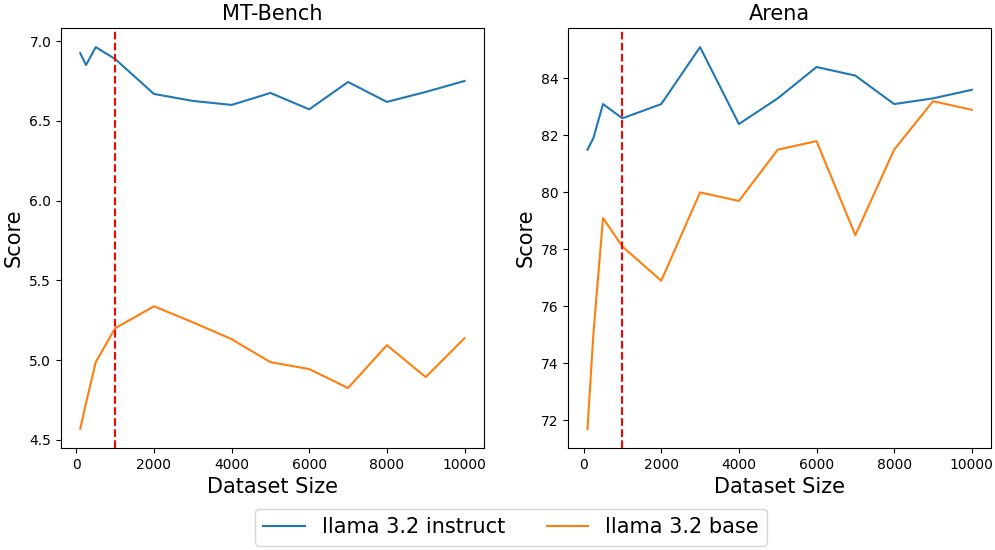
Figure 3: Results show that small elite datasets behave on par with a large dataset, corresponding to the experiment results in previous studies.
Trade-offs and Implementation Considerations
The adoption of CrowdSelect involves balancing computational costs with potential gains in performance. The requirement of extensive multi-LLM evaluations for metric computations can be resource-intensive, yet the substantial improvements in model efficiency and effectiveness observed justify these efforts. Practitioners are guided to consider the availability of various LLM responses and computational resources when implementing CrowdSelect.
Conclusion
CrowdSelect stands as a significant contribution to the field of AI model training, particularly instruction tuning. By leveraging Multi-LLM Wisdom and introducing novel data selection metrics, it presents a paradigm shift towards more effective data utilization. The implications extend to various AI applications, offering a robust methodology for enhancing model performance and maximizing resource efficiency. As the model continues to evolve, future research may explore integrating more sophisticated reward models and optimizing computational resource usage.