- The paper introduces a novel MXFP4 training recipe that combines stochastic rounding and Random Hadamard Transform to produce unbiased gradients for efficient LLM training.
- Empirical tests on GPT models up to 6.7B parameters show speedups greater than 1.3× over FP8 and 1.7× over BF16, with negligible differences in perplexity.
- The methodology paves the way for using low precision datatypes to reduce computational costs while maintaining high model performance in large-scale deployments.
Efficient Low Precision Training with MXFP4
The paper entitled "Training LLMs with MXFP4" (2502.20586) explores techniques to leverage low precision datatype, specifically MXFP4, for efficient training of LLMs. This methodology proposes significant speedup during training by mitigating the degradation of model quality typically associated with low precision formats.
Introduction to MXFP4 for LLM Training
MXFP4 is a low precision datatype used to accelerate training by reducing the computational cost of General Matrix Multiplications (GEMMs). Despite its potential for speedup, direct utilization of MXFP4 can degrade model quality when replacing higher precision formats like BF16 during training. To overcome this limitation, the paper introduces a novel training recipe for MXFP4 that maintains model quality comparably to BF16 while offering significant speed advantages.
The methodology revolves around two core innovations: the use of stochastic rounding (SR) to compute unbiased gradients and the Random Hadamard Transform (RHT) to bound the variance introduced by stochastic rounding (Figure 1).
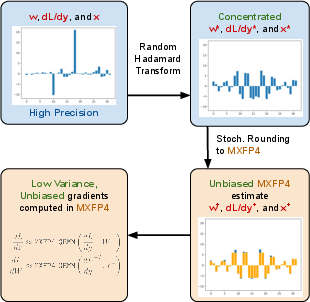
Figure 1: Our method uses stochastic rounding (SR) to compute unbiased gradients and the random Hadamard transform to bound the variance of SR. This enables us to perform more accurate model updates with MXFP4 in the backward pass, enabling a speedup of >1.3\times over FP8 and >1.7\times over BF16.
Unbiased Gradient Estimates with MXFP4
Standard MXFP4 quantization can introduce bias, particularly when dealing with high variance or block-level outlier data. To address this challenge, the authors apply unbiased stochastic rounding which computes gradient estimates with less distortion. The SR technique ensures each element is rounded in a manner that preserves the expectation of the quantity, reducing variance due to random noise-induced in quantization.
Moreover, the application of the Random Hadamard Transform (RHT) effectively manages variance and keeps stochastic rounding's impact on convergence in check. RHT is pivotal in concentrating the gradient distributions, aiding in managing the quantization variance, thus promoting a more stable training process.
Experimental Results
The authors tested their approach on GPT models with parameter sizes up to 6.7B, demonstrating minimal model degradation when comparing MXFP4 training to BF16 mixed precision training. Validation curves illustrate that models trained with MXFP4 and RHT closely follow those trained using BF16, revealing negligible discrepancies in perplexity (Figures 3-5).
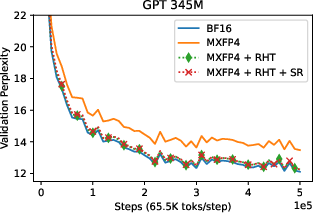
Figure 2: GPT 345M validation perplexity curves with BF16 forward pass. With RHT and SR, MXFP4 can match the performance of BF16 in the backward pass.
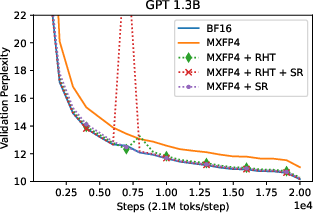
Figure 3: GPT 1.3B validation perplexity curves with BF16 forward pass. With RHT and SR, MXFP4 can match the performance of BF16 in the backward pass.
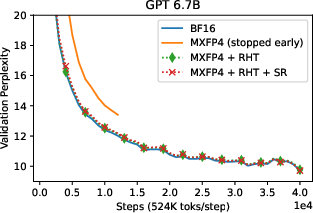
Figure 4: GPT 6.7B validation perplexity curves with BF16 forward pass. With RHT and SR, MXFP4 can match the performance of BF16 in the backward pass. The MXFP4-only run was stopped early to save resources.
Empirically, the technique secures a training speedup over FP8 by a factor greater than 1.3 and over BF16 by more than 1.7 in backpropagation operations, confirming substantial efficiency gains without sacrificing model integrity.
Implications and Future Work
The proposed method offers a pathway to leverage low precision formats effectively in LLM training by eliminating precision-related drawbacks typically encountered during training. With the continuous advancement in hardware supporting low precision operations, the presented approach holds promise for reducing computational resource demands in large-scale model training.
Future work could investigate further optimizations in hardware specific implementations or extend this technique to other low precision datatypes within the microscaling family to explore their potential benefits in LLM training pipelines.
Conclusion
"Training LLMs with MXFP4" introduces novel methods that effectively harness MXFP4, ensuring near-lossless training while substantially accelerating the process compared to traditional higher precision formats. Emphasizing the blend of stochastic rounding and the Random Hadamard Transform, this approach stands as a leading candidate for efficient training frameworks of increasingly large and computationally expensive models.