- The paper introduces BaKlaVa, a method that profiles KV-caches via cosine similarity to determine attention head importance.
- It employs a heuristic estimation and parameter search based on perplexity benchmarks to optimize memory allocation under compression.
- Empirical evaluations on LLaMA-3-8B and Qwen2.5-7B show significant performance improvements in long-context inference.
Detailed Summary of "BaKlaVa -- Budgeted Allocation of KV Cache for Long-context Inference"
Introduction
The paper introduces BaKlaVa, a method designed to optimize the allocation of Key-Value (KV) caches in LLMs during inference, specifically for long-context scenarios. Traditional LLM inference methods face a significant challenge due to the increasing GPU memory requirements as context lengths grow. BaKlaVa aims to address this by estimating and optimizing the importance of individual KV-caches across different attention heads, employing a profiling approach that does not require model fine-tuning.
Background
LLMs operate using multi-head self-attention mechanisms, where each attention head has associated Key (K) and Value (V) matrices stored in KV caches. These caches are critical for reducing computational redundancy during autoregressive inference. However, the storage of KV caches requires substantial GPU memory, particularly as sequence lengths increase. Current methods typically allocate memory uniformly across all attention heads, which is not optimal given the varying importance of each attention head to model performance.
The BaKlaVa Method
BaKlaVa introduces a three-step method to better allocate KV-cache memory:
- Profiling: A one-time profiling of the model with various prompts is conducted to estimate the importance of each attention head using cosine similarity between inputs and outputs of attention heads. This heuristic determines how much change occurs, associating greater change with higher importance (Figure 1).
- Heuristic Estimation: Using the profiling data, a heuristic is applied to estimate KV-cache importance across attention heads. This involves calculating the mean similarity for grouped attention heads and assigning importance scores (Figure 2).
- Memory Allocation: The importance scores guide the redistribution of KV-cache memory. A parameter search using perplexity benchmarks helps determine optimal configurations for different compression ratios.
Empirical Results
BaKlaVa was tested using the LongBench suite on LlaMA-3-8B and Qwen2.5-7B models, demonstrating significant performance improvements over existing methods like StreamingLLM and SqueezeAttention across various tasks, including few-shot learning and multi-document question answering (Figure 3 - Figure 4). The empirical evaluation also showed strong alignment between the heuristic predictions of layer importance and the actual importance derived from benchmark scores, particularly for LlaMA-3-8B (Figure 5).
Conclusions and Future Work
BaKlaVa enhances the efficiency of LLM inference by judicious KV-cache memory allocation based on estimated attention head importance. The results indicate that BaKlaVa successfully maintains near-baseline performance even under high compression ratios, offering significant advancements over existing methods. Future work aims to generalize the framework for broader adaptive memory allocation and extend support for additional eviction policies to further optimize real-world deployments.
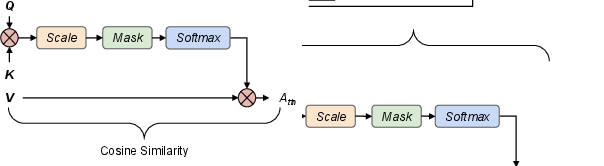
Figure 1: The attention-head similarity heuristic used in BaKlaVa. By taking the cosine similarity between the input and output, we can calculate how much change there is. The more change between the input and output of the attention head, the more important we assume it is.
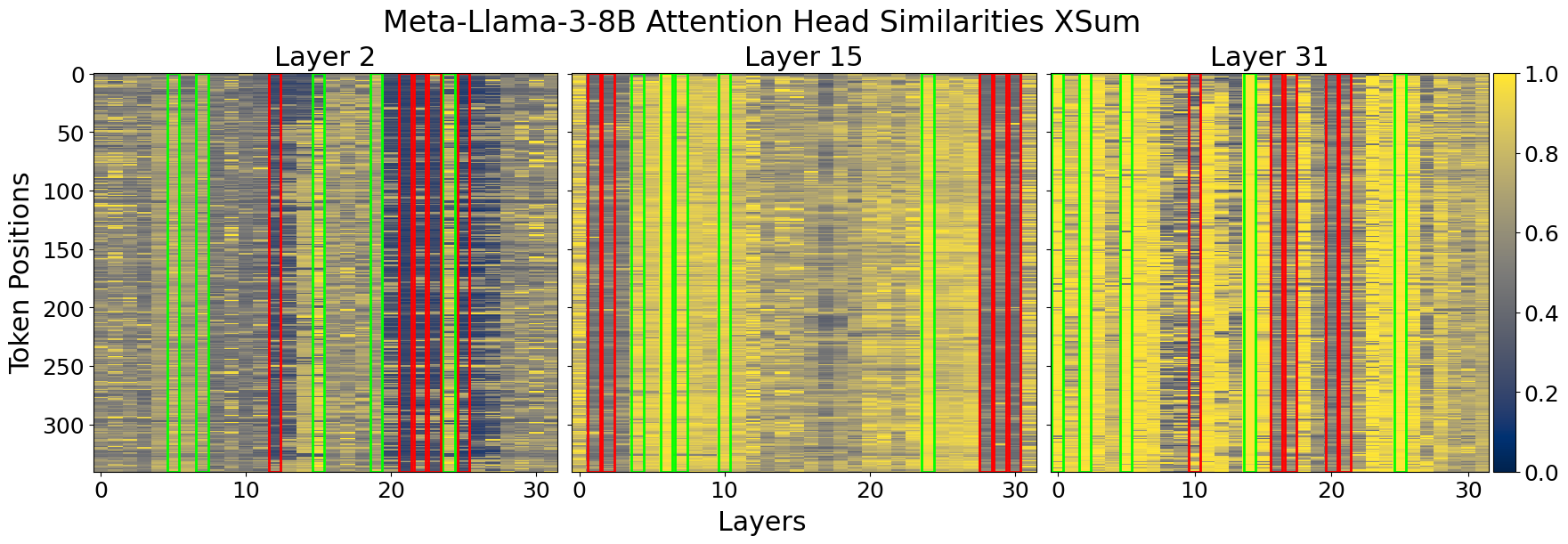
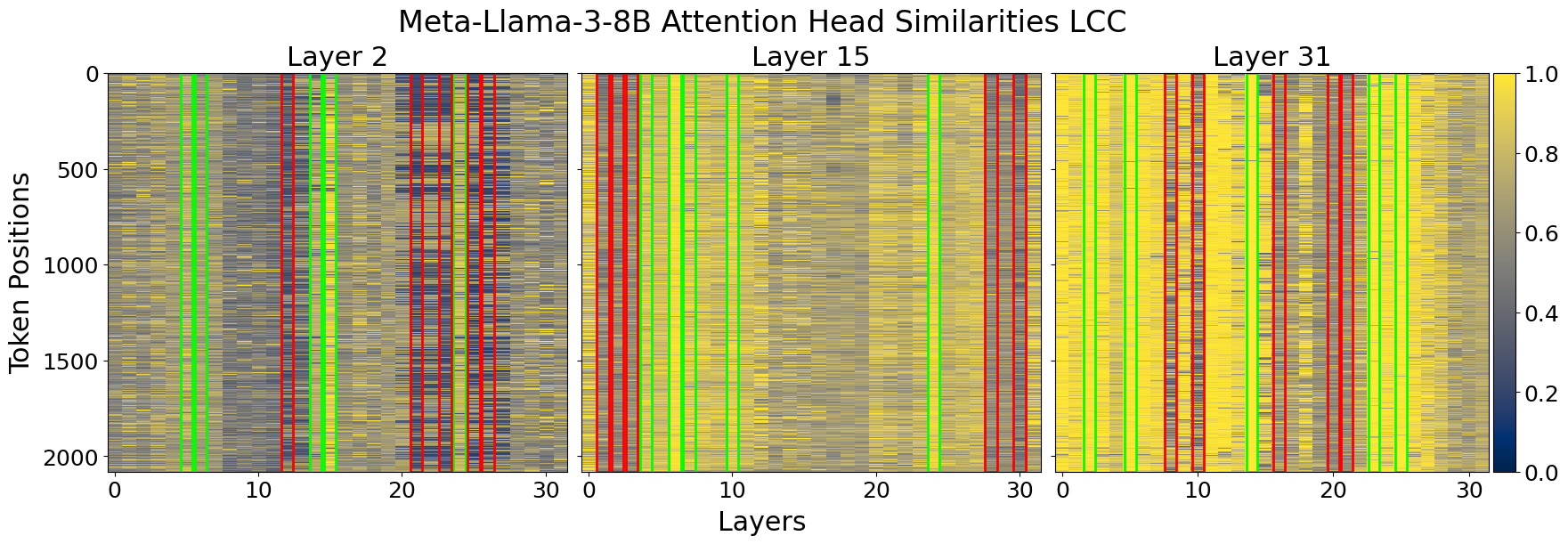
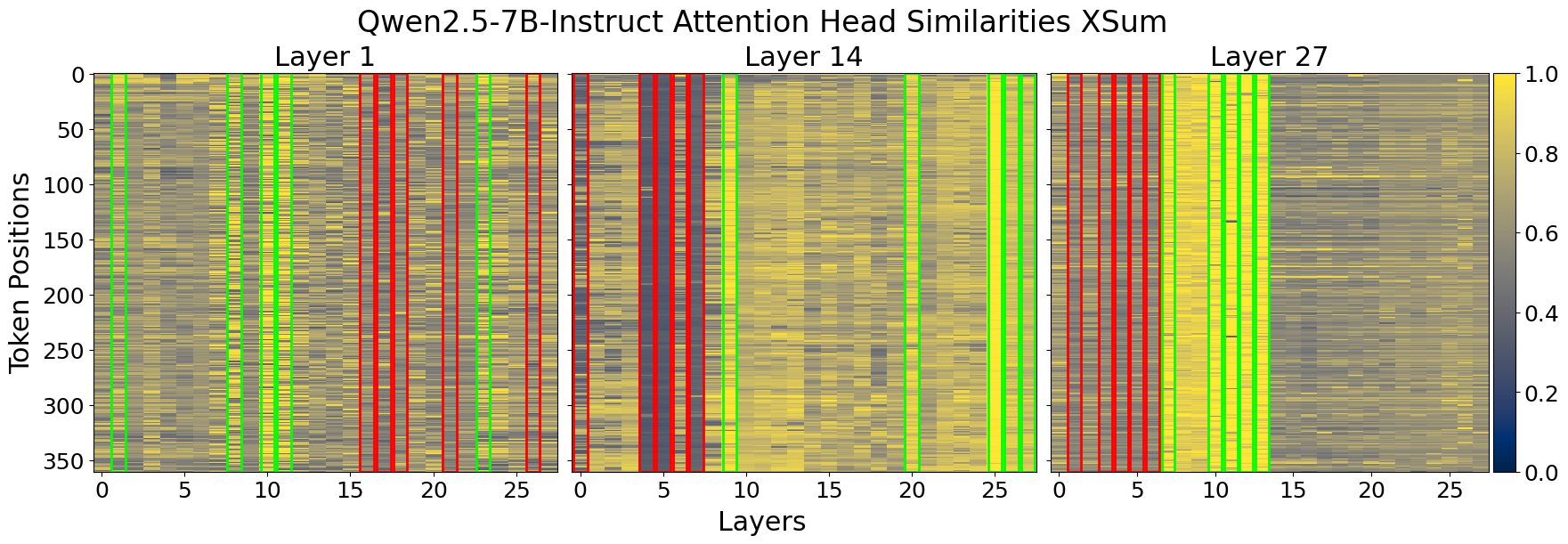
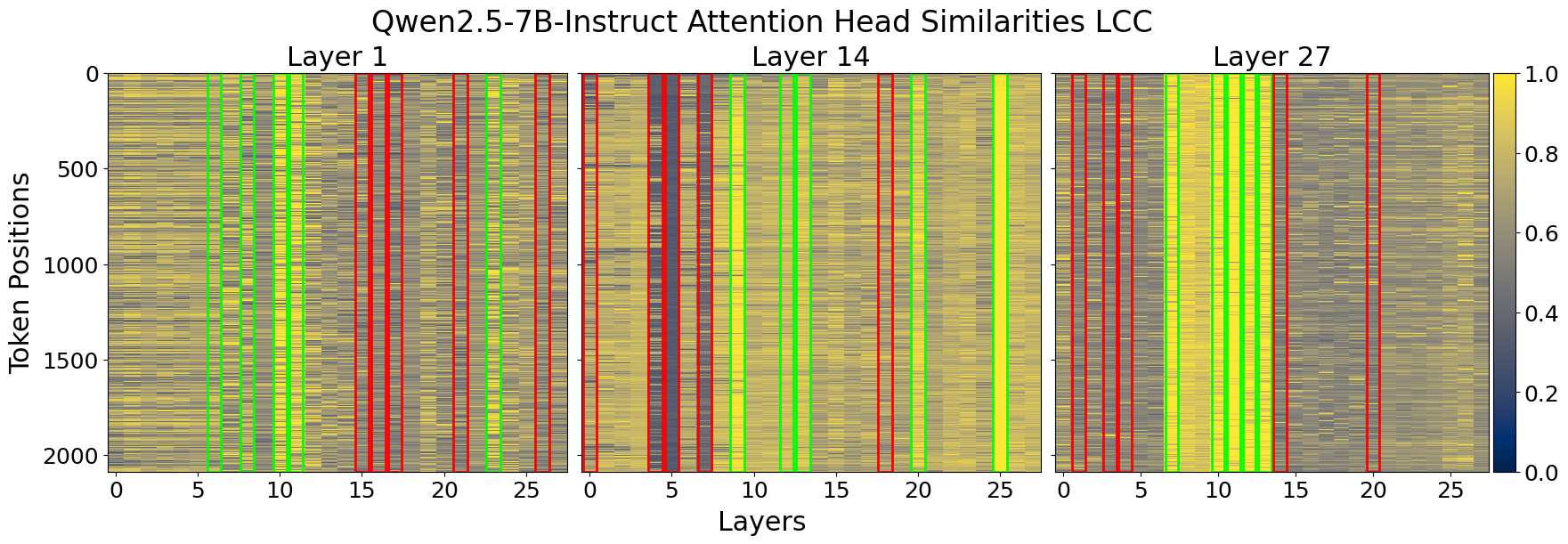
Figure 2: Cosine similarity heatmap for input and output of attention heads for two different prompts in LLaMA3-8B and Qwen2.5-7B. We chose three representative layers to illustrate that attention head consistency holds across different prompts. The X-axis shows the attention heads in a layer, Y-axis represents each token position in the prompt. Green and red outlines show the highest and lowest column similarity means per layer, that is, the most and least important attention heads respectively.
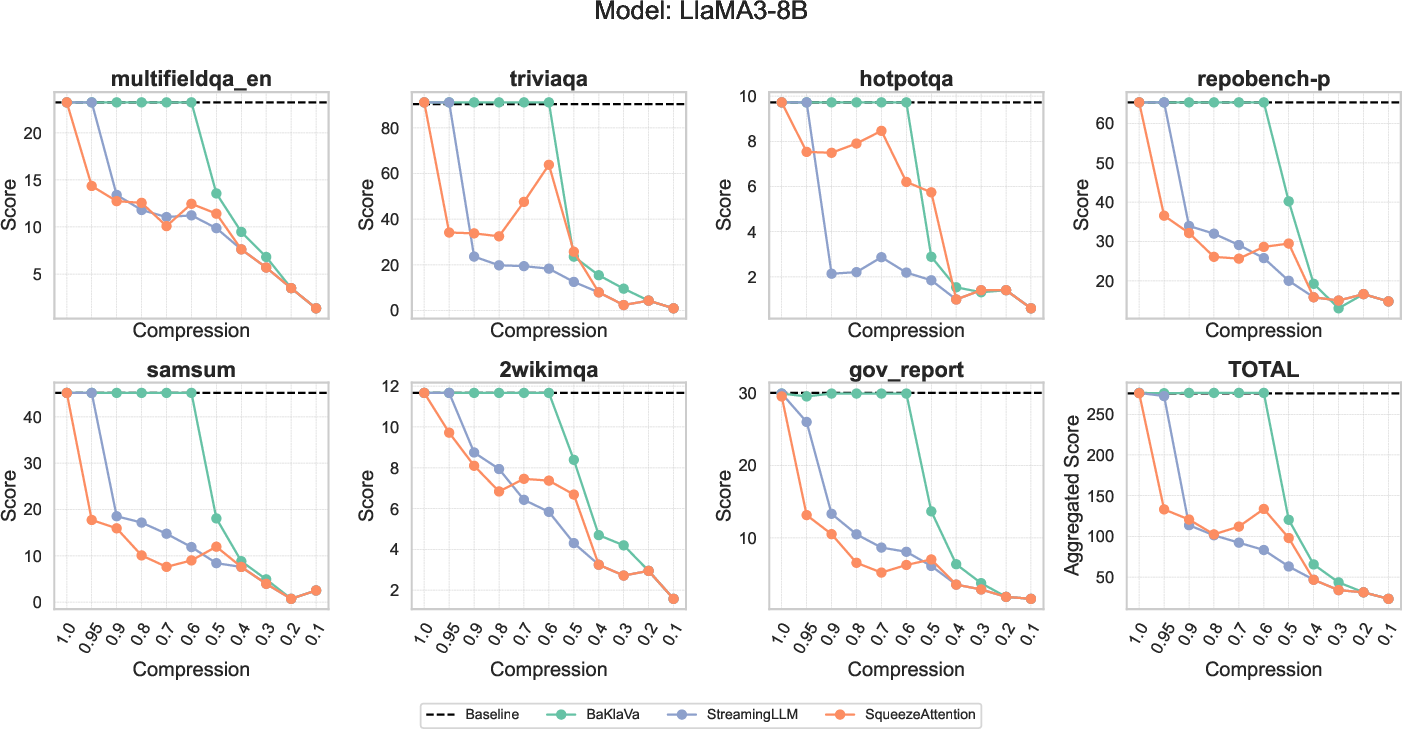
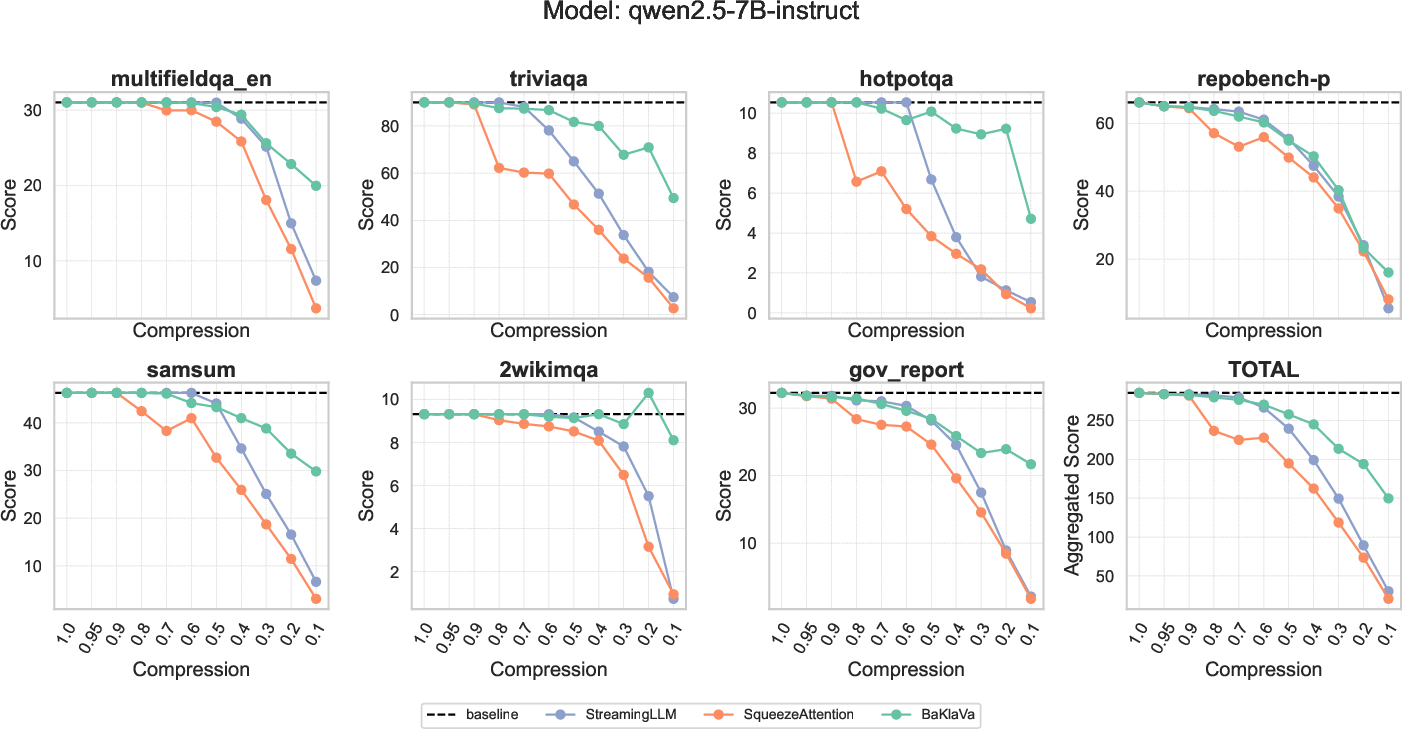
Figure 3: Comparison of BaKlaVa (varying memory budgets for both layers and KV-caches), SqueezeAttention (varying memory budgets for layers), and StreamingLLM (uniform memory budget for all KV-caches) on different LongBench tasks under various compression settings. The LongBench datasets shown include few-shot learning(triviaqa), coding (repobench-p), multi-document question answering (2wikimqa), and summarization (gov_report).
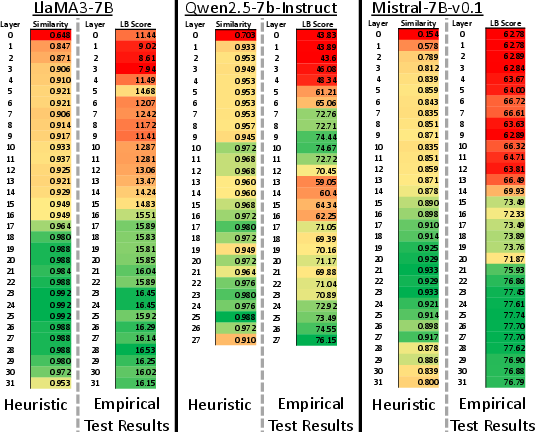
Figure 5: Comparison of layer importance heuristics with empirical evaluation results. Layers identified as least important by both heuristic and empirical test scores are highlighted in green, while critical layers are marked in red. LlaMA3-8B and Mistral-7B-v0.1 exhibit strong alignment between heuristic predictions and empirical findings, whereas Qwen2.5-7B shows significant discrepancies.

