- The paper introduces new datasets from Wikipedia and arXiv to evaluate LLM autoformalization into Isabelle/HOL.
- The paper finds that structured feedback improves LLM self-correction by up to 16% and reduces undefined errors by 43%.
- The study highlights ongoing challenges in semantic alignment, underscoring the need for enhanced contextual understanding in formal systems.
Introduction
The study investigates the capability of LLMs to perform autoformalization, transforming informal mathematical definitions into formal language. It specifically focuses on definitions collected from Wikipedia (Def_Wiki) and arXiv papers (Def_ArXiv), using Isabelle/HOL as the target formal language. The need to explore this task stems from the intricate nature of mathematical definitions, which often exceed the complexity found in extant benchmarks like miniF2F.
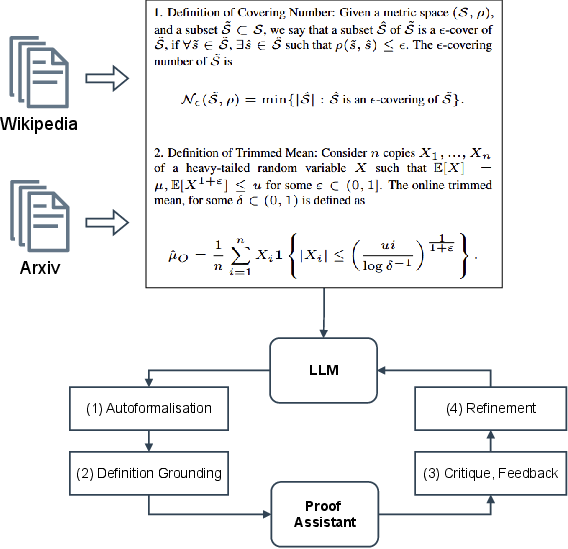
Figure 1: Can LLMs formalize complex mathematical statements? This paper investigates the task of translating real-world mathematical definitions into a formal language. We introduce a new resource collecting definitions from Wikipedia and ArXiv papers, exploring different strategies for autoformalization through the interaction between LLMs and Proof Assistants.
Methodology
The methodology employs a zero-shot evaluation setting with LLMs such as DeepSeekMath-7B, Llama3-8B, and GPT-4o, assessing their ability to translate definitions into Isabelle/HOL code. Key strategies for improving autoformalization include refinement through feedback from Proof Assistants and formal definition grounding—providing contextual elements from formal mathematical libraries.
Results
Findings indicate that complex definitions pose are more challenging to LLMs than existing benchmarks. Refining outputs through structured feedback significantly improves self-correction capabilities by up to 16%, while formal definition grounding reduces undefined errors by 43%.
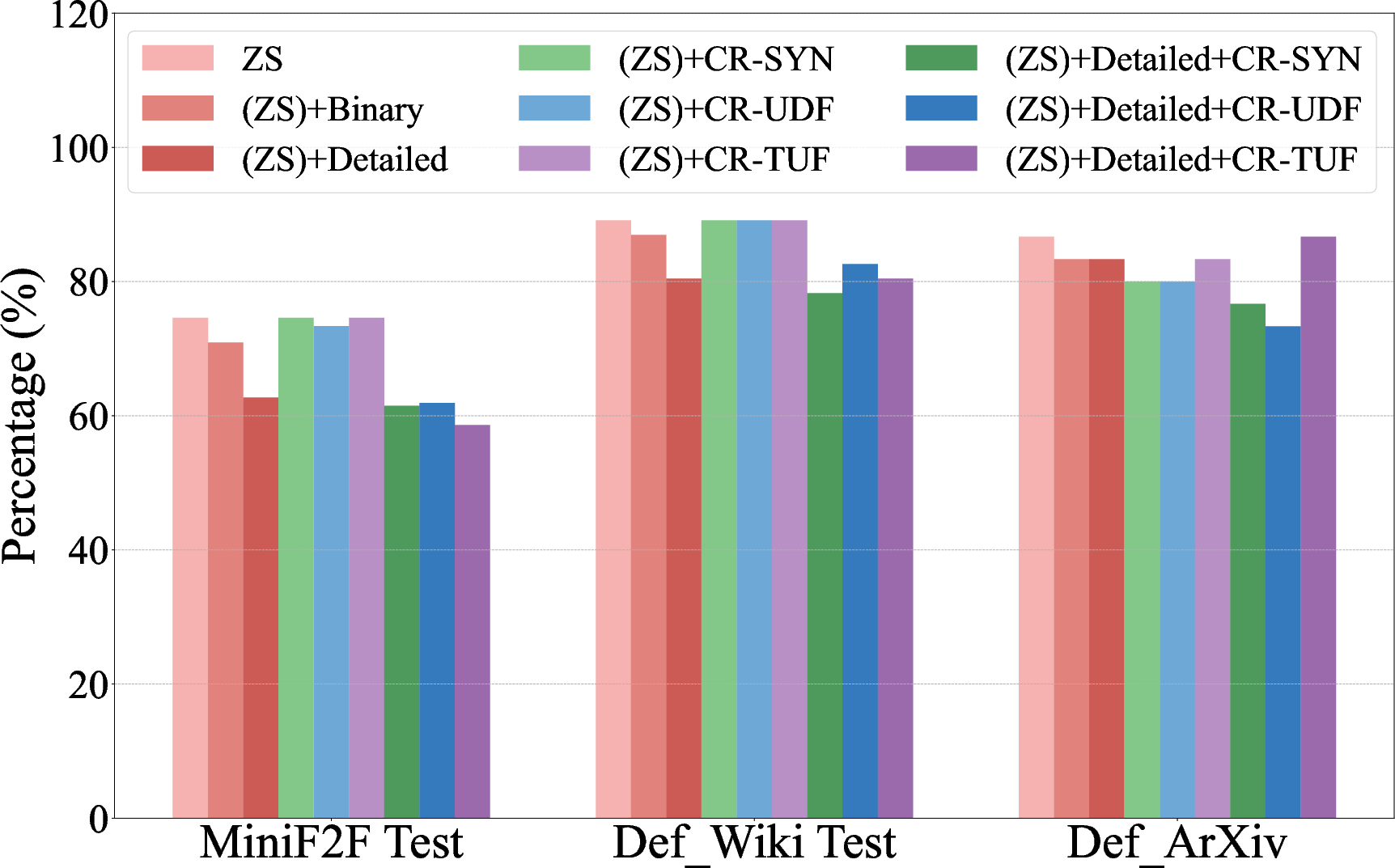
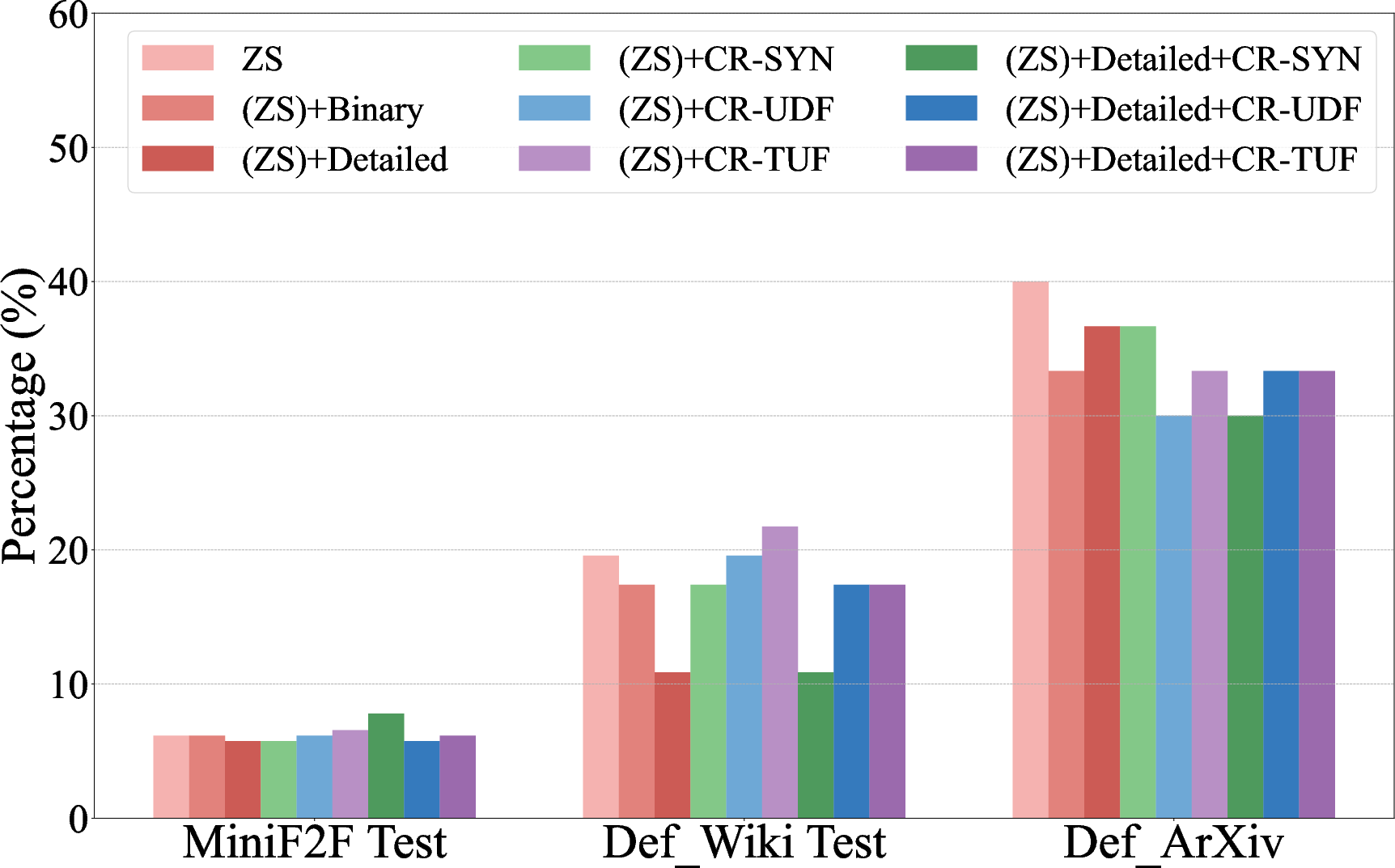
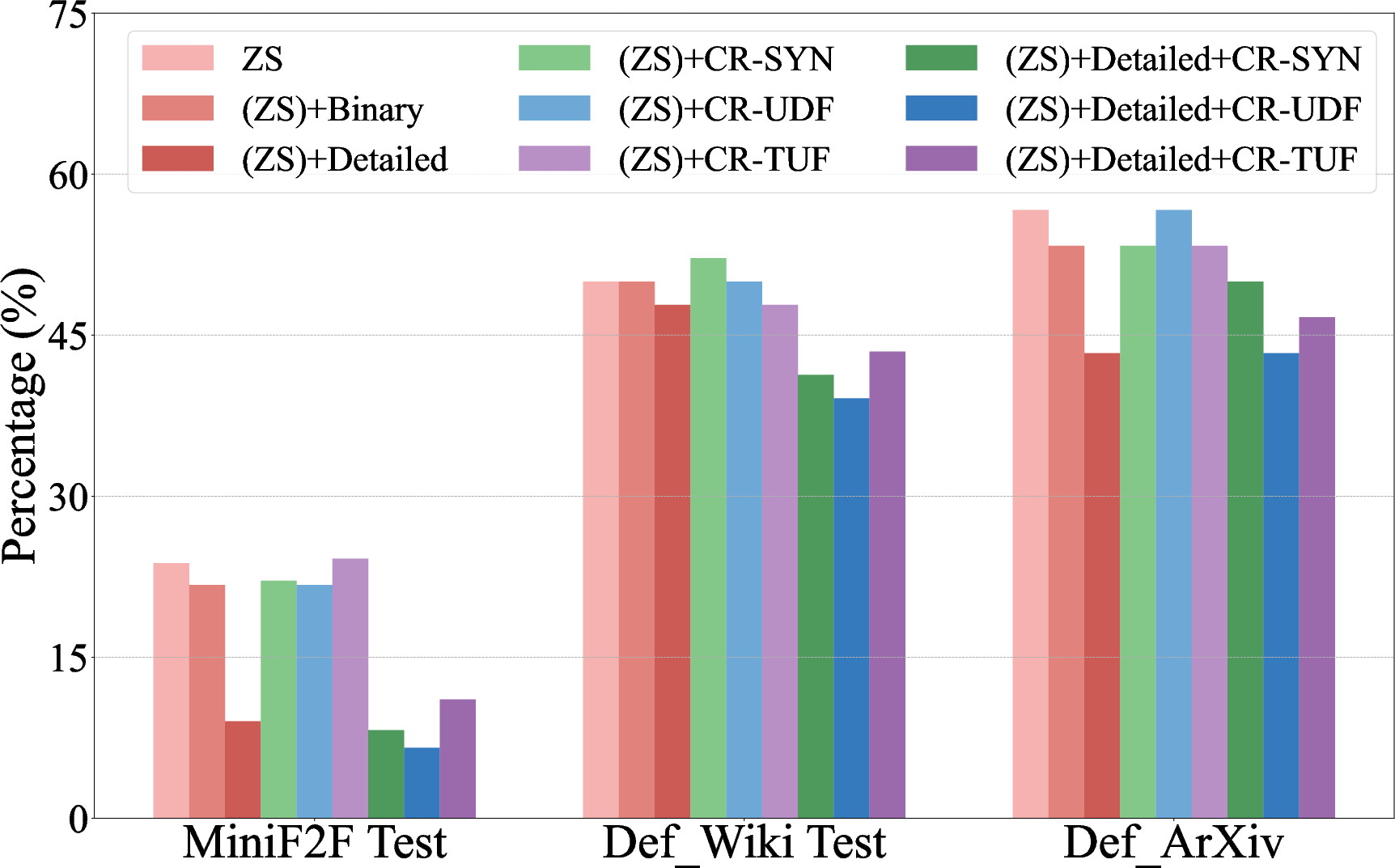
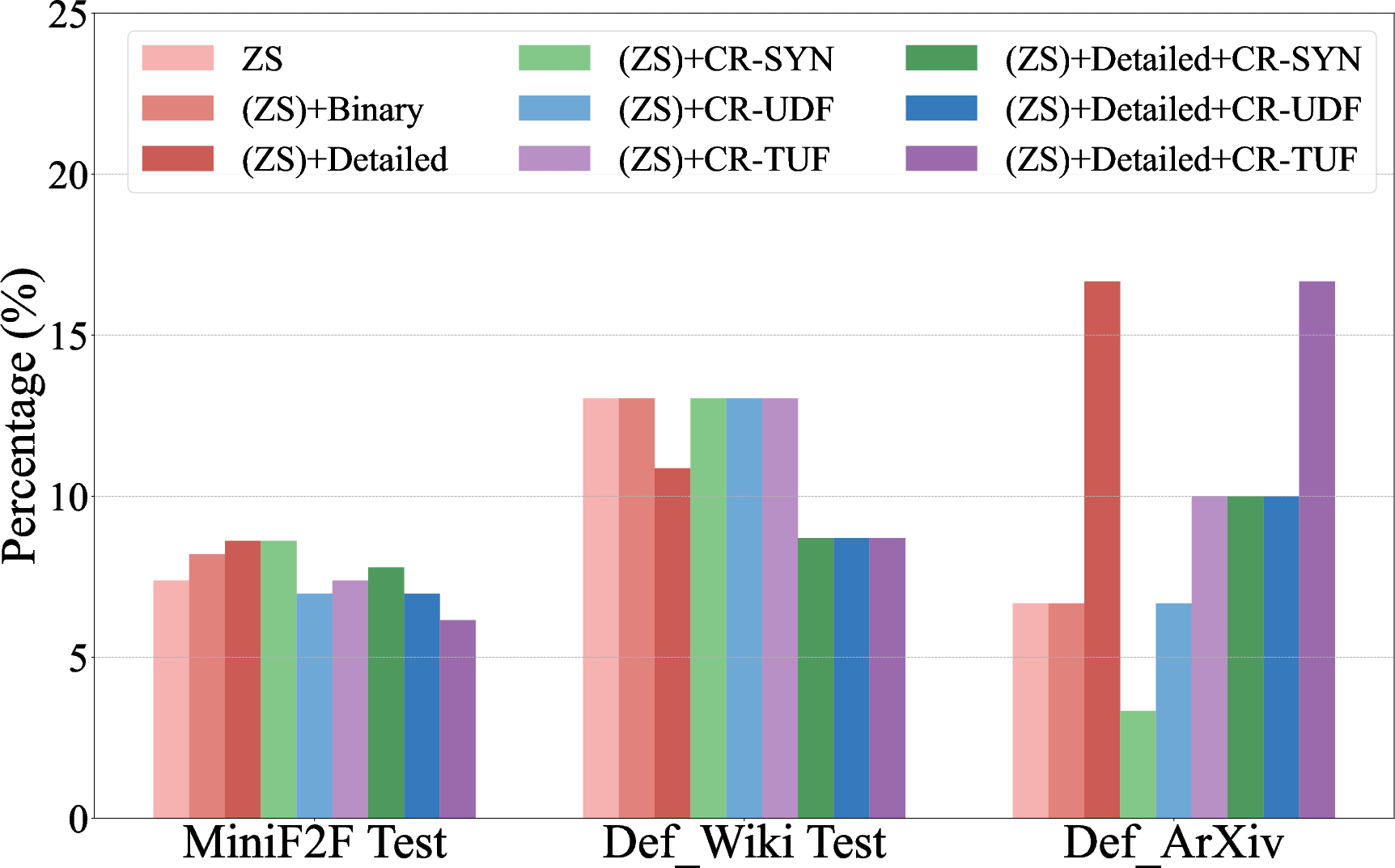
Figure 2: Overall error rate for LLM-generated formal codes across different refinement strategies, showing categorical improvements.
Empirical Evaluation
Error analysis reveals three primary failure modes: syntactic errors, undefined references, and type unification failures. Interventions such as categorical refinements target these errors, deploying specific instructions to guide LLMs in adhering to syntactic conventions and correctly referencing mathematical libraries. This approach markedly lowers error rates across tested datasets.
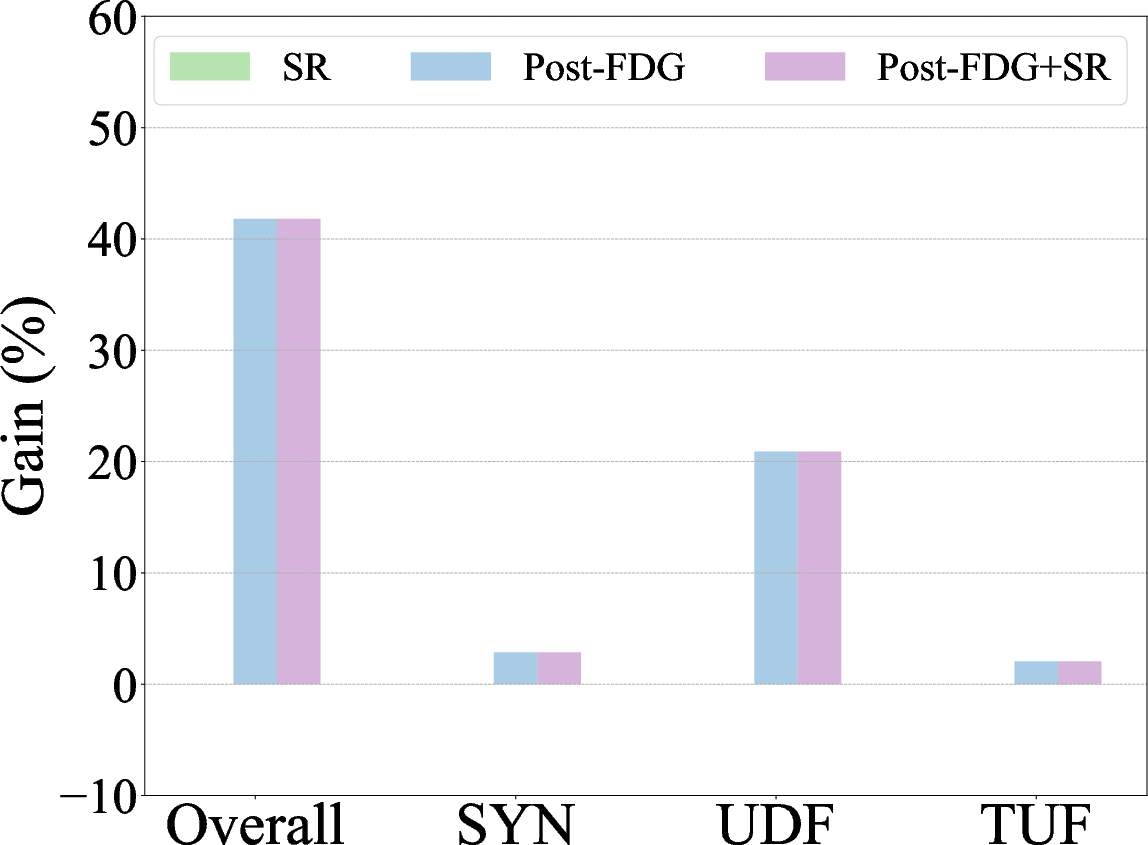
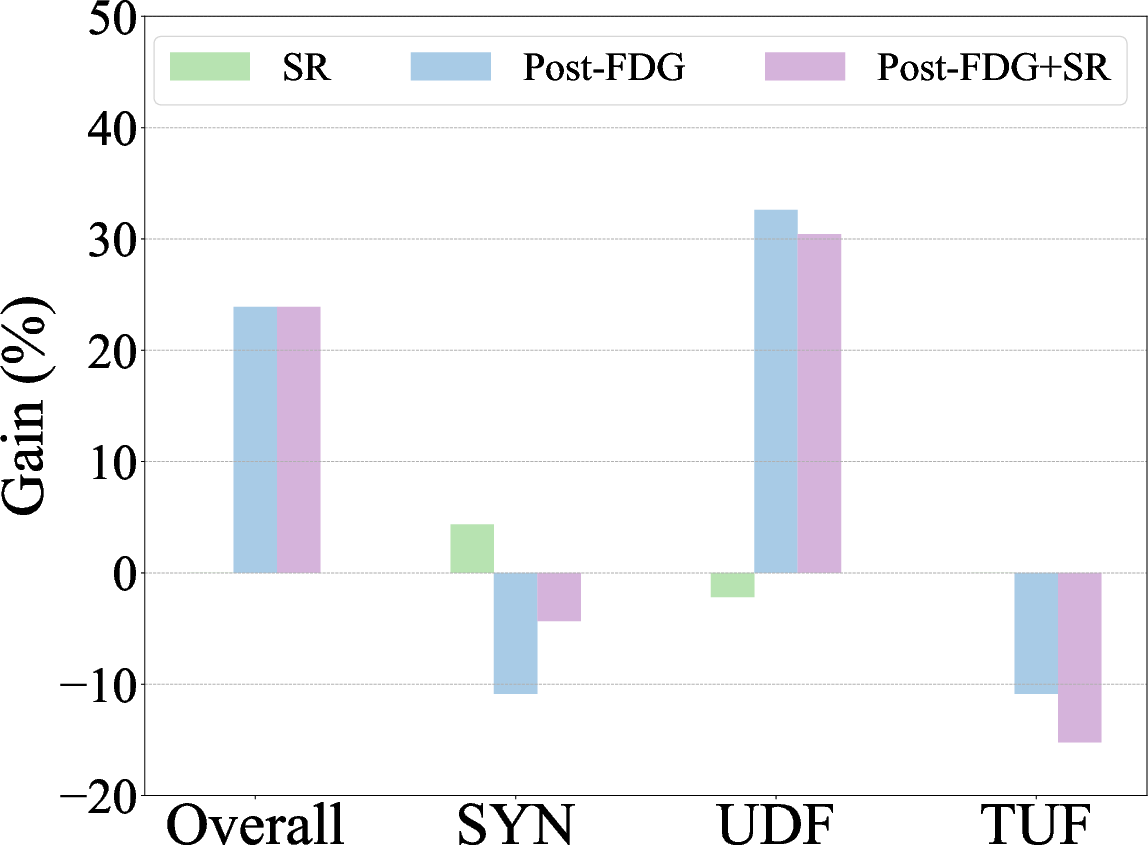
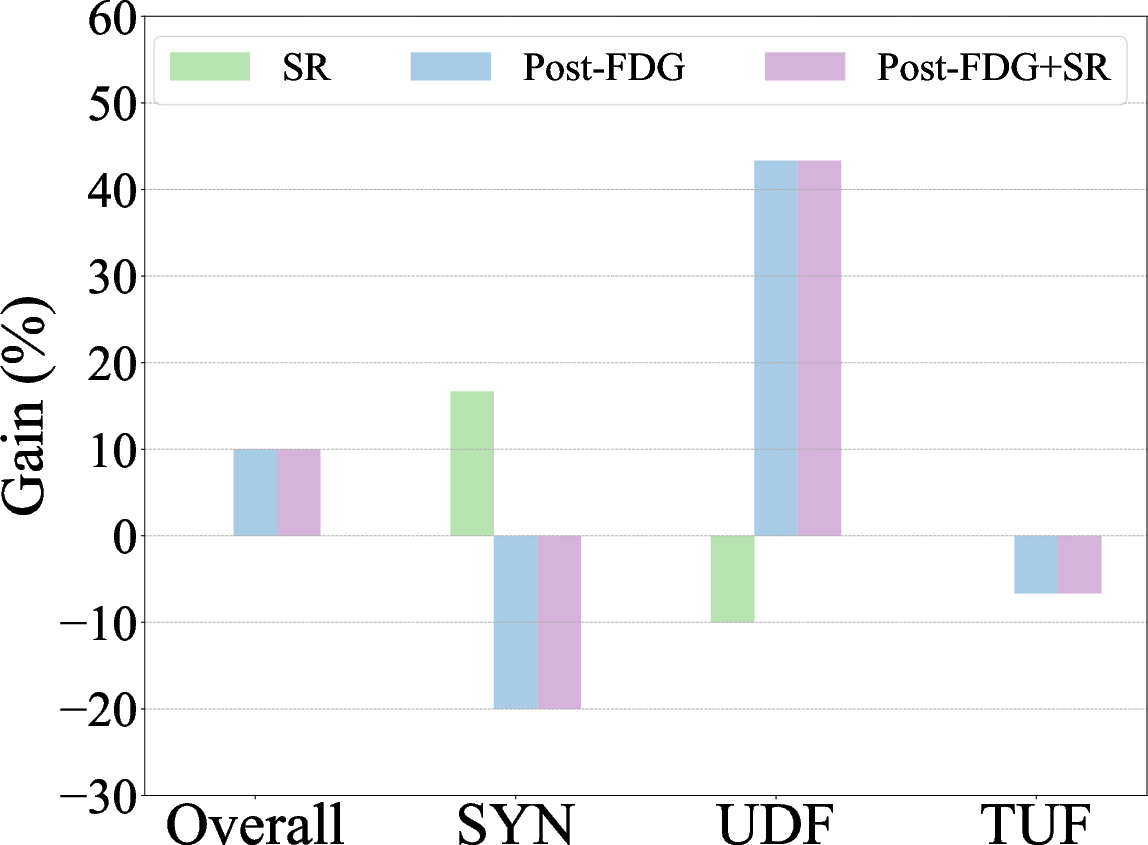
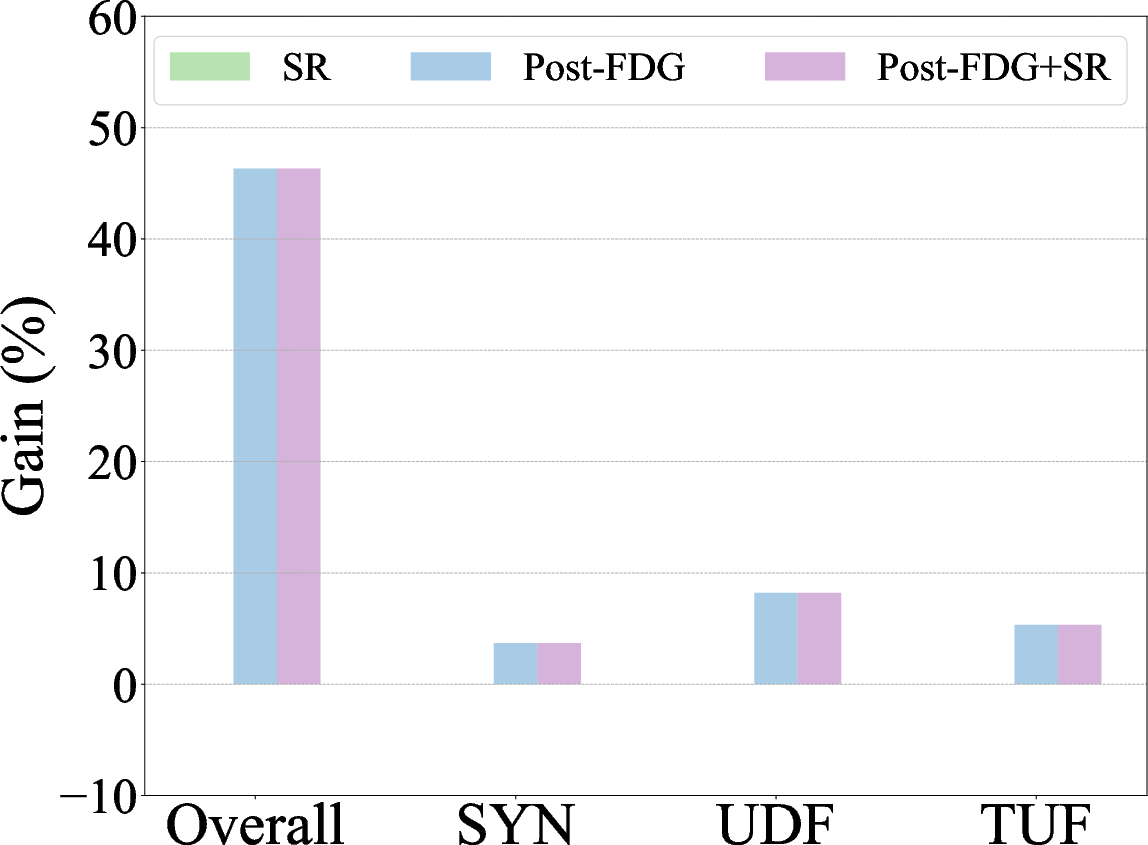
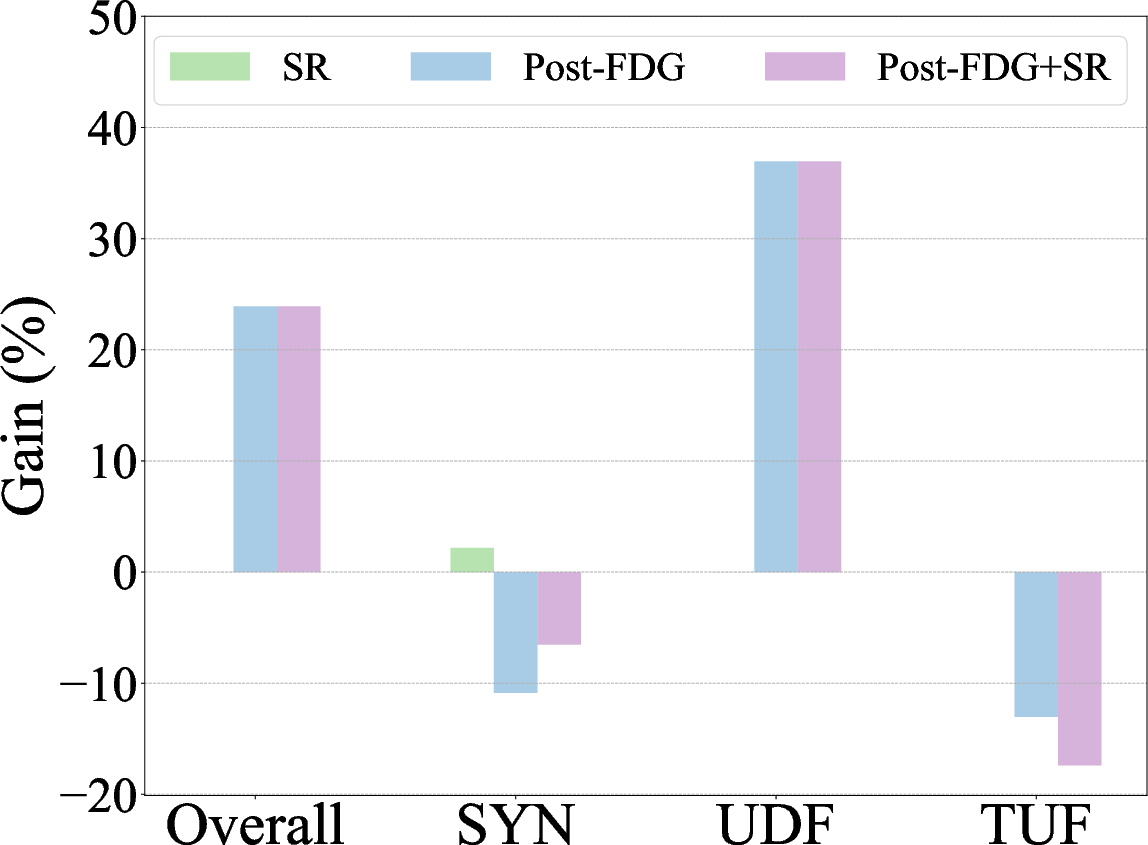
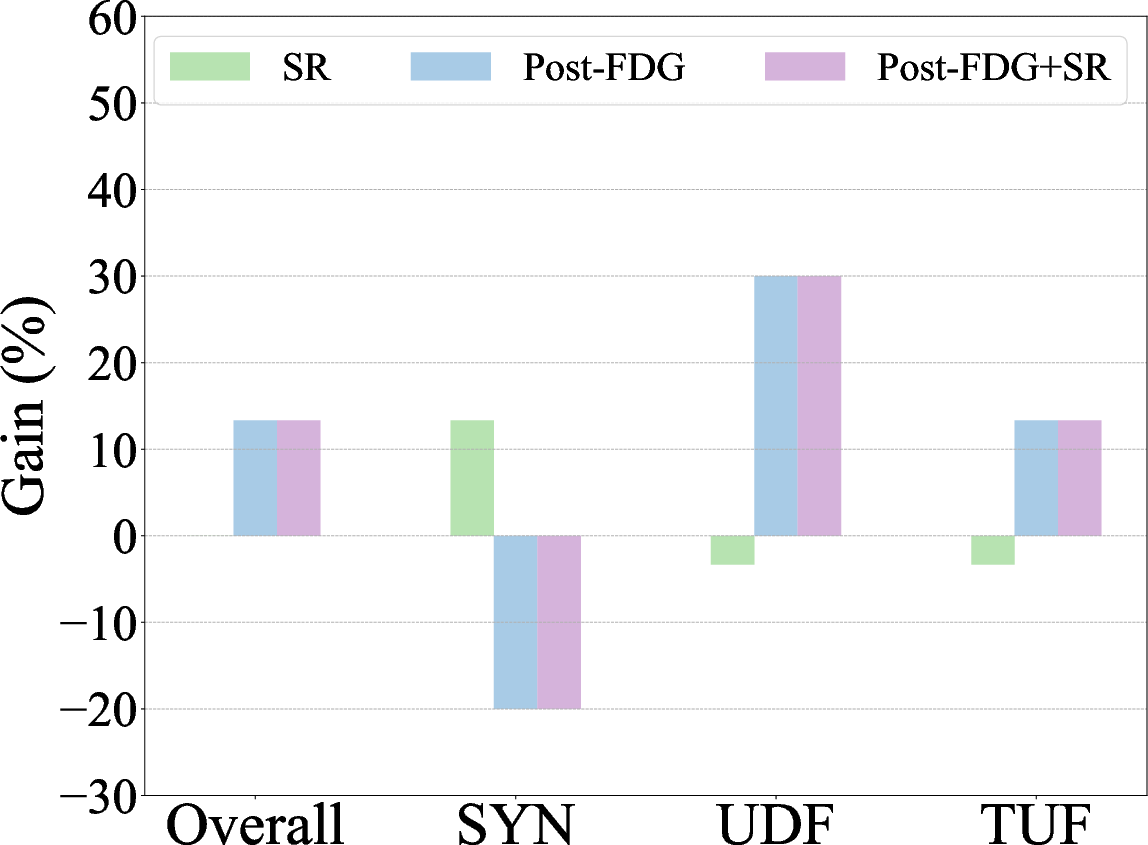
Figure 3: Zero-shot autoformalization performance on miniF2F, Def_Wiki, and Def_ArXiv, highlighting gains with symbolic refinement and post-processing with Formal Definition Grounding.
Discussion
While LLMs show promise in automatically formalizing mathematical definitions, challenges remain in fully training LLMs to use external libraries effectively. Refinement methods enhance performance but do not entirely resolve semantic integrity between natural language and formalized versions. Future directions include strengthening LLM self-correction capabilities and enhancing their contextual comprehension.
Conclusion
The paper's investigation into LLM-based autoformalization reveals the substantial complexity involved in formalizing real-world mathematical definitions, suggesting that sophisticated refinement strategies and grounding techniques are vital to improving accuracy and reliability in formalization tasks. Advanced methods must be developed to address semantic incongruencies and inspire more robust autoformalization systems.
Limitations
One limitation is that the study focuses exclusively on Isabelle/HOL, potentially limiting the generalizability of findings across other formal systems like Lean. The proposed datasets exhibit substantial diversity but remain small, necessitating further expansion. Finally, despite refinements enhancing syntactical correctness, achieving deep semantic alignment remains an open challenge in autoformalization.
(The figures referenced seamlessly integrate with the text, providing visual understanding of the empirical results.)

