- The paper presents a novel device-server collaborative system that improves TTFT and reduces costs by dynamically scheduling token generation for LLM-based text streaming.
- It employs a cost-aware dispatch controller and buffer-based migration framework to balance computational load and energy constraints.
- Evaluation shows up to 83.6% cost savings and consistent QoE improvements, demonstrating the effectiveness of dynamic endpoint migration strategies.
DiSCo: Device-Server Collaborative LLM-Based Text Streaming Services
The paper "DiSCo: Device-Server Collaborative LLM-Based Text Streaming Services" introduces a novel device-server cooperative scheduling system tailored to optimize the Quality of Experience (QoE) in text streaming services powered by LLMs. The primary objective is to address significant latency and cost challenges associated with serving millions of daily requests.
Introduction
LLMs have become integral to applications that require real-time interactions, such as chatbots and virtual assistants. A critical aspect of user satisfaction is QoE, which for interactive applications is quantified by Time-To-First-Token (TTFT) and Time-Between-Token (TBT). Meeting these demands necessitates deploying LLMs either on servers or on devices, each with its inherent limitations. Server-side deployments offer computational strength but suffer from variable latencies due to network dynamics, while on-device models benefit from dedicated resources but are constrained by energy consumption and processing speeds for complex tasks.
DiSCo serves as a middleware for dynamic scheduling between device and server for token generation, maintaining cost constraints without compromising user experience.
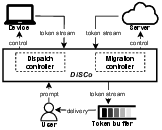
Figure 1: Acts as a middleware to optimize QoE by adaptively dispatching and migrating response generation between device and server endpoints under cost constraints.
Methodology
The central innovation of DiSCo lies in its cost-aware scheduling system and token-level migration framework. The system dynamically reroutes requests and switches the generation endpoint during live interactions to balance computational load and minimize costs. The scheduling leverages predictable device inference speeds and flexible server capabilities while mitigating last-hop issues and energy constraints.
Dispatch Control
DiSCo incorporates a dispatch controller that routes requests based on a cost-aware model distinguishing device-constrained and server-constrained scenarios. Under device constraints, a wait-time strategy ensures energy conservation while prioritizing latency protection. For server constraints, the system employs a length-threshold strategy for routing, conserving server resources by managing prompt lengths.
Migration Framework
For token migration between endpoints, DiSCo provides a buffer-based protocol to ensure seamless token delivery even when shifting the token generation process. This methodology prevents quality degradation during endpoint transitions, maintaining streaming consistency and responsiveness.

Figure 2: Token generation migration between endpoints. Row A shows the original sequence on the source endpoint, while Row B shows the sequence after migration to the target endpoint, maintaining consistent token delivery while reducing cost.
Evaluation
DiSCo's performance was rigorously evaluated against contemporary LLM services across various deployment scenarios. The results demonstrated significant improvements in TTFT and comparable TBT scores, with up to an 83.6% reduction in operational costs without sacrificing QoE.
TTFT and Cost Benefits
The evaluation highlighted DiSCo's exceptional ability to improve TTFT across different model configurations and budget scenarios. Even at strict resource constraints, DiSCo's dispatch and migration protocols effectively reduced latency spikes and maintained operational efficiency.
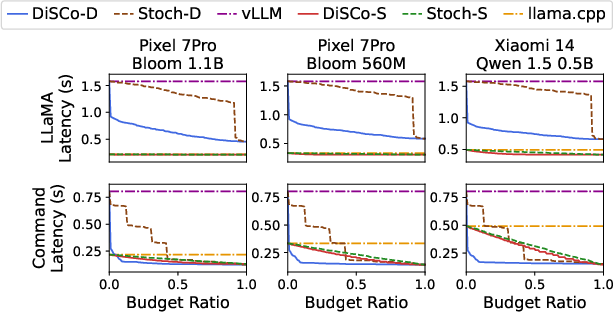
Figure 3: Mean TTFT reduction remains significant on DiffusionDB trace.
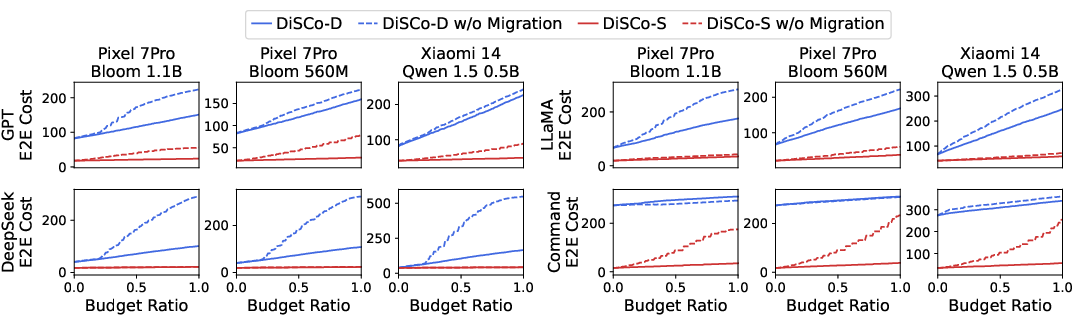
Figure 4: The migration mechanism achieves superior end-to-end cost savings.
Results and Discussion
DiSCo effectively demonstrates that device-server collaboration can reap substantial benefits by logically balancing computational tasks between on-device and server-side processing. Its innovative approach to token-level migration during active session generation illustrates powerful means to conserve resources while ensuring impactful QoE delivery.
Conclusion
The research surrounding DiSCo illustrates a significant stride in improving text streaming services supported by LLMs. By harmonizing server-deployment strengths and device-specific advantages, it paves the way for intelligent scheduling models that dynamically respond to cost and latency pressures, ensuring users experience smooth, real-time interactions without unwarranted computational expenses.
In summary, DiSCo's strategic middleware solutions exemplify how judicious scheduling and migration protocols can bolster LLM service efficiency, heralding a path for further enhancements in device-server cooperative frameworks. Future research may explore extending its paradigms to multi-device deployment scenarios, addressing energy modeling complexities, and enhancing adaptive capabilities amidst evolving hardware architectures.