- The paper demonstrates a three-step paradigm that pre-trains a Large User Model to capture user interests and collaborative signals effectively.
- The approach integrates generative pre-training with discriminative DLRMs, yielding improved AUC, recall, and scalability in industrial settings.
- The study identifies power-law scaling trends, confirming that as model parameters and sequence length increase, performance continues to improve.
Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model
This paper introduces a large user model (LUM) that incorporates a novel three-step paradigm aimed at addressing limitations in existing recommendation systems (RecSys) by leveraging scalability principles observed in LLMs. The research demonstrates superior performance of LUM over both DLRMs and end-to-end generative recommendation approaches, particularly when scaling up to 7 billion parameters and deploying in an industrial application context.
Introduction
Traditionally, deep learning-based recommendation models (DLRMs) have struggled to scale efficiently compared to the notable scalability observed in LLMs. The discrepancy between generative models and discriminative models is at the core of this challenge. Whereas generative models capture the joint probability distribution, discriminative models focus on simpler conditional probabilities, limiting the advantages of increased computational resources. The paper observes various limitations of end-to-end generative recommendation methods (E2E-GRs), such as inconsistencies between training and application, efficiency challenges, lack of flexibility, and limited compatibility with industrial settings.
Inconsistency: Generative models focus on data generation rather than precise predictive outcomes, which can be problematic for application tasks such as click-through rate prediction.
Efficiency: Industrial applications demand efficient training with continuous streaming data and low-latency inference, which E2E-GRs struggle to meet.
Flexibility and Compatibility: E2E-GRs are rigid and incompatible with pre-existing industrial knowledge and explicit feature engineering from traditional models.
To tackle these limitations, the paper proposes a three-step paradigm for training a Large User Model (LUM):
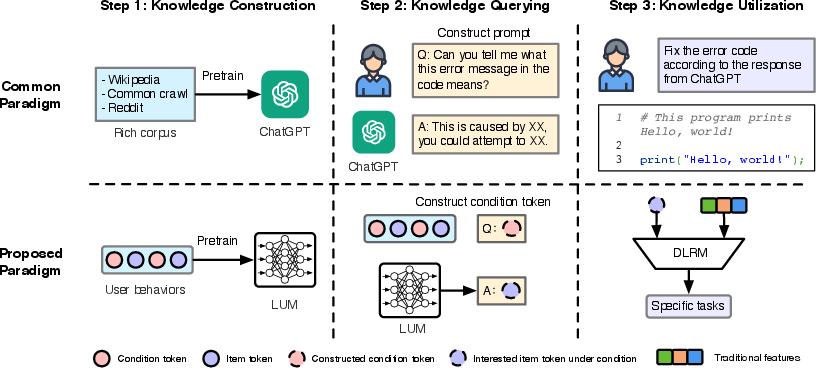
Figure 1: Intuitive insight from the common paradigm in using LLM to the proposed multi-step, generative-to-discriminative paradigm.
- Knowledge Construction: Utilizing transformer architecture, LUM is pre-trained through generative learning to capture user interests and collaborative relationships among items.
- Knowledge Querying: LUM is queried with user-specific information, which involves extracting insights using a concept akin to "prompt engineering."
- Knowledge Utilization: Outputs from LUM enrich traditional DLRMs, enhancing their predictive accuracy and decision-making capabilities.
Method
Step 1: Knowledge Construction via Pre-training LUM
Tokenization: A novel tokenization strategy is implemented where each item is expanded into a condition token and an item token. This approach is crucial for capturing user behavior across varied conditions.
Architecture: The hierarchical structure of LUM includes a Token Encoder for integrating heterogeneous input features and a User Encoder, utilizing an autoregressive transformer architecture for comprehensive sequence processing.
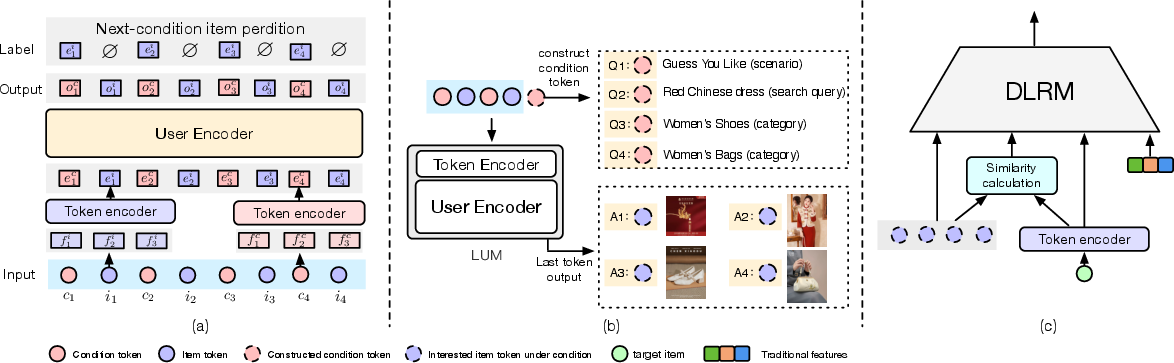
Figure 2 (a): The architecture of LUM. (b) An example of query knowledge from pre-trained LUM. (c) An example of utilizing knowledge in DLRMs.
Next-condition-item Prediction: To handle high vocabulary size, the paper uses the InfoNCE loss and introduces a packing strategy optimizing sequence processing efficiency.
Step 2: Knowledge Querying with Given Conditions
LUM's architecture supports multi-condition querying, setting the stage for discriminative tasks. The tokenization method allows triggering user-specific insights, further documented through empirical evaluations.
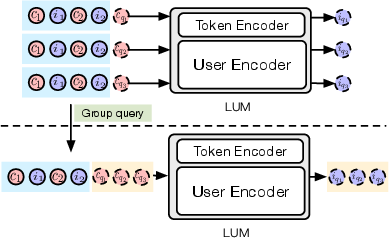
Figure 3: An example of group query.
Step 3: Knowledge Utilization in DLRMs
Knowledge extracted from LUM is integrated into DLRMs, either directly as fixed additional features or through interest matching via similarity measurement.
Experiments
Public Datasets: Evaluations on multiple datasets show that LUM consistently offers superior performance compared to established methods, validating the effectiveness of the three-step paradigm.
Industrial Setting: In real-world industrial applications, LUM achieves significant improvement in AUC and recall metrics, demonstrating its applicability in large-scale environments.
Effectiveness Evaluation
Impact on DLRMs: The paper assesses various DLRMs integrated with LUM, noting consistent improvements in predictive accuracy.
Tokenization and Utilization Strategies: Various strategies outlined, including tokenization and knowledge utilization, are shown to impact performance significantly.
Efficiency Evaluation
The study highlights the efficiency of training and serving processes using LUM, emphasizing scalability advantages and reduced computational costs compared to E2E-GRs.
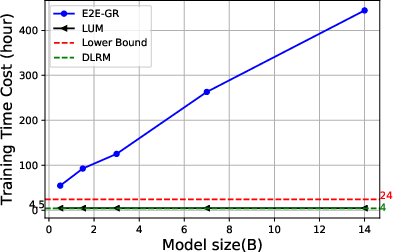
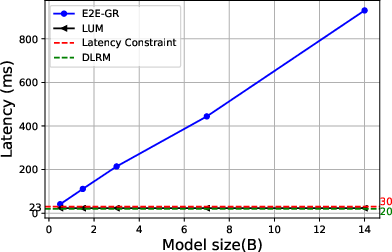
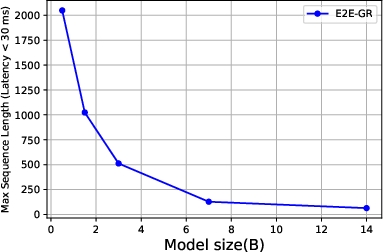
Figure 4: The Results of Efficiency Evaluation.
Scaling Law for LUM
The research identifies power-law scaling trends with model size and sequence length, demonstrating the potential for continuous performance improvements as LUM scales.
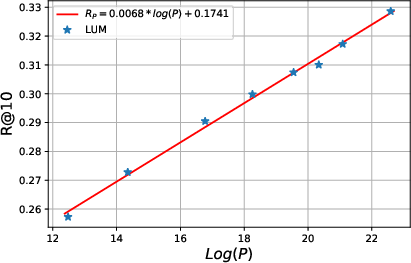
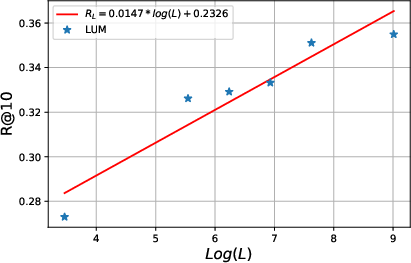
Figure 5: Scaling law for LUM.
Conclusion
This paper presents a comprehensive framework that successfully leverages generative models to unlock scalability in recommendation systems. The proposed method addresses critical challenges in industrial applications, offering robust integration and flexibility. Experiments validate the practicality of LUM, ensuring its scalability and efficiency, thus enhancing user engagement and business outcomes.

